Spring Reactive Microservices: A Showcase
A road-map to developing Reactive Microservices in Spring. We combine material from various official and 3rd party sources and our personal experience.
Join the DZone community and get the full member experience.
Join For FreeIntroduction and Scope
The Servlet Specification was built with the blocking semantics or one-request-per-thread model. Usually, in a cloud environment, the machines are smaller than traditional data centers. Instead of a big machine, it is popular to use many small machines and try to scale applications horizontally. In this scenario, the servlet spec can be switched to an architecture created upon Reactive Streams. This kind of architecture fits better than servlet for the cloud environments. Spring Framework has been creating the Spring WebFlux to helps developers to create Reactive Web Applications [1].
Spring WebFlux, which is based on Project Reactor, allows us to:
- move from blocking to non-blocking code and do more work with fewer resources
- increase potential to handle massive numbers of concurrent connections
- satisfy more concurrent users with fewer microservice instances
- apply back-pressure and ensure better resilience between decoupled components
In our demo project we will center around the reactive WebClient component making calls to remote services. This is actually a good starting point and a pretty common case. As stated in [2], the greater the latency per call or the inter-dependency among calls, the more dramatic the performance benefits are.
An extra motivation for this approach is the fact that since Spring version 5.0, the org.springframework.web.client.RestTemplate class is in maintenance mode, with only minor requests for changes and bugs to be accepted going forward. Therefore, it is advised to start using the org.springframework.web.reactive.client.WebClient which has a more modern API. Moreover, it supports sync, async, and streaming scenarios.
We will build a sample application based on a minimal Microservices architecture and demonstrate several capabilities driven by the requirements of each use-case. Apart from Java understanding, a familiarity with Spring Cloud project is required, basic knowledge of Project Reactor (what is a Mono, what is a Flux) and the basics of Spring WebClient.
We will follow a business problem-solution approach to make things more realistic. Although we do not intend all reactive APIs, it should be enough to give you a good idea of what lies ahead if you are about to enter this domain and the different mentality required. And this is something that simple "hello-world" examples with Mono & Flux cannot simply capture.
Reactive programming is trending at the moment but trivial "hello-world" examples with Mono & Flux cannot simply capture the demands of building 12-factor apps for production usage. You will need much more than this if you are to make a decision for real-world production systems
With the reactive WebClient we can return reactive types (e.g. Flux or Mono) directly from Spring MVC controller methods. Spring MVC controllers can call other reactive components too. A mix is also possible in case we have some endpoints and services which cannot become reactive for a number of reasons such as: blocking dependencies with no reactive alternatives or we may have an existing legacy app which we want to migrate gradually etc. In our case we will follow the Annotated Controllers programming model.
Scenario / Project Structure
We are going to implement a simplified One Time Password (OTP) service, offering the following capabilities:
- Generate OTP
- Validate (use) OTP
- Resend OTP
- Get OTP status
- Get all OTPs of a given number
Our application will consist of the following microservices:
- otp-service: which will provide the functionality above by orchestrating calls to local and remote services
- customer-service: will keep a catalog of registered users to our service with information like account id, MSISDN, e-mail etc.
A number of remote (external) services will be invoked. We assume that our application is authorized to use them will access them via their REST API. Of course, these will be mocked for simplicity. These "3rd-party" services are:
- number-information: takes a phone number as input and verifies that it belongs to a Telecoms operator and is currently active
- notification-service: delivers the generated OTPs to the designated number or channel (phone, e-mail, messenger etc.)
In order to simulate a microservices setup, we will use Spring Cloud with HashiCorp Consul for service discovery and Spring Cloud Gateway. There is no particular reason for not going with Eureka, just have in mind that Consul can play the role of a centralized configuration server as well while with Eureka only we need to have a separate Spring Cloud Config server.
We choose Spring Cloud Gateway instead of Zuul for the following reasons:
- Spring Cloud Gateway is reactive by nature and runs on Netty
- Spring Team has moved most of Spring Cloud Netflix components (Ribbon, Hystrix, Zuul) into maintenance mode
- Spring Team does not intend to port-in Zuul 2 which is also reactive in contrast to Zuul 1
We will go with Spring Cloud Loadbalancer (instead of Ribbon) for client-side load balancing and with @LoadBalanced WebClient (instead of Feign) for service-to-service communication. Apart from this, each microservice will be based on Spring Boot. We will also bring Spring Data R2DBC into play to integrate with a PostgreSQL database using a reactive driver. A diagram of our components is shown below:
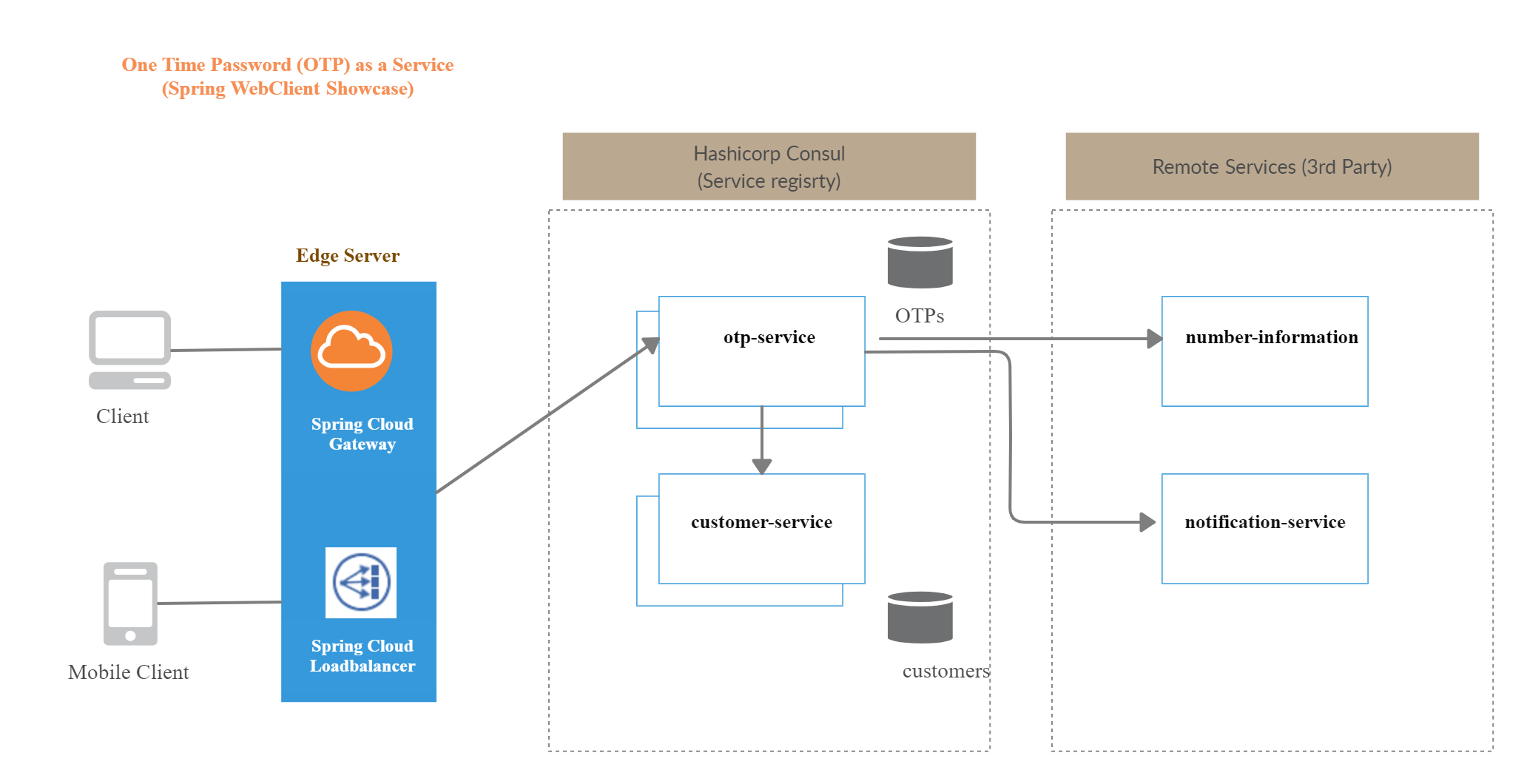
The full source code can be inspected at https://github.com/kmandalas/webclient-showcase.
I. Generate OTP
Business Requirement
Given the number of a user in E.164 format:
- fetch customer data from customer-service and in parallel validate the number status using the number-information service
- produce an OTP pin and save it in the DB
- invoke the notification-service to deliver it
- return response
Solution
You can see the full implementation here
// 1st call to customer-service using @LoadBalanced WebClient
Mono<CustomerDTO> customerInfo = loadbalanced.build()
.get()
.uri(customerURI)
.header("Authorization", String.format("%s %s", "Bearer", tokenUtils.getAccessToken()))
.accept(MediaType.APPLICATION_JSON)
.retrieve()
.onStatus(HttpStatus::is4xxClientError,
clientResponse -> Mono.error(new OTPException("Error retrieving Customer", FaultReason.CUSTOMER_ERROR)))
.bodyToMono(CustomerDTO.class);
// 2nd call to external service, to check that the MSISDN is valid
Mono<String> msisdnStatus = webclient.build()
.get()
.uri(numberInfoURI)
.retrieve()
.onStatus(HttpStatus::isError, clientResponse -> Mono.error(
new OTPException("Error retrieving msisdn status", FaultReason.NUMBER_INFORMATION_ERROR)))
.bodyToMono(String.class);
// Combine the results in a single Mono, that completes when both calls have returned.
// If an error occurs in one of the Monos, execution stops immediately.
// If we want to delay errors and execute all Monos, then we can use zipDelayError instead
Mono<Tuple2<CustomerDTO, String>> zippedCalls = Mono.zip(customerInfo, msisdnStatus);
// Perform additional actions after the combined mono has returned
return zippedCalls.flatMap(resultTuple -> {
// After the calls have completed, generate a random pin
int pin = 100000 + new Random().nextInt(900000);
// Save the OTP to local DB, in a reactive manner
Mono<OTP> otpMono = otpRepository.save(OTP.builder()
.customerId(resultTuple.getT1().getAccountId())
.msisdn(form.getMsisdn())
.pin(pin)
.createdOn(ZonedDateTime.now())
.expires(ZonedDateTime.now().plus(Duration.ofMinutes(1)))
.status(OTPStatus.ACTIVE)
.applicationId("PPR")
.attemptCount(0)
.build());
// External notification service invocation
Mono<NotificationResultDTO> notificationResultDTOMono = webclient.build()
.post()
.uri(notificationServiceUrl)
.accept(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(NotificationRequestForm.builder()
.channel(Channel.AUTO.name())
.destination(form.getMsisdn())
.message(String.valueOf(pin))
.build()))
.retrieve()
.bodyToMono(NotificationResultDTO.class);
// When this operation is complete, the external notification service
// will be invoked. The results are combined in a single Mono:
return otpMono.zipWhen(otp -> notificationResultDTOMono)
// Return only the result of the first call (DB)
.map(Tuple2::getT1);
});
First of all, we see that we need to communicate with 1 internal microservice (service-to-service communication) and with 2 external (remote) services.
As already mentioned, we choose to go with @LoadBalanced WebClient. Therefore, we need to have a loadbalancer implementation in the classpath. In our case, we have added the spring-cloud loadbalancer dependency to the project. This way, a ReactiveLoadBalancer will be used under the hood.
Alternatively, this functionality could also work with spring-cloud-starter-netflix-ribbon, but the request would then be handled by a non-reactive LoadBalancerClient. Plus, like we said, Ribbon is already in maintenance mode, so it is not recommended for new projects [3].
One more thing we need, is to disable Ribbon in the application properties of our services:
xxxxxxxxxx
spring
loadbalancer
ribbon
enabledfalse
Finally a note about Feign which was a quite popular choice till now along with Ribbon: the OpenFeign project does not currently support reactive clients, neither does Spring Cloud OpenFeign. Therefore, we will not use it. For more details check here.
Now, here are a couple of practical issues that one may face with real-world applications:
- the need for Multiple WebClient Objects.
- to propagate a JWT token in case we have our various endpoints protected.
To deal with the 1st issue, we will declare 2 different WebClient Beans inside our WebClientConfig class. This is necessary since service-discovery and load-balancing is only applicable to our own domain and services. Therefore, we need to use different instances of WebClient Beans which of course may have additional differences in configuration (e.g. timeouts) than the @LoadBalanced annotation.
For the 2nd issue we need to propagate the access token within the header attribute of the WebClient:
xxxxxxxxxx
.header("Authorization", String.format("%s %s", "Bearer", tokenUtils.getAccessToken()))
In the snippet above, we assume we have a utility method that gets a JWT token from the incoming request forwarded via Spring Cloud Gateway to the otp-service. We use this in order to set the "Authorization" header attribute with the value of the Bearer token effectively passing it on to the customer-service. Keep in mind that the following settings are also needed in the application.yml of the gateway-service in order to allow this relay:
xxxxxxxxxx
globalcors
cors-configurations'[/**]'
allowedOrigins"*"
allowedMethods"POST""GET""DELETE""PUT"
allowedHeaders"*"
allowCredentialstrue
Now that we have these sorted out, let's see which Reactor Publisher functions we can use to get the result:
- In order to make parallel calls to different endpoints we will use Mono's zip method. In general, the zip method and its variants return Tuple objects. These special objects allow us to combine the results of the calls. In our case we get a
Tuple2<CustomerDTO, String>. If an error occurs in one of the Monos, the execution stops immediately. If we want to delay errors and execute all Monos, then we can use zipDelayError instead. - When these parallel calls complete, in order to process the results, chain subsequent actions and return a response, we will use the flatMap method.
- Inside the transformer Function of the flatMap, we generate a random PIN and we persist in in the DB using a
ReactiveCrudRepository - We use the zipWhen method to trigger the notification-service only after the DB interaction has finished.
- Finally, we use map method to select our return value which in our case is the data object that was previously saved in the DB.
For a full list of options you may check the Mono API.
II. Validate OTP
Business Requirement
Given an existing OTP id and a valid pin previously delivered to user's device:
- fetch the corresponding OTP record from the DB by querying "otp" table by id
- if found, fetch information of maximum attempts allowed from configuration table "application", otherwise return error
- perform validations: check if maximum attempts exceeded, check for matching pin, if OTP has expired etc.
- if validation checks fail, then return error, otherwise update the OTP status to VERIFIED and return success
- in case of error we need to finally save the updated counter of maximum attempts and OTP status back to the database
We assume here that we can have OTPs associated with applications and we can have different time-to-live periods, different number of maximum attempts allowed etc. We keep these configuration data in a second DB table named "application".
Solution
You can check the full implementation here:
xxxxxxxxxx
public Mono<OTP> validate(Long otpId, Integer pin) {
log.info("Entered resend with arguments: {}, {}", otpId, pin);
AtomicReference<FaultReason> faultReason = new AtomicReference<>();
return otpRepository.findById(otpId)
.switchIfEmpty(Mono.error(new OTPException("Error validating OTP", FaultReason.NOT_FOUND)))
.zipWhen(otp -> applicationRepository.findById(otp.getApplicationId()))
.flatMap(Tuple2 -> {
// perform various status checks here...
if (!otp.getStatus().equals(OTPStatus.TOO_MANY_ATTEMPTS))
otp.setAttemptCount(otp.getAttemptCount() + 1);
if (otp.getStatus().equals(OTPStatus.VERIFIED))
return otpRepository.save(otp);
else {
return Mono.error(new OTPException("Error validating OTP", faultReason.get(), otp));
}
})
.doOnError(throwable -> {
if (throwable instanceof OTPException) {
OTPException error = ((OTPException) throwable);
if (!error.getFaultReason().equals(FaultReason.NOT_FOUND) && error.getOtp() != null) {
otpRepository.save(error.getOtp()).subscribe();
}
}
});
}
- We start by querying the OTP by id using our reactive CRUD repository. Notice that for such simple queries no implementation is needed
- We then use the switchIfEmpty and Mono.error methods to throw an Exception if no record found. Our
@ControllerAdviceannotated Bean takes cares of all the rest - Otherwise if a record is found, we build our next step using zipWhen to get the maximum number of allowed attempts from the "application" table
- We use again flatmap to apply our conditional logic on the returned results. Notice that the previous call to zipWhen gives as a Tuple namely a
Tuple2<OTP, Application>allowing as to have access to these objects and the information they hold - if all validations pass, we update the OTP's status to VERIFIED and we return the result, otherwise we return Exception via Mono.error. Again,
OTPControllerAdvicefinishes the job by returning proper status and message - We are not done yet though. Even in case of Mono.error we still need to update things in the databases. Therefore, we have the doOnError method in the end. As the name says, it acts as an error handler so we can put in there related actions. It's like a finally clause but for errors. Have in mind that doOnSuccess also exists and other variants as well
Let us pause for a moment here and notice that inside our doOnError method in the end, we call the subscribe method. If you check the Reactor documentation, the subscribe method and its variants are usually used to trigger the execution of a reactive chain of actions. But so far, we did not have it anywhere in the code. And we did not need it since we return either Mono or Flux all the way back to our Rest Controllers. They are the ones that perform the subscribe for us, behind the scenes. And as Rossen Stoyanchev says in his must-watch presentation Guide to "Reactive" for Spring MVC Developers, "you should keep the flight going" i.e. if possible not block and return Reactive types from your endpoints. On the other hand, we need to use the subscribe method inside the doOnError because there we do not return anything, so we need to trigger somehow our Reactive repository to execute that update.
III. Resend OTP
Business Requirement
Given Given an existing OTP id give the possibility to be re-sent to multiple channels (SMS, e-mail, Viber etc.) and concurrently (in parallel):
- fetch the corresponding OTP record from the DB by querying "otp" table by id
- if not found or its status is no longer valid (e.g. EXPIRED), return error
- if found, proceed re-sending it to the customer via multiple channels and simultaneously via the notification-service
- Return to the caller the OTP sent
Solution
You can check the implementation here:
xxxxxxxxxx
return otpRepository.findById(otpId)
.switchIfEmpty(Mono.error(new OTPException("Error resending OTP", FaultReason.NOT_FOUND)))
.zipWhen(otp -> {
// perform various status checks here...
List<Mono<NotificationResultDTO>> monoList = channels.stream()
.filter(Objects::nonNull)
.map(method -> webclient.build()
.post()
.uri(notificationServiceUrl)
.accept(MediaType.APPLICATION_JSON)
.body(BodyInserters.fromValue(NotificationRequestForm.builder()
.channel(method)
.destination(Channel.EMAIL.name().equals(method) ? mail : otp.getMsisdn())
.message(otp.getPin().toString())
.build()))
.retrieve()
.bodyToMono(NotificationResultDTO.class))
.collect(Collectors.toList());
return Flux.merge(monoList).collectList();
})
.map(Tuple2::getT1);
Our focus on this one is to demonstrate parallel calls the the same endpoint. In our first use case we saw how we can make parallel calls to different endpoints, returning different types using Mono.zip. Now we will use Flux.merge instead.
Let's see how we approached this:
- Like before we start by querying the OTP by id
- With the switchIfEmpty and Mono.error we return the proper error if the OTP id passed does not exist
- We continue with zipWhen because we want to perform the next steps after the information from the database is retrieved
- Inside the zipWhen, apart from an OTP status check, we iterate the list of Channels passed and prepare a list of remote calls which will be the list of "sources" to our Flux
- Then we pass this
Iterableof sources to Flux.merge and we return it after we have collected all responses from the notification-service to aList<Mono<NotificationResultDTO>>. We don't do anything with these in our example, but we could for example log them or check something else from the data they carry if needed - Finally, because we need to return only the OTP from our Tuple of results, we perform a map operation
IV. Get All OTPs and OTP Status
Business Requirement
Get back a list of OTPs for a given MSISDN and a single OTP by id for checking its status.
Solution
You can check the implementation here.
We left the more straightforward cases for the end since you will find many examples simply returning Flux or Mono usually by querying a Relational of NoSQL database with reactive drivers support. Keep in mind though that in case of relational databases, Spring Data R2DBC (R2DBC stands for Reactive Relational Database Connectivity) does not offer many features of ORM frameworks (JPA, Hibernate). Its primary target is to be a simple, limited, opinionated object mapper. So, if you are used in your past projects to JPA and Hibernate then prepare for a mind shift about this part as well.
Other Topics
Logging
Logging is an important aspect for every kind of software. Solutions based on Microservices architectures have additional demands for centralized logging. However, when we are using File Appenders for logging then we have an issue since this I/O operation is blocking. See the following issue for an example:
A solution is to select and configure Async Appenders which seem to be supported by major SLF4J implementations like Log4j and Logback. In our example we go with the Logback AsyncAppender. An example configuration can be seen here.
The AsyncAppender has five (5) configuration options:
- queueSize – The maximum capacity of the buffer size. Default value is 256.
- discardingThreshold – Instruct to drop events once the buffer reaches the max capacity. Default value is 20%.
- neverBlock – Setting it to true will prevent any blocking on the application threads but it comes at the cost of lost log events if the AsyncAppender’s internal buffer fills up. Default value is false.
- includeCallerData – Extracting caller data. Default value is false.
- maxFlushTime – Specify a maximum queue flush timeout in milliseconds.
Distributed Tracing
Tracing is another vital aspect of Microservices monitoring. We can trace all calls that are made from/to the microservices, using Spring Cloud Sleuth and Jaeger.
Sleuth offers a convenient auto-configuration that works out-of-the-box with popular frameworks like Spring MVC and WebFlux. It allows injecting trace and span IDs automatically and displaying this information in the logs, as well as annotation-based span control. To make it work with Jaeger, we need to enable the Zipkin collector port in Jaeger's configuration.
One thing to have in mind is that limitations do exist here as well. For example, tracing database calls with R2DBC is not yet supported. You may find the related issue here:
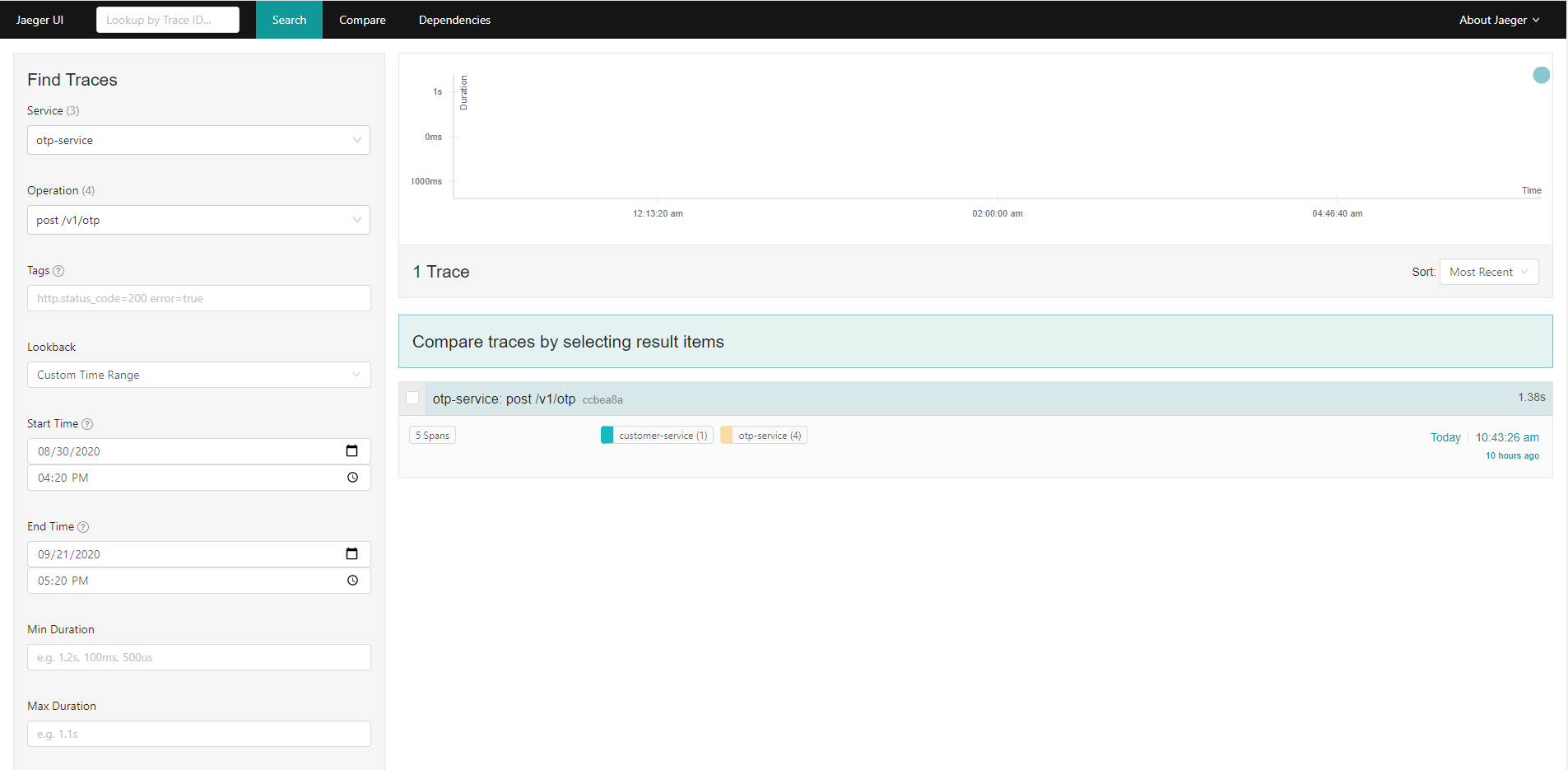
The following is screenshot of Jaeger UI homepage:
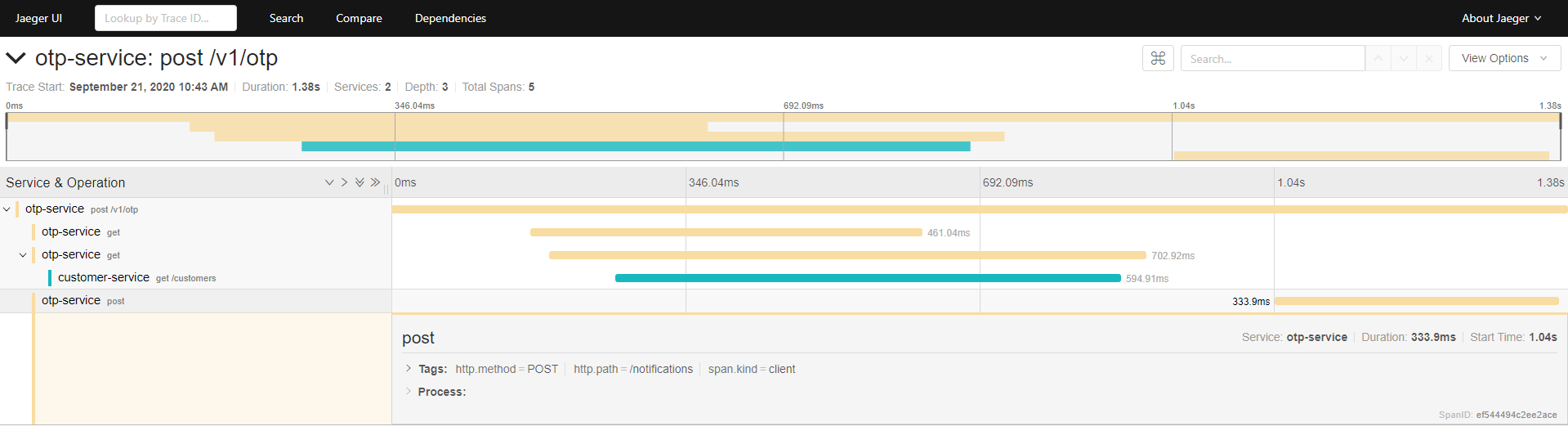
This is an example of tracing the call which generates OTPs:
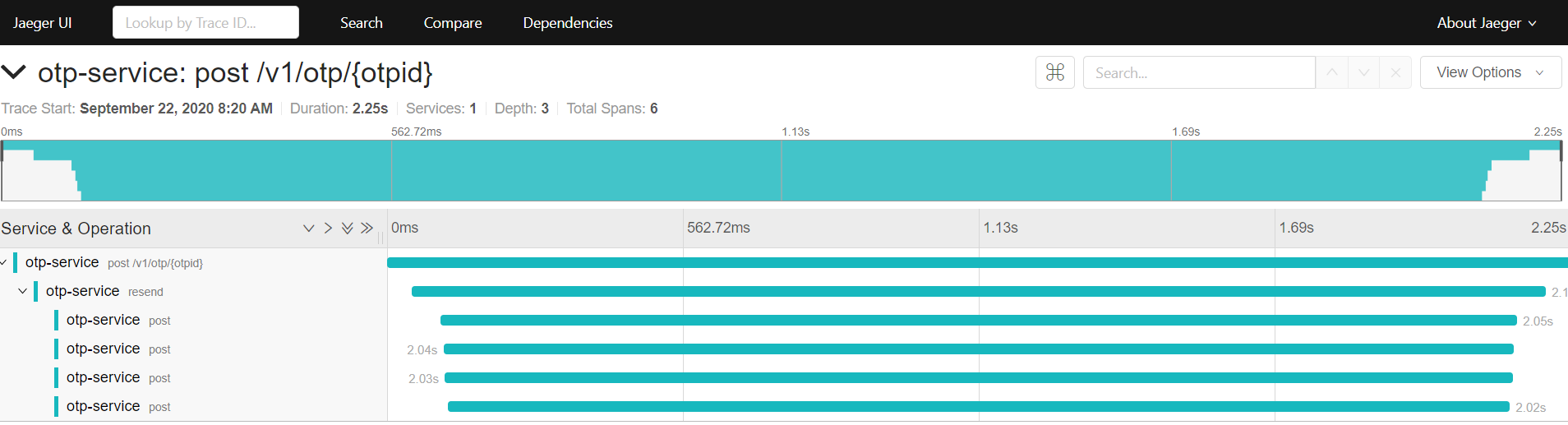
This is an example of tracing the call which resends an OTP via multiple channels in parallel:
Reactive Types Support for @Cacheable Methods
Spring's @Cacheable annotation is a convenient approach to handle caching usually at the services level. This cache abstractions works seamlessly with various caching implementations including JSR-107 compliant caches, Redis etc. However, at the moment of writing there is still no Reactive types support for @Cacheable methods. The related is issue is:
And although Redis is a pretty common centralized cache solution, and a Reactive driver for Redis exists in the Spring Data project, there is no plan at the moment to add a reactive cache implementation:
Handling Special Cases
On a typical Spring WebFlux server (Netty), you can expect one thread for the server and several others for request processing which are typically as many as the number of CPU cores. Although WebClient does not block the thread, sometimes it is desired to use another thread pool than the main worker thread pool shared with the server [5] . Such cases may be:
- calls to remote endpoints with exceptionally long response times
- the need for increased level of concurrency e.g. we want to submit 10 calls in parallel cause we know we can afford it and it suits our scenario
For this purpose, Spring WebFlux provides thread pool abstractions called Schedulers. These are combined with Task Executors where we can create different concurrency strategies, set minimum and maximum number of threads, etc.
xxxxxxxxxx
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("otp-");
executor.initialize();
return executor;
}
Let's now imagine that we want to check the status of five MSISDNs simultaneously and return the result as a list of NotificationResultDTOs:
xxxxxxxxxx
public Flux<NotificationResultDTO> checkMsisdns(List<String> msisdns) {
return Flux.fromIterable(msisdns)
.parallel()
.runOn(Schedulers.fromExecutor(taskExecutor))
.flatMap(this::checkMsisdn)
.sequential()
}
- At the point where we call the parallel method, it creates a ParallelFlux. This indicates the simultaneous character of the execution.
- At the runOn method we plugin our task executor and finally we need to specify how to convert ParallelFlux to simple Flux. We select to do this in a sequential manner while other options exist for the results to follow specific order
For a full list of options you may check the ParallelFlux API.
BlockHound
The change from blocking to non-blocking code or from imperative to reactive programming is tricky and demands to build up a level of experience in order to make your self comfortable. Sometimes it may be hard to detect blocking code in Reactor thread. And this is because we don't need to use block to make things blocking but we can unconsciously introduce blocking by using a library which can block the current thread.
A useful utility to helps us detect some cases is BlockHound. It is sponsored by Pivotal and it can be used in various ways, but we recommend to used during the test phase. The only thing you need for this is to include the following dependency:
xxxxxxxxxx
<dependency>
<groupId>io.projectreactor.tools</groupId>
<artifactId>blockhound-junit-platform</artifactId>
<version>1.0.4.RELEASE</version>
</dependency>
Keep in mind that if go with Java 11 and above, the following JVM argument is needed for the tool to work properly:
-XX:+AllowRedefinitionToAddDeleteMethods
Integration Testing
In our sample project we show an example Integration Test covering our most "complicated" endpoint which is the one that generates an OTP. We use HoverFly for mocking responses of the two "external" services (i.e. number-information and notification-service) and the call to our "internal" service (i.e. customer-service). We also use Testcontainers for spinning-up a dockerized PostgresDB during the test's execution.
The full code can be seen in OTPControllerIntegrationTests class.
We also use WebTestClient which is a Client for testing web servers that uses WebClient internally to perform requests while also providing a fluent API to verify responses. This client can connect to any server over HTTP, or to a WebFlux application via mock request and response objects.
One thing worthwhile to mention is the "trick" we perform in order to simulate the existence of customer-service service instance. A ServiceInstance represents an instance of a service in a discovery system. When running integration tests, we usually have part of cloud features disabled and service discovery is one of them. However, since we use @LoadBalanced WebClient when we invoke the customer-service during the integration flow we test, we need a way to simulate a "static" instance of this service. Moreover, we need to "bind" it with HoverFly so when it is invoked to return the mocked response we want. This is achieved with thegr.kmandalas.service.otp.OTPControllerIntegrationTests.TestConfig static class.
Async SOAP
Nowadays most of the systems we integrate with expose REST endpoints. Its not uncommon however to still must integrate with SOAP-based web services. Both JAX-WS and ApacheCXF allow the generation of non-blocking clients. You may find an example of how to deal with such case at Reactive Web Service Client with JAX-WS.
How to Run
To build and test the application, the prerequisites are:
- Java 11 and above
- Maven
- Docker (because we use TestContainers during our Integration tests)
Then simply execute from a terminal:
mvn clean verify
The easiest way is to run the microservices using Docker and Docker Compose:
docker-compose up --build
When the containers are up and running, you can visit consul's UI to see the active services:
http://localhost:8500/ui/dc1/services
Below, you may find curl commands for invoking the various endpoints via our API Gateway:
Generate OTP
xxxxxxxxxx
curl --location --request POST 'localhost:8000/otp-service/v1/otp' \
--header 'Content-Type: application/json' \
--data-raw '{
"msisdn": "00306933177321"
}'
Validate OTP
xxxxxxxxxx
curl --location --request POST 'http://localhost:8000/otp-service/v1/otp/36/validate?pin=356775'
Resend OTP
xxxxxxxxxx
curl --location --request POST 'localhost:8000/otp-service/v1/otp/2?via=AUTO,EMAIL,VIBER&[email protected]' \
--header 'Content-Type: application/json'
Get All OTPs
xxxxxxxxxx
curl --location --request GET 'localhost:8000/otp-service/v1/otp?number=00306933177321'
OTP Status
xxxxxxxxxx
curl --location --request GET 'localhost:8000/otp-service/v1/otp/1'
Conclusion
Performance has many characteristics and meanings. Reactive and non-blocking generally do not make applications run faster. They can, in some cases, for example when using the WebClient to run remote calls in parallel while at the same time avoiding getting involved with Task Executors and use a more elegant and fluent API instead. It comes of course with a significant learning curve.
The key expected benefit of reactive and non-blocking is the ability to scale with a small, fixed number of threads and less memory. That makes applications more resilient under load because they scale in a more predictable way. In order to observe those benefits, however, you need to have some latency (including a mix of slow and unpredictable network I/O). That is where the reactive stack begins to show its strengths, and the differences can be dramatic [8].
Some interesting load testing and comparison results are presented at [9]. The conclusion is that Spring Webflux with WebClient and Apache clients "win" in all cases. The most significant difference (4 times faster than blocking Servlet) comes when underlying service is slow (500ms). It is 15–20% faster than non-blocking Servlet with CompetableFuture. Also, it does not create a lot of threads comparing with Servlet (20 vs 220).
So, if you are up to start building Reactive Microservices with Spring and eager to take advantage of the benefits above, we hope we gave a quite good picture of the challenges that lie ahead and the amount of preparation needed.
Opinions expressed by DZone contributors are their own.
Comments