SQL or NoSQL, That Is The Question!
It's not about SQL vs. NoSQL, but rather when to use each option. This guide walks through the benefits of relational and non-relational databases as well as use cases.
Join the DZone community and get the full member experience.
Join For Freewe all know that in the database technology world, it comes down to two main database types – sql (relational) and nosql (non-relational). the differences between them are rooted in the way they are designed, which data types they support, and how they store them.
relational databases are relationally structured entities, usually representing a real-world object; for example, a person or shopping cart details. non-relational databases are document-structured and distributed, holding information in a folder-like hierarchy which holds the data in an unstructured format.
in daily language, we call them sql and nosql, which reflects the fact that nosql databases are not written in structured query language (sql) only.
reasons to use a sql database
not every database fits every business need. that’s why many companies rely on both relational and non-relational databases for different tasks . although nosql databases have gained popularity for their speed and scalability, there are still situations in which a highly structured sql database might be preferable. two reasons why you might consider a sql database are:
you need acid compliance (atomicity, consistency, isolation, durability). acid compliance reduces anomalies and protects the integrity of your database. it does this by defining exactly how transactions interact with the database, which is not the case with nosql databases, which have a primary goal of flexibility and speed, rather than 100% data integrity.
your data is structured and unchanging. if your business is not growing exponentially, there may be no reason to use a system designed to support a variety of data types and high traffic volume.
reasons to use a nosql database
to prevent the database from becoming a system-wide bottleneck, especially in high volume environments, nosql databases perform in a way that relational databases cannot.
the following features are driving the popularity of nosql databases like mongodb, couchdb, cassandra, and hbase:
storing large volumes of data without structure. a nosql database doesn’t limit storable data types. plus, you can add new types as business needs change.
using cloud computing and storage. cloud-based storage is a great solution, but it requires data to be easily spread across multiple servers for scaling. using affordable hardware on-site for testing and then for production in the cloud is what nosql databases are designed for.
rapid development. if you are developing using modern agile methodologies, a relational database will slow you down. a nosql database doesn’t require the level of preparation typically needed for relational databases.
in the next section, we will use examples to show some of the distinctions between these two worlds. we will take a look at one basic example, and then focus on three key topics:
- scalability - basic functionality
- indexing - basic functionality
- crm - advanced functionality
sql vs. nosql
we will start with some key concepts of relational and nosql databases. below is a graph-structured database for human relationships. in the diagram, (a) shows a schema-less structure, and (b) shows how it can be extended to a normal, structured schema.
 schema-less means that two documents in a nosql data structure don’t need common fields and can store different types of data.
schema-less means that two documents in a nosql data structure don’t need common fields and can store different types of data.
var cars = [
{ model: "bmw", color: "red", manufactured: 2016 },
{ model: "mercedes", type: "coupe", color: "black", manufactured: “1-1-2017” }
];in a relational world, you have to store data in a defined structure from which you can then retrieve data. for example (using a join operator between two tables):
select orders.orderid, customers.name, orders.date
from orders
inner join customers
on orders.custid = customers.custidas a more advanced topic, and a demonstration of when sql is a better candidate than nosql, i will use the fast compaction algorithm . this recently proposed nosql algorithm shows that it is difficult to handle the continuous generation of sorted string tables (called sstables ). these tables are key-value strings sorted by keys. their generation, over time, causes the read operation to create a disk i/o bottleneck, and reads become slower than writes in nosql databases, thereby negating one of the main advantages of nosql databases. in an attempt to reduce this effect, nosql systems run the compaction protocols in the background, trying to merge multiple tables in a single table. however, this merging is very resource-intensive.
scalability
one of the main differences between nosql and sql is that nosql databases are considered to be more scalable than sql databases. mongodb, for example, has built-in support for replication and sharding (horizontal partitioning of data) to support scalability. while these features are, up to a point, available in sql databases, they require significant investment of human and hardware resources.
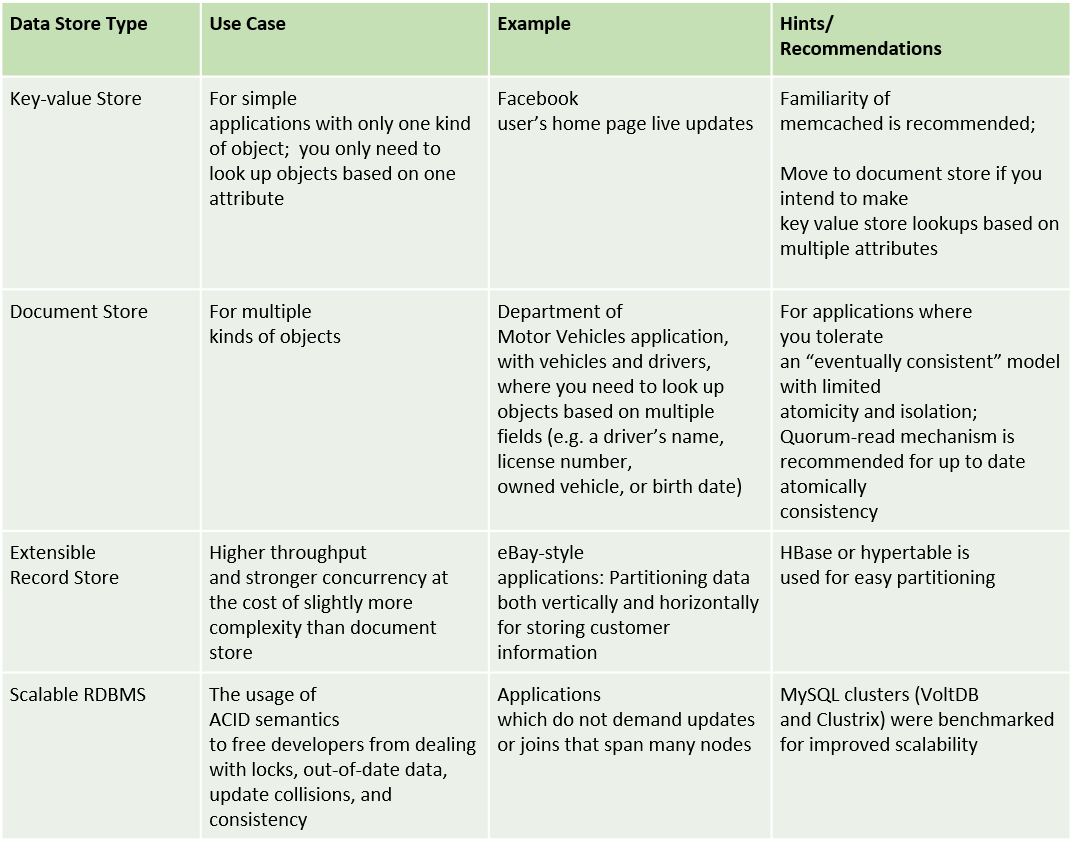
for a detailed comparison of the two options, you can reference cattell’s proposed classification for data stores . this report is summarized below. testing was performed using three main parameters: concurrency, data storage, and replication. concurrency was evaluated by analyzing data locking mechanism, multi-version concurrency control, and acid. data storage was tested in physical storage and in-memory modes and replication was tested on its support of synchronous or asynchronous modes.
using data retrieved from these tests, authors concluded that sql products with clustering capability have shown promising performance per node, and also the capacity for scalability, giving the advantage to rdbms systems over nosql, because of their full acid compliance.
indexing
in rdbms systems, indexes are used to accelerate data retrieval operations. a missing index means that a table will need to be completely scanned to fulfill a read query.
in sql and nosql, database indexes serve the same purpose, quicker and more optimized retrieval of data. but, how they do this is different, because of different database architectures and differences how data is stored in database engine. while in sql indexes are in form of b-trees which show hierarchical structure of relational data, in nosql databases they point to documents or parts of documents which, in general, have no relations among them. this is nicely described in this article , which goes into deep technical detail on this topic.
example: crm application
crm applications are one of the best examples of big data environments, with huge daily data volumes and numbers of transactions. all vendors of these applications are using both sql and nosql, and while the transactional data is still mostly stored in sql databases, with improvements of publicly available dbaas (database-as-a service) services like aws dynamodb and azure documentdb, much more data processing could move to nosql world running on the clouds.
while these manage services remove security and technical access challenges, it is also an area where nosql databases are used for what they are primarily made — analytic storage and data mining. the amount of data stored in huge crms in telecom or finance companies would be nearly impossible to analyze using data mining tools such as sas or r, because the demand on hardware resources in a transactional world would be massive.
unstructured , document-like data, which constitutes the input to statistical models, which then give companies the ability to do churn or marketing analysis, is the key benefit of these systems. crm is also one of the best examples where these two systems are not competitors, but exist in harmony, each playing its own role in the bigger data architecture.
conclusion
it’s possible to choose one option and switch to another later, but with good planning you can save a lot of time and money. it basically comes down to this:
indicators for projects where sql is ideal:
- logic-related discrete data requirements which can be identified up front
- data integrity is essential
- standards-based proven technology with good developer experience and support.
indicators for projects where nosql is ideal:
- unrelated, indeterminate, or evolving data requirements
- simpler or looser project objectives, able to start coding immediately
- speed and scalability is imperative
it is, however, obvious that this is no longer an issue of sql vs. nosql. instead, it’s sql and nosql, with both having their own clear places, and increasingly being integrated into each other. microsoft, oracle, and teradata, for example, are now all selling some form of hadoop integration to connect sql-based analysis to the world of unstructured big data.
Published at DZone with permission of Alon Brody. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments