Stream Processing vs. Batch Processing: What to Know
The two popular ways used for data processing are batch processing and stream processing. Let’s discuss each process in detail and understand their differences.
Join the DZone community and get the full member experience.
Join For FreeBig data is at the center of all business decisions these days. It refers to large volumes of data generated through different sources, and this data then provides the foundation for business decisions. The concept of data has been there for centuries, but only now do we have enough computational resources to process and use that data. There are different ways through which we can process data. The two popular ways used for data processing are batch processing and stream processing. Let’s discuss each process in detail and understand their differences.
What Is Batch Processing?
Batch processing is a method to process large volumes of data in batches, and this is done at a specific scheduled time. Data is collected over a period of time, and at a specific time interval, it is processed, and output data is sent to other systems or stored in a data warehouse. The size of data in batch processing is known.
In batch processing, input data come from one or more sources. Batch jobs run on a scheduled time, and it depends on the data infrastructure of an organization and how frequently these jobs are running. In batch processing, data is extracted from input sources and is transformed to prepare the data for analytics purposes or to feed it into a machine learning model. After transformation, data is loaded into a data warehouse. The ETL procedure in batch processing is pre-defined, and it doesn’t require any user interaction. Batch processing can also be triggered once data reaches a particular volume. The whole process of batch processing is automated using workflow orchestration tools like airflow, prefect, flyte, dagster, etc.
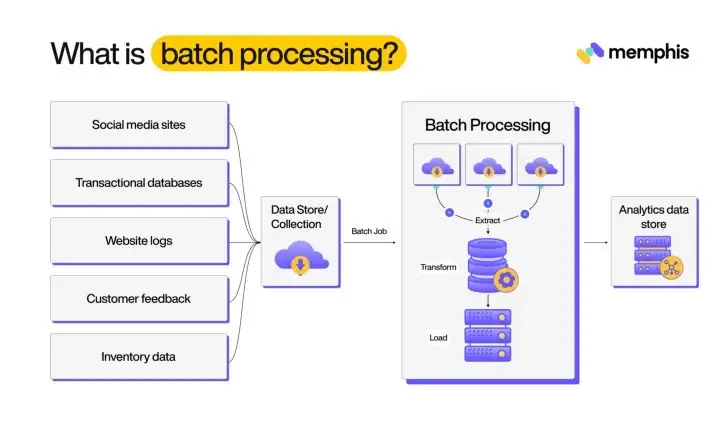
Batch processing is a commonly used approach in designing data management infrastructure. Batch processing is a cost-effective solution in cases dealing with large volumes of data. In batch processing, jobs can be prioritized such that time-sensitive jobs are scheduled earlier, and it gives an additional advantage to manage resources. It can be executed offline to reduce the load on machines. All the processes are automated, which improves the data quality.
It permits organizations to deal with huge volumes of data rapidly. Since many records can be handled without a moment’s delay, batch processing speeds up handling time and delivers data so that organizations can perform analysis on that data.
Batch Processing: Use-Cases
Batch processing is used when we need to process large volumes of data to provide quick analytics results. The data processed is usually collected over a period of time, and there’s no real-time data analytics required. It extracts data from data sources using complex scripts and efficiently manages resources to process that data. Batch processing is particularly useful in the following use cases:
Anomaly detection: In Anomaly detection, legacy data is used to detect outliers. In such algorithms, batch processing is used to extract and transform large volumes of data to detect anomalies.
Customer segmentation: It is used to run targeted campaigns and provides services to customers by processing historical data.
Payroll systems: Data related to employee salaries are collected and processed as a batch at the end of each month.
Banking system: Bank statements of customers are calculated at the end of each month or yearly in batches based on their subscriptions.
Billing services: The billing services use batch processing to generate invoices for customers at the end of each month.
Batch Processing: Challenges
Batch processing comes with a few challenges that need to be addressed to design a scalable solution. Let’s look at a few challenges associated with batch processing.
- Batch processes require human support for monitoring which makes the work mundane for humans and increases the cost of operations for organizations.
- Debugging in batch systems is difficult. If a job fails, then other jobs have to wait, and it takes more time than expected.
- Batch jobs run at a specific time, so any change in data is delayed until the next batch is executed.
- There’s often a delay in the availability of data to targeted systems like dashboards or machine learning models due to delays in batch processing.
- Running multiple jobs at the same time often needs more efficient resource monitoring and management by the team.
- The recovery from failure needs collaboration from different teams, and it takes a long time.
- Large volumes of data are processed in multiple passes and need more time to deliver the results.
What Is Stream Processing?
Stream processing refers to extracting, processing, and delivering data in real-time. Stream processing is a stateless operation, and users get insights in real time. The data stream is generated continuously in real-time and usually refers to data in motion, and stream processing is used to process that data.
In stream processing, data is processed as soon as it arrives, the data stream is ingested into the system, and processing logic is applied to it. The processed data is delivered to real-time dashboards, machine learning models, data warehouses, and other systems. Stream processing is also used to generate alerts in case any errors are detected. Stream processing systems are optimized to process large volumes of data with minimum delay hence providing low latency.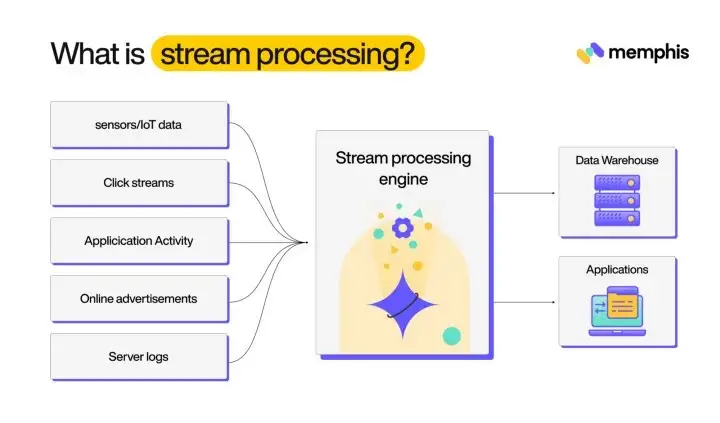
It is nearly impossible to regulate or enforce the data structure or control the volume and frequency of the data generated in the modern world because data is produced from an infinite number of sources, including hardware sensors, servers, mobile devices, applications, web browsers, internal and external. Applications that examine and interpret data streams must sequentially process each data packet one at a time. In order to allow applications to operate with data streams, each data packet generated will contain the source and timestamp.
Stream processing enables organizations to analyze time-series data and identify patterns in them. For instance, data coming from websites are monitored to generate insights about users. In stream processing, the size of data is unknown and assumed infinite. The processing speed is just a few milliseconds and delivers fast output. It is beneficial for systems that require continuous data processing and need to take immediate action.
Companies will gain a competitive edge in their marketplace by being able to quickly gather, analyze, and act on current data. Organizations can respond to market changes, consumer needs, and business possibilities more quickly by using stream processing. This responsiveness can be a differentiating trait as the speed of business accelerates with digitization.
Stream Processing: Use-Cases
Stream processing is an ideal choice for systems when an immediate response is required when new data arrives rather than waiting to process the data at a specific time interval.
In cases when analytics results are needed in real time, stream processing is essential. Using platforms like spark streaming, Memphisdev, and Kafka, you can design data streams to input data into analytics tools as soon as it is generated and get almost immediate analytics insights. Let’s discuss a few use cases where stream processing is an ideal choice:
Fraud detection: In today’s digital age, online frauds are detected, and fraudulent transactions are stopped in real time. Stream processing is used to process data in real-time and detect anomalies.
Sentiment analysis: Stream processing is used to ingest data in sentiment analysis systems. These systems are designed for data-driven marketing in real-time.
Log monitoring: Logs from multiple applications are monitored, and errors are detected in real-time. Stream processing is used to process the incoming logs data continuously, and results are delivered.
Customer satisfaction: Stream processing is used in analyzing customer behavior, digital experience monitoring, and observing the customer journey to improve services. Customer feedback is a useful measure for evaluating an organization’s strengths and areas for improvement. A company’s reputation will improve the quicker it responds to consumer complaints and offers a solution. This speed pays off when it comes to online evaluations and word-of-mouth marketing, which can be the determining factor for drawing in new prospects and turning them into customers.
Stream Processing: Challenges
Stream processing is a solution to modern data infrastructure, but it has its own challenges. Let’s discuss where stream processing should be improved for robust solutions.
- Scalability in stream processing is challenging when errors happen and pipeline malfunctions. The speed at which data is received can also increase, which requires more resources to be added to ensure scalability.
- In the real world, data is not always consistent and durable. The incoming data can be inconsistent and modified, which makes it difficult for the data stream to process it.
- The order of the data in the data stream must be determined, and it is crucial in many applications. It’s critical that every line is in the correct order when developers examine an aggregated log view to troubleshoot a problem. The order in which a data packet is generated and the order in which it arrives at its destination frequently differ. The clocks and timestamps of the devices generating the data frequently differ. Applications must be cognizant of their assumptions on ACID transactions when evaluating data streams.
- Stream processing pipelines must ensure fault tolerance. Can your system prevent disruptions from a single point of failure with data flowing from various sources, locations, and in different forms and volumes? Can it maintain high availability and durability while storing streams of data? To build a robust solution, a data architect must answer such questions.
Batch Processing vs. Stream Processing Using Memphis
Batch processing extracts the data at a specific time and then applies transformations to it. The differences in schemas of incoming data sources during processing aren’t that significant and can be resolved in a data pipeline. The batch data pipeline travels between various data teams, and collaboration becomes difficult. The tools available for batch processing are hard to learn, and deployment is difficult as well.
In contrast, stream processing systems have more than one data source, each having its own schema different from others and its own requirements. Data is transformed and analyzed for each source in parallel. There are multiple target systems that request data simultaneously, and it’s hard to troubleshoot if something goes wrong.
However, by resolving the challenges associated with stream processing, an efficient data pipeline can be designed. One of the platforms that provide low-code solutions for stream processing is Memphis.dev. Memphis.dev is the only low-code real-time data processing platform that offers a full ecosystem for in-app streaming use cases using a produce-consume paradigm that supports modern in-app streaming pipelines and async communication by removing frictions of management, cost, resources, language barriers, and time for data-oriented teams, in contrast to other message brokers and queues that require extensive coding and time.
It provides support for maintaining and defining schemas, collecting data from multiple sources, and taking actions based on events. It integrates with a variety of other third-party tools as well. Memphis.dev gives stream processing advantage over batch processing.
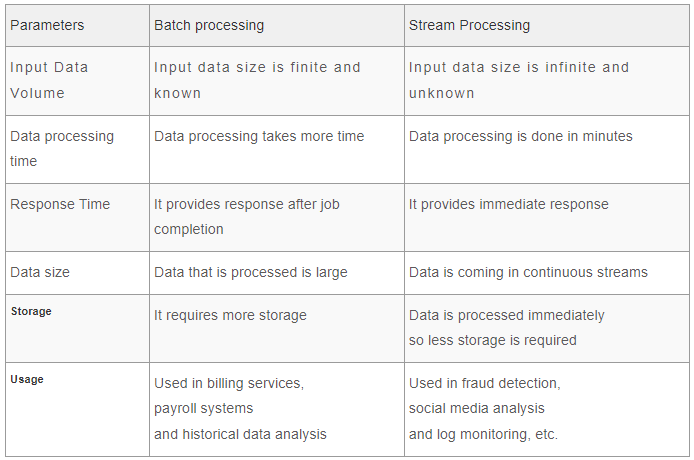
Stream vs. Batch Processing Comparison
In light of the above discussion, let’s compare batch processing and stream processing.
Conclusion
There is no technique that is always preferable in data processing. Depending on your project, batch, and stream processing each offer advantages and disadvantages. Companies continue to lean on stream processing in an effort to maintain their agility. Batch processing is a favorable choice for companies with legacy systems. The choice of data processing technique depends on the internal data ecosystem of the company. Moreover, each project has different requirements so that both techniques can be used in parallel. In real-world data, teams are flexible and adaptable to new tools and techniques to improve data pipelines.
Published at DZone with permission of Idan Asulin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments