An Introduction to Stream Processing
As a gentle introduction to stream processing, we’ve defined what it is, how it differs from batch processing, and how computation works in stream processing.
Join the DZone community and get the full member experience.
Join For FreeIntroductory note: This article has been co-authored by Federico Trotta and Karin Wolok.
Introduction
Stream processing is a distributed computing paradigm that supports the gathering, processing, and analysis of high-volume and continuous data streams to extract insights in real time.
As we’re living in a world where more and more data "is born" as streams, allowing analysts to extract insights in real-time for faster business decisions, we wanted to propose a gentle introduction to this topic.
Table of Contents
- Defining and understanding stream processing
- Computing data in stream processing
- Transformations in stream processing
- Stream processing use cases
- How to deal with stream processing: introducing streaming databases and systems
- Conclusions
Defining and Understanding Stream Processing
Stream processing is a programming paradigm that views streams — also called “sequences of events in time” — as the central input and output objects of computation:
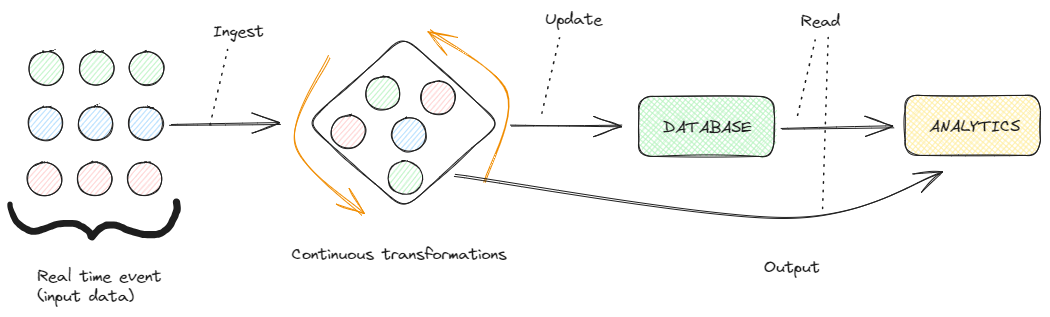
Stream processing. Image by Federico Trotta
Unlike traditional batch processing — which handles data in chunks — stream processing allows us to work with data as a constant flow, making it ideal for scenarios where immediacy and responsiveness are fundamental:
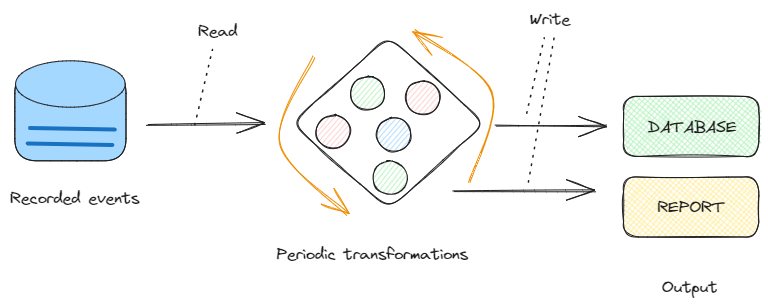
So, stream processing means computing and processing data in motion and real time.
This is important in today's world because the majority of data today "is born" as continuous streams:
A stream of data. Image by Federico Trotta
Let’s think about cases like, sensor events, user activity on a website, or financial trades.
Sensors, for example, continuously collect data from the environment in which they are installed in real time. This provides applications for weather monitoring, industrial automation, IoT devices, and many more.
Also, if we think of websites, we can say that they are platforms where users dynamically engage in various activities such as clicking, scrolling, typing, and more. These interactions, which are continuously generated, are captured in real-time to analyze user behavior, improve user experience, and make timely adjustments, just to mention a few activities.
In financial markets, today transactions occur rapidly and continuously. Stock prices, currency values, and other financial metrics are constantly changing, and require real-time data processing to make rapid decisions.
So, the objective of stream processing is to quickly analyze, filter, transform, or enhance data in real time.
Once processed, the data is passed off to an application, data store, or another stream processing engine.
Computing Data in Stream Processing
Given the nature of stream processes, data are processed in different ways with respect to batch processing.
Let’s discuss how.
Incremental Computation
Incremental computation is a technique used to optimize computational processes, allowing them to process only the parts of the data that have changed since a previous computation, rather than recomputing the entire result from scratch.
This technique is particularly useful for saving computational resources.
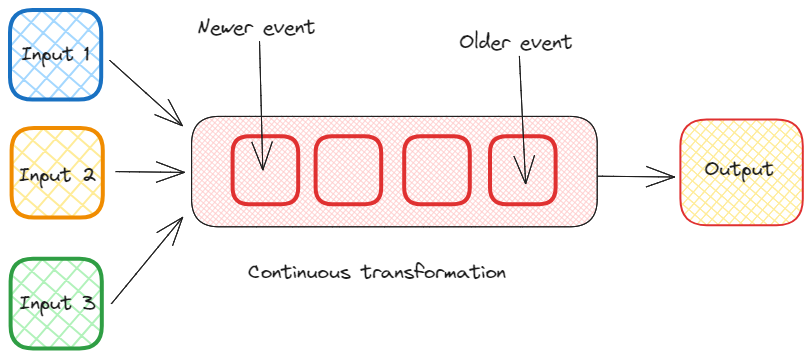
Incremental computation. Image by Federico Trotta.
In the context of stream processing, incremental computation involves updating results continuously as new data arrives, rather than recalculating everything from scratch each time.
To give an example, let's say we have a stream of sensor data from IoT devices measuring temperature in a factory. We want to calculate the average temperature over a sliding window of time, such as the average temperature over the last 5 minutes, and we want to update this average in real-time as new sensor data arrives.
Instead of recalculating the entire average every time new data arrives, which could be computationally expensive especially as the dataset grows, we can use incremental computation to update the average efficiently.
Transformations in Stream Processing
In the context of stream processing, we can perform different sets of transformations to an incoming data stream.
Some of them are typical transformations we can always make on data, while others are specific for the “real-time case.”
Among the others, we can mention the following methodologies:
-
Filtering: This is the act of removing unwanted data from the whole data stream, based on specified conditions.
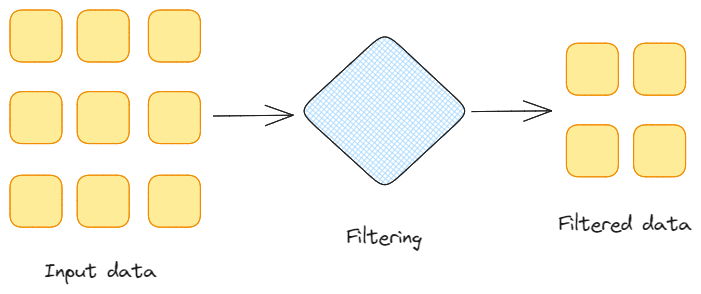
Data filtering. Image by Federico Trotta.
-
Aggregation: This involves summing, averaging, counting, or finding any other statistical measure to gain insight from a given stream of data, over specific intervals.
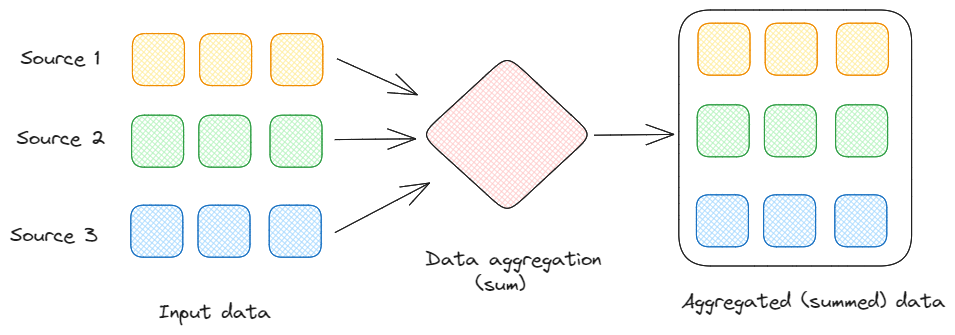
Data aggregation. Image by Federico Trotta.
-
Enrichment: It’s the act of enhancing the incoming data by adding additional information from external sources. This process can provide more context to the data, making it more valuable for downstream applications.
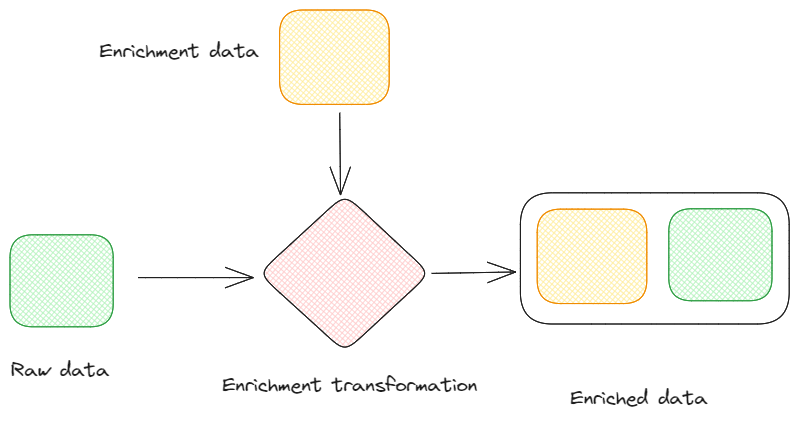
Data enrichment. Image by Federico Trotta.
-
Transformation: Data transformation is a general way to modify data formats. With this methodology, we apply various transformations to the data, such as converting data formats, normalizing values, or extracting specific fields, ensuring that the data is in the desired format for further analysis or integration.
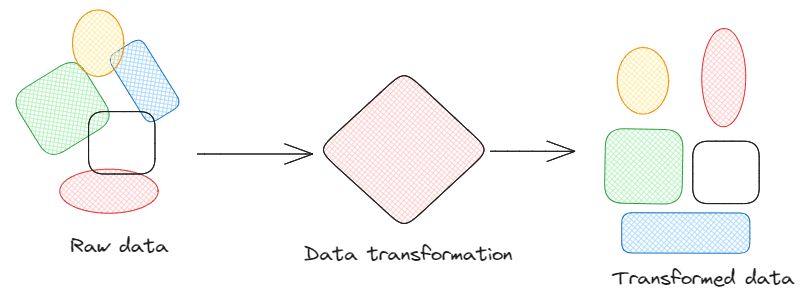
Data transformation. Image by Federico Trotta.
-
Windowing: It’s the act of dividing the continuous stream into discrete windows of data. This allows us to analyze data within specific time frames, enabling the detection of trends and patterns over different intervals.
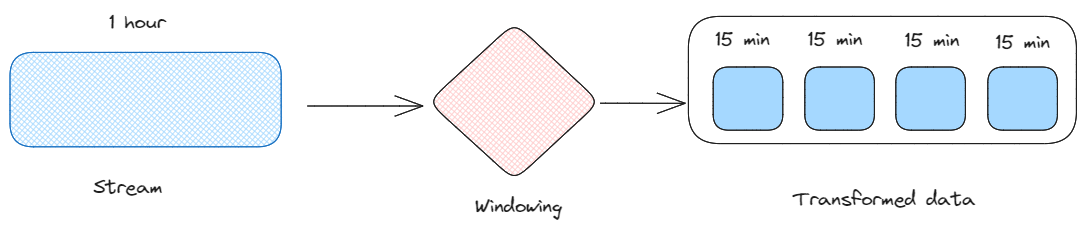
Windowing. Image by Federico Trotta.
-
Load, balancing, and scaling: It’s a way to distribute the processing load across multiple nodes to achieve scalability. Stream processing frameworks, in fact, often support parallelization and distributed computing to handle large volumes of data efficiently.
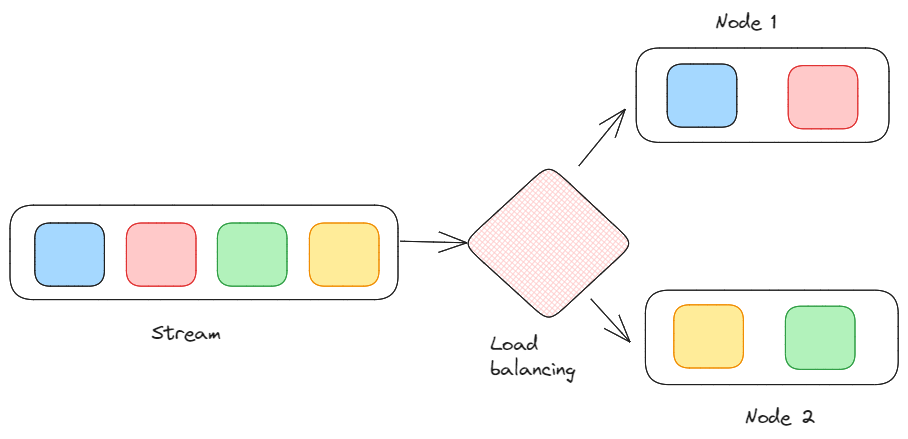
The process of load, balancing, and scaling. Image by Federico Trotta.
-
Stateful stream processing. It’s a type of transformation that involves processing a continuous stream of data in real time while also maintaining the current state of the data that has been processed. This allows the system to process each event as received while also tracking changes in the data stream over time, by including the history and the context of the data.
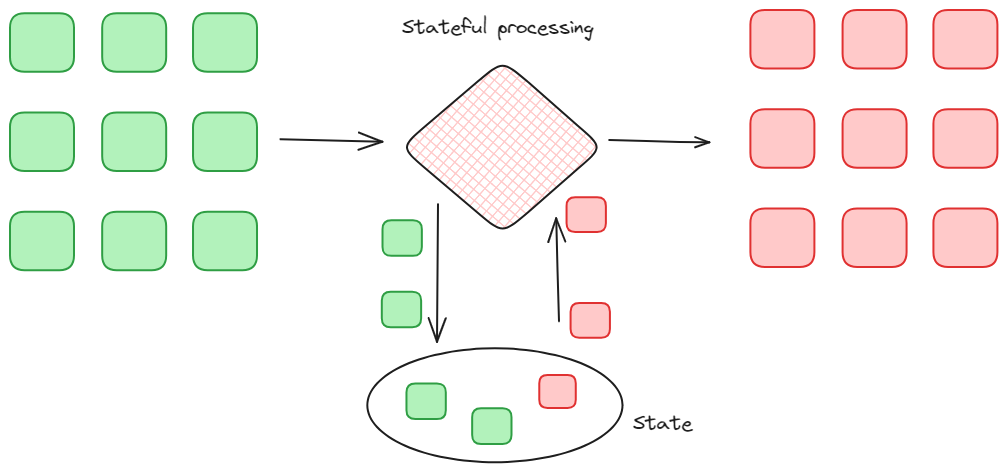
-
Pattern recognition: As understandable, this is a kind of transformation that searches for a set of event patterns. It is particularly interesting in the case of data streams as the data are in a continuous flow because it can also intercept anomalies in the flow.
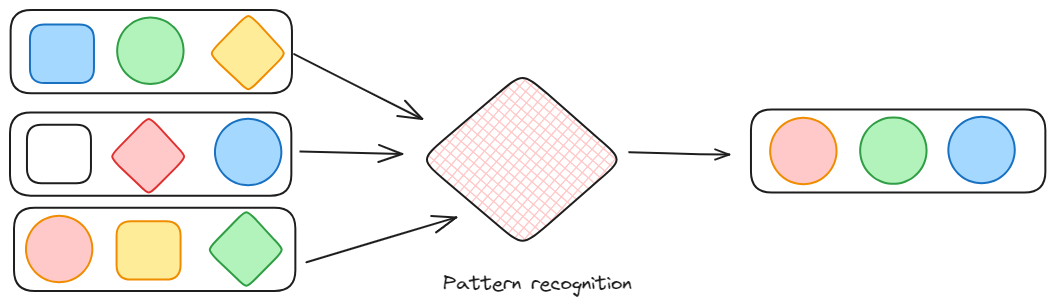
Stream Processing Use Cases
To gain a deeper understanding of stream processing, let’s consider some real-world use cases.
Use Case 1: Real-Time Fraud Detection in Financial Transactions
Due to the increased online transactions, fraudsters are becoming increasingly sophisticated, and detecting fraudulent activities in real-time is crucial to prevent financial losses and protect customers.
In this case, stream processing is applied to analyze incoming transactions, looking for patterns or anomalies that might indicate fraudulent behaviors.
For example, if someone clones your credit card and buys something from a location on the other side of the world from where you reside, the system recognizes a fraudulent transaction thanks to stream processing (and Machine Learning).
Use Case 2: IoT Data Analytics for Predictive Maintenance
In today’s interconnected world, devices and sensors generate vast amounts of data. For industries like manufacturing, predicting equipment failures and performing proactive maintenance are critical to minimize downtime and reduce operational costs.
In this case, stream processing is employed to analyze data streams from IoT sensors, applying algorithms for anomaly detection, trend analysis, and pattern recognition. This helps companies with the early identification of potential equipment failures or deviations from normal operating conditions.
Use Case 3: Anomaly Detection and Handling in Trading Systems
Trading systems generate a constant stream of financial data, including stock prices, trading volumes, and other market indicators.
Since anomaly detection is a crucial aspect of trading systems, helping to identify unusual patterns or behaviors in financial data that may indicate potential issues, errors, or fraudulent activities, sophisticated algorithms are employed to analyze the data stream in real time and identify patterns that deviate from normal market behavior.
Use Case 4: Advertising Analytics
In advertising analytics, the use of data streams is fundamental in gathering, processing, and analyzing vast amounts of real-time data to optimize ad campaigns, understand user behavior, and measure the effectiveness of advertising efforts.
Data streams allow advertisers to monitor ad campaigns in real time, and metrics such as impressions, clicks, conversions, and engagement can be continuously tracked, providing immediate insights into the performance of advertising assets.
How To Deal with Stream Processing: Introducing Streaming Databases and Systems
As stream processing involves dealing with data in real time, they have to be managed differently from how data in batches are.
What we mean is that the “classical” database is no longer sufficient. What’s really needed is “an ecosystem”: not just a database that can manage data “on the fly.”
In this section, we introduce some topics and concepts that will be deepened in upcoming, deep articles, on streaming systems and databases.
Ksqldb
Apache Kafka “is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.”
Kafka, in particular, is an ecosystem that provides a streaming database called ‘ksqldb,’ but also tools and integrations to help data engineers implement a stream processing architecture to existing data sources.
Apache Flink
Apache Flink “is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, and perform computations at in-memory speed and at any scale.”
In particular, Apache Flink is a powerful stream processing framework suitable for real-time analytics and complex event processing, while Kafka is a distributed streaming platform primarily used for building real-time data pipelines.
RisingWave
RisingWave “is a distributed SQL streaming database that enables simple, efficient, and reliable processing of streaming data.”
RisingWave reduces the complexity of building stream-processing applications by allowing developers to express intricate stream-processing logic through cascaded materialized views. Furthermore, it allows users to persist data directly within the system, eliminating the need to deliver results to external databases for storage and query serving.
In particular, RisingWave can gather data in real-time from various applications, sensors and devices, social media apps, websites, and more.
Conclusions
As a gentle introduction to stream processing, in this article, we’ve defined what stream processing is, how it differs from batch processing, and how computation works in stream processing.
We've also reported some use cases to show how the theory of stream processes applies to real-world examples like manufacturing and finance.
Finally, we introduced some solutions on how to implement stream processing. In upcoming articles, we're describing what are stream processing systems and streaming databases and how to pick the one that suits your business needs.
Opinions expressed by DZone contributors are their own.
Comments