Exploring the Dynamics of Streaming Databases
This article explores what a streaming database is, as it is the core component of a stream processing system, and describes some available solutions.
Join the DZone community and get the full member experience.
Join For FreeIn previous articles, we’ve discussed the basics of stream processing and how to choose a stream processing system.
In this article, we’ll describe what a streaming database is, as it is the core component of a stream processing system. We'll also provide some commercially available solutions to make an informative choice if you need to choose one.
Table of Contents
- Fundamentals of streaming databases
- Challenges in implementing streaming databases
- The architecture of streaming databases
- Examples of streaming databases
Fundamentals of Streaming Databases
Given the nature of stream processing that aims to manage data as a stream, engineers can’t rely on traditional databases to store data, and this is why we’re talking about streaming databases in this article.
We can define a streaming database as a real-time data repository for storing, processing, and enhancing streams of data. So, the fundamental characteristic of streaming databases is their ability to manage data in motion, where events are captured and processed as they occur.
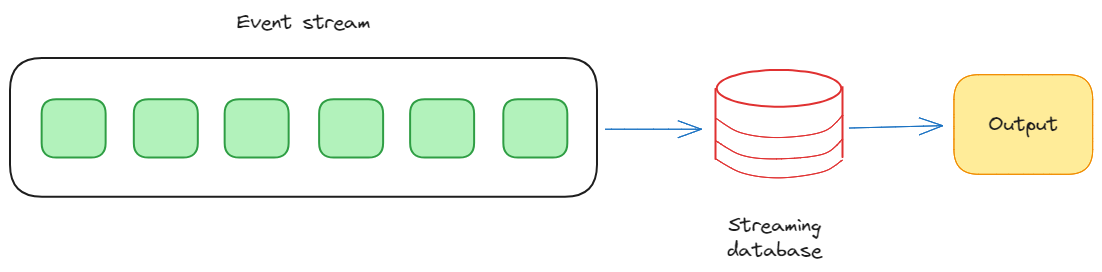
So, unlike traditional databases that store static datasets and require periodic updates to process them, streaming databases embrace an event-driven model, reacting to data as it is generated. This allows organizations to extract actionable insights from live data, enabling timely decision-making and responsiveness to dynamic trends.
One of the key distinctions between streaming and traditional databases lies in their treatment of time. In streaming databases, time is a critical dimension because data are not just static records but are associated with temporal attributes.
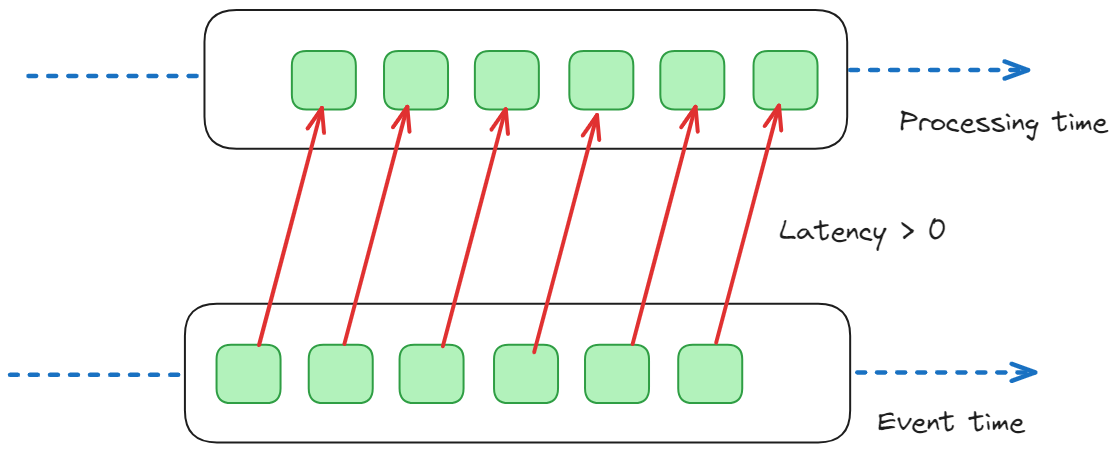
In particular, we can define the following:
- Event time: This refers to the time when an event or data point actually occurred in the real world. For example, if you are processing a stream of sensor data from devices measuring temperature, the event time would be the actual time when each temperature measurement was recorded by the sensors.
- Processing time: This refers to the time at which the event is processed within the stream processing system. For example, if there is a delay or latency in processing the temperature measurements after they are received, the processing time would be later than the event time.
This temporal awareness facilitates the creation of time-based aggregations, allowing businesses to gain the right understanding of trends and patterns over time intervals, and handling out-of-order events.
In fact, events may not always arrive at the processing system in the order in which they occurred in the real world for several reasons, like network delays, varying processing speeds, or other factors.
So, by incorporating event time into the analysis, streaming databases can reorder events based on their actual occurrence in the real world. This means that the timestamps associated with each event can be used to align events in the correct temporal sequence, even if they arrive out of order. This ensures that analytical computations and aggregations reflect the temporal reality of the events, providing accurate insights into trends and patterns.
Challenges in Implementing Streaming Databases
While streaming databases offer a revolutionary approach to real-time data processing, their implementation can be challenging.
Among the others, we can list the following challenges:
Sheer Volume and Velocity of Streaming Data
Real-time data streams, especially high-frequency ones common in applications like IoT and financial markets, generate a high volume of new data at a high velocity. So, streaming databases need to handle a continuous data stream efficiently, without sacrificing performance.
Ensuring Data Consistency in Real-Time
In traditional batch processing, consistency is achieved through periodic updates. In streaming databases, ensuring consistency across distributed systems in real time introduces complexities. Techniques such as event time processing, watermarking, and idempotent operations are employed to address these challenges but require careful implementation.
Security and Privacy Concerns
Streaming data often contains sensitive information, and processing it in real-time demands robust security measures. Encryption, authentication, and authorization mechanisms must be integrated into the streaming database architecture to safeguard data from unauthorized access and potential breaches. Moreover, compliance with data protection regulations adds an additional layer of complexity.
Tooling and Integrations
The diverse nature of streaming data sources and the variety of tools available demand thoughtful integration strategies. Compatibility with existing systems, ease of integration, and the ability to support different data formats and protocols become critical considerations.
Need for Skilled Personnel
As streaming databases are inherently tied to real-time analytics, the need for skilled personnel to develop, manage, and optimize these systems has to be taken into consideration. The scarcity of expertise in the field can delay the diffuse adoption of streaming databases, and organizations must invest in training and development to bridge this gap.
Architecture of Streaming Databases
The architecture of streaming databases is crafted to handle the intricacies of processing real-time data streams efficiently.
At its core, this architecture embodies the principles of distributed computing, enabling scalability and responsiveness to the dynamic nature of streaming data.
A fundamental aspect of streaming databases’ architecture is the ability to accommodate continuous, high-velocity data streams. This is achieved through a combination of data ingestion, processing, and storage components.
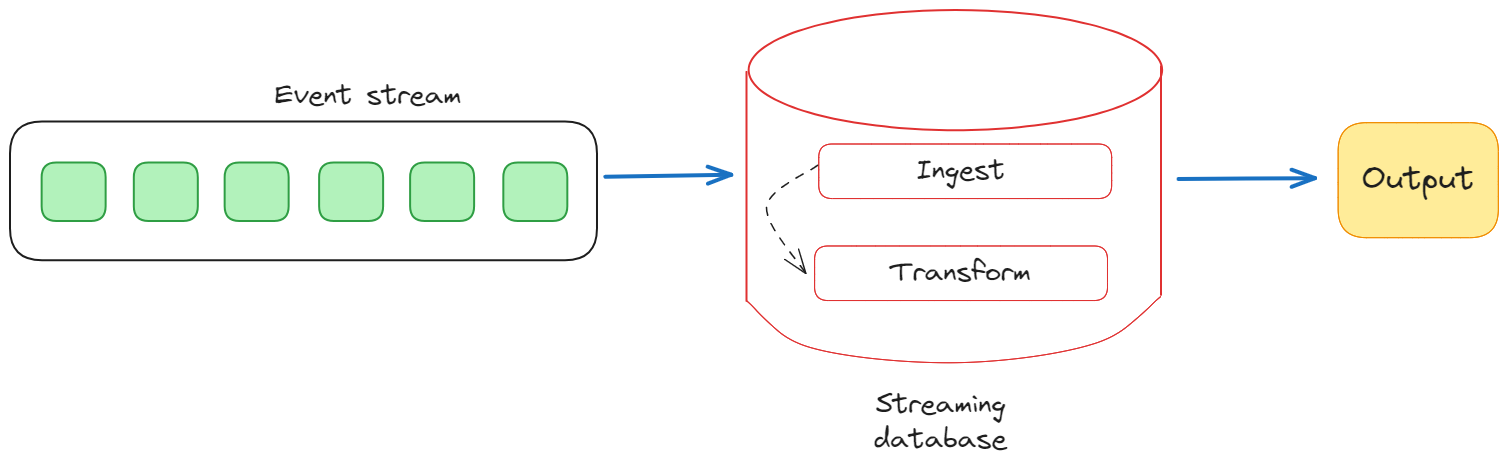
The data ingestion layer is responsible for collecting and accepting data from various sources in real time. This may involve connectors to external systems, message queues, or direct API integrations.
Once ingested, data is processed in the streaming layer, where it is analyzed, transformed, and enriched in near real-time. This layer often employs stream processing engines or frameworks that enable the execution of complex computations on the streaming data, allowing for the derivation of meaningful insights.
Since they deal with real-time data, a hallmark of streaming database architecture is the event-driven paradigm. In fact, each data point is treated as an event, and the system reacts to these events in real-time. This temporal awareness is fundamental for time-based aggregations, and handling out-of-sequence events, facilitating a granular understanding of the temporal dynamics of the data.
The schema design in streaming databases is also dynamic and flexible, allowing for the evolution of data structures over time. Unlike traditional databases with rigid schemas, in fact, streaming databases accommodate the fluid nature of streaming data, where the schema may change as new fields or attributes are introduced: this flexibility allows for the possibility of handling diverse data formats and adapting to the evolving requirements of streaming applications.
Example of a Streaming Database
Now, let’s introduce a couple of examples of commercially available streaming databases, to highlight their features and fields of application.
RisingWave
Image from the RisingWave website
RisingWave is a distributed SQL streaming database that enables simple, efficient, and reliable streaming data processing. It consumes streaming data, performs incremental computations when new data comes in, and updates results dynamically.
Since it is a distributed database, RisingWave embraces parallelization to meet the demands of scalability. By distributing the processing tasks across multiple nodes or clusters, in fact, it can effectively handle a high volume of incoming data streams concurrently. This distributed nature also ensures fault tolerance and resilience, as the system can continue to operate seamlessly, even in the presence of node failures.
Also, RisingWave Database is an open-source distributed SQL streaming database designed for the cloud. In particular, it was designed as a distributed streaming database from scratch, not a bolt-on implementation based on another system.
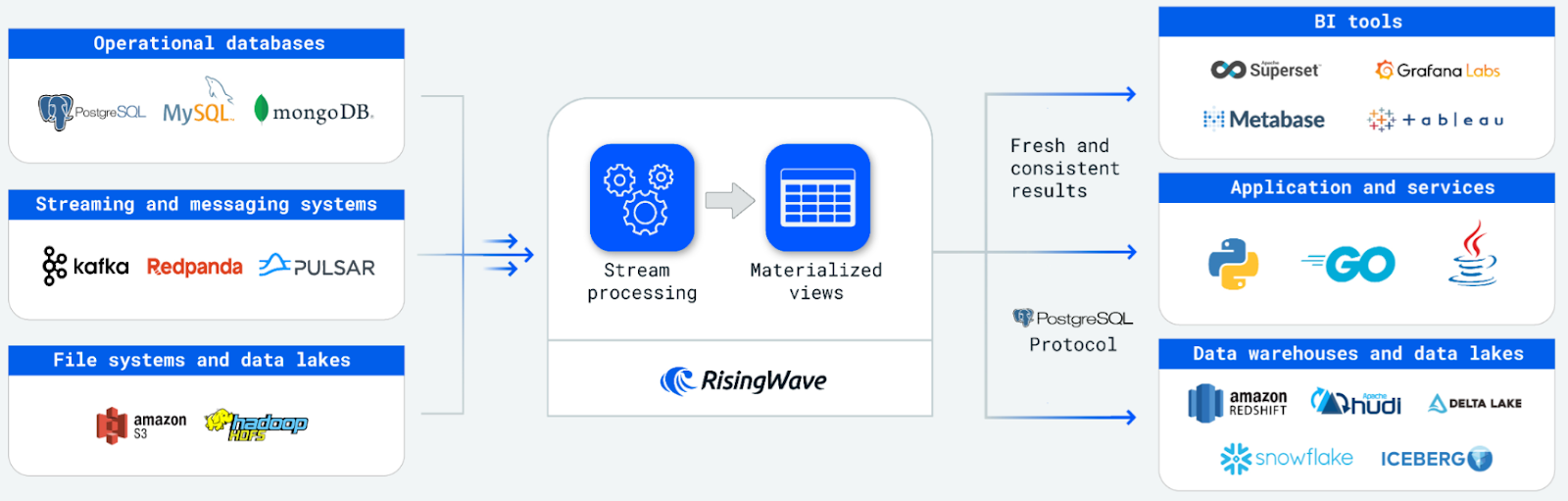
Image from the RisingWave website
It also reduces the complexity of building stream-processing applications by allowing developers to express intricate stream-processing logic through cascaded materialized views. Furthermore, it allows users to persist data directly within the system, eliminating the need to deliver results to external databases for storage and query serving.
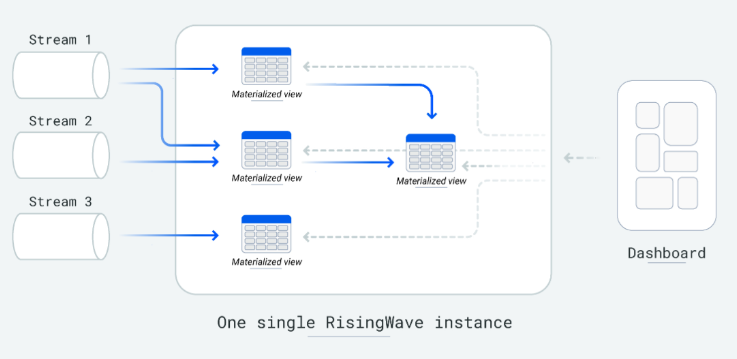
Image from the RisingWave website
The ease of the RisingWave database can be described as follows:
- Simple to learn: It uses PostgreSQL-style SQL, enabling users to dive into stream processing as they’d do with a PostgreSQL database.
- Simple to develop: As it operates as a relational database, developers can decompose stream processing logic into smaller, manageable, stacked materialized views, rather than dealing with extensive computational programs.
- Simple to integrate: With integrations to a diverse range of cloud systems and the PostgreSQL ecosystem, RisingWave has a rich and expansive ecosystem, making it straightforward to incorporate into existing infrastructures.
Finally, RisingWave provides RisingWave cloud: a hosted service that brings the power to create a new cloud-hosted RisingWave cluster and get started on stream processing in minutes.

Image from the RisingWave website
Materialize

Materialize is a high-performance, SQL-based streaming data warehouse designed to offer real-time, incremental data processing with a strong emphasis on simplicity, efficiency, and reliability. Its architecture enables users to build complex, incremental data transformations and queries on top of streaming data with minimal latency.
Since it is built for real-time data processing, Materialize leverages efficient incremental computation to ensure low-latency updates and queries. By processing only the changes in data rather than reprocessing entire data sets, it can handle high-throughput data streams with optimal performance.
Materialize is designed to scale horizontally, distributing processing tasks across multiple nodes or clusters to manage a high volume of data streams concurrently. This nature also enhances fault tolerance and resilience, allowing the system to operate seamlessly even in the face of node failures.
As an open-source streaming data warehouse, Materialize offers transparency and flexibility. It was built from the ground up to support real-time, incremental data processing, not as an add-on to an existing system.
It significantly simplifies the development of stream-processing applications by allowing developers to express complex stream-processing logic through standard SQL queries. Developers, in fact, can directly persist data within the system, eliminating the need to move results to external databases for storage and query serving.
The ease of Materialize can be described as follows:
- Simple to learn: It uses PostgreSQL-compatible SQL, enabling developers to leverage their existing SQL skills for real-time stream processing without a steep learning curve.
- Simple to develop: Materialize allows users to write complex streaming queries using familiar SQL syntax. The system's ability to automatically maintain materialized views and handle the underlying complexities of stream processing means that developers can focus on business logic rather than the intricacies of data stream management, making the development phase easy.
- Simple to integrate: With support for a variety of data sources and sinks including Kafka and PostgreSQL, Materialize integrates seamlessly into different ecosystems, making the incorporation with existing infrastructure easy.
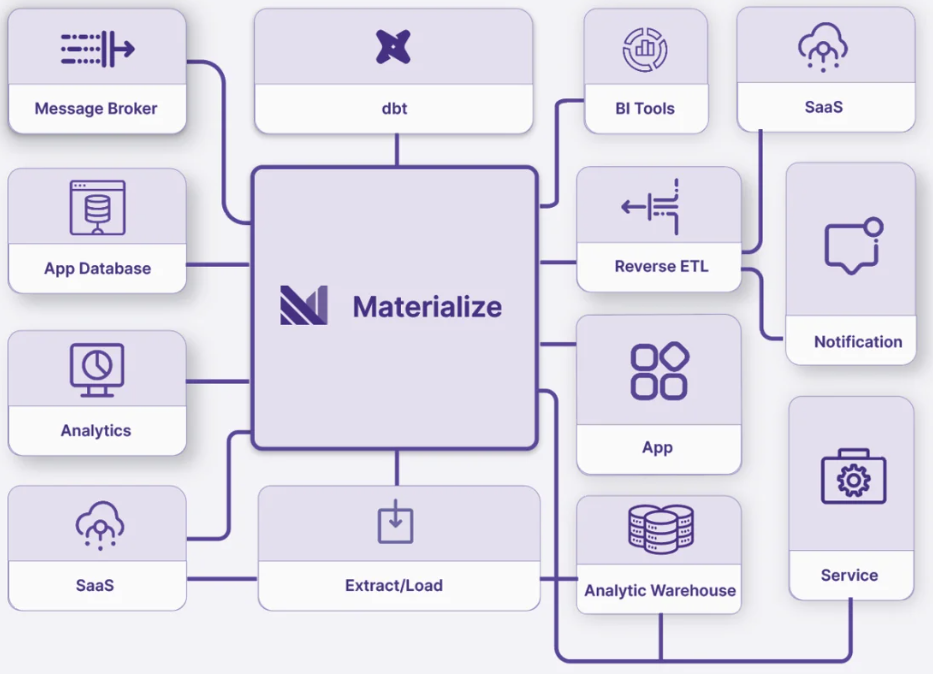
Finally, Materialize provides strong consistency and correctness guarantees, ensuring accurate and reliable query results even with concurrent data updates. This makes it an ideal solution for applications requiring timely insights and real-time analytics.
Materialize's ability to deliver real-time, incremental processing of streaming data, combined with its ease of use and robust performance, positions it as a powerful tool for modern data-driven applications.
Conclusions
In this article, we’ve analyzed the need for streaming databases when processing streams of data, comparing them with traditional databases.
We’ve also seen that the implementation of a streaming database in existing software environments presents challenges that need to be addressed, but available commercial solutions like RisingWave and Materialize overcome them.
Note: This article has been co-authored by Federico Trotta and Karin Wolok.
Opinions expressed by DZone contributors are their own.
Comments