Streaming in Mule
Process millions of records in few seconds or minutes with streaming strategy in Mule.
Join the DZone community and get the full member experience.
Join For FreeObjectives
- Streaming Overview
- Advantages of Streaming
- Limitations
- Use cases
- Streaming with Sample workflow
- Testing Metrics and execution report
Mule 4 Testing Metrics with 1 million ,10 million records.
Mule 3 Testing Metrics with 1M,10M and 20M records.
Streaming Overview
Streaming is the process where we just refer to the data as its bytes arrive instead of scanning and loading the entire document to index it. Streaming speeds up the processing of large documents without overloading memory. Mule supports end-to-end streaming throughout a flow.
Enablement of Streaming
We can enable streaming through 2 modes:
- Through internal configuration properties of streaming inside connectors configurations. Example: opting for streaming strategy properties
- Through data weave configuration properties, we can achieve streaming output. Example: deferred=true or streaming=true
Types of Streaming
We have the option to set streaming strategy configuration inside the connector, which has three types of streaming:
- Repeatable file store stream (default): Mule 4 introduces repeatable streams as its default framework handling streams. It enables us to read stream data more than once and have concurrent access to the stream.
- Non-repeatable stream:
- The stream can only be read once.
- Non-repeatable streaming improves performance.
- Need a very tight optimization for performance and resource consumption.
- Repeatable in-memory stream: This strategy creates a temporary file to the disk to store the contents without allocated buffer size. It is useful to use for small sizes of data.
Advantages of Streaming
- The streaming technique offers a huge advantage over fully loading the data into memory since it prevents the Java heap from being exhausted by big input files. With less allocated heap size, we can execute large data sets.
- Batch execution and other execution scopes for processing large datasets can be removed, which can reduce code complexity.
- Based on our previous PSR result, we have observed that the throughput has increased 30x times (3000 Rec/sec Vs 90000 Rec/sec)
- The execution time difference from the previous test result to streaming goes down from 1.5Hr to 3.35 Min for 20M records.
- Increase of max streaming memory to process huge data load in the wrapper config file.
Limitations
- In non-repeatable streaming, streamed data can be referenced only once. No reference to the streamed payload is found in a nested lambda. Access of output Streamed data fails if a script attempts to reference the same payload more than once with a pipe closed error.
- Exception handling to capture faulty data from the streamed payload is not achievable.
- If the stream exceeds this limit, the application fails. This strategy defaults to a buffer size of 512 KB. For larger streams, the buffer is expanded by a default increment size of 512 KB until it reaches the configured maximum buffer size.
- Grouping logic is not supported.
- The lookup function will not work with deferred = true.
Use Cases
- When data validation is not required
- When business logic is less
- When the data load is huge to process
Streaming With Sample Workflow
Mule 4 Observation:
Mule Runtime: 4.4.0
We have created a prototype application to understand the e2e streaming with a very basic sample flow:
- Full Streaming: Create a sample basic flow and try to read an input CSV file through streaming and convert it into JSON format with streaming and write the content into JSON
file via the local file system. - Partial Streaming: Create a sample basic flow and try to read an input CSV file with the non-repeatable streaming method and convert the data into JSON format with streaming and write it into a local file system in chunks of 1000 size. We can observe here that
before writing the payload into the file, we are using for each to divide the data into chunks which will load the data into memory, thus describing a partial streaming strategy.
Flow:
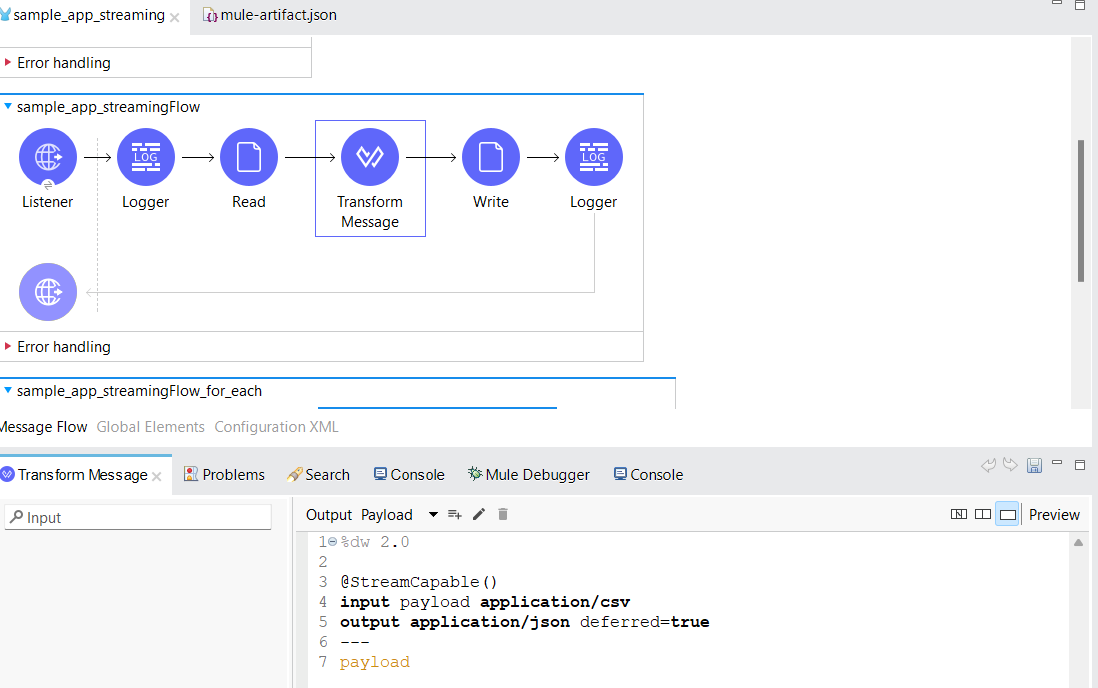
Testing Metrics:
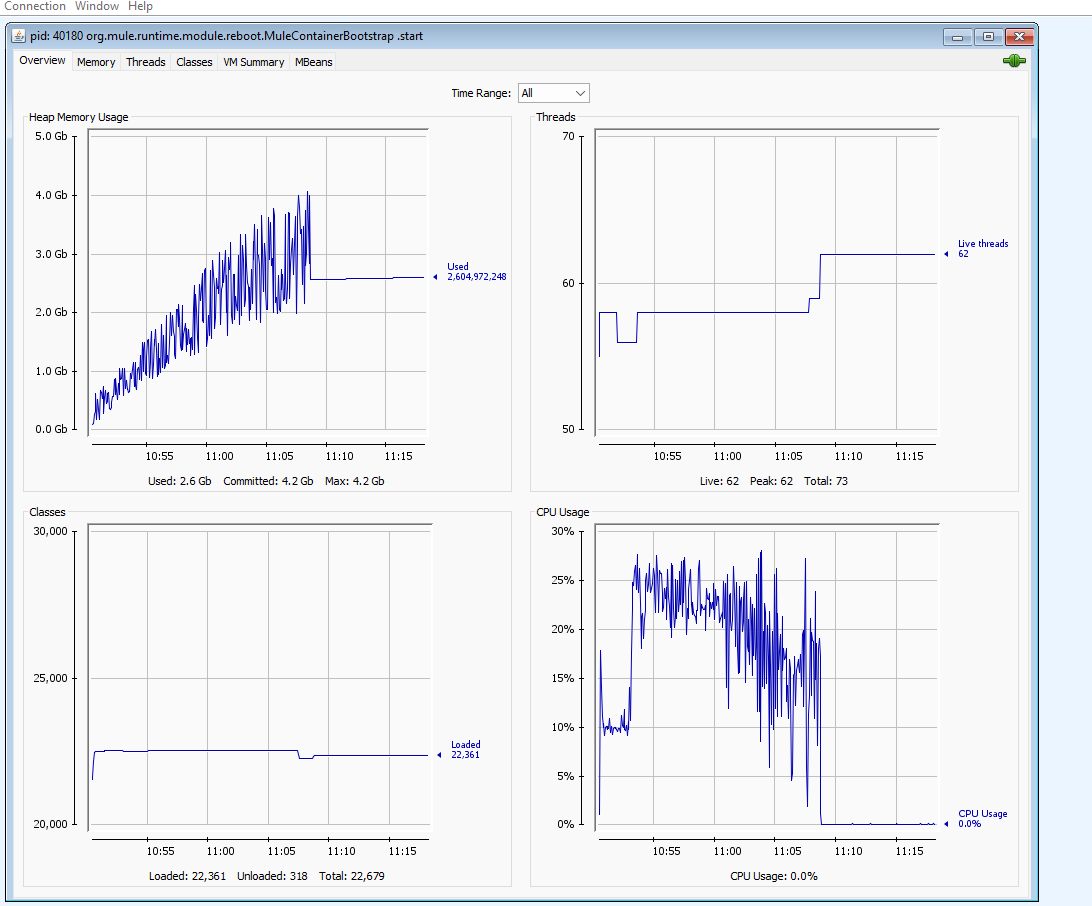
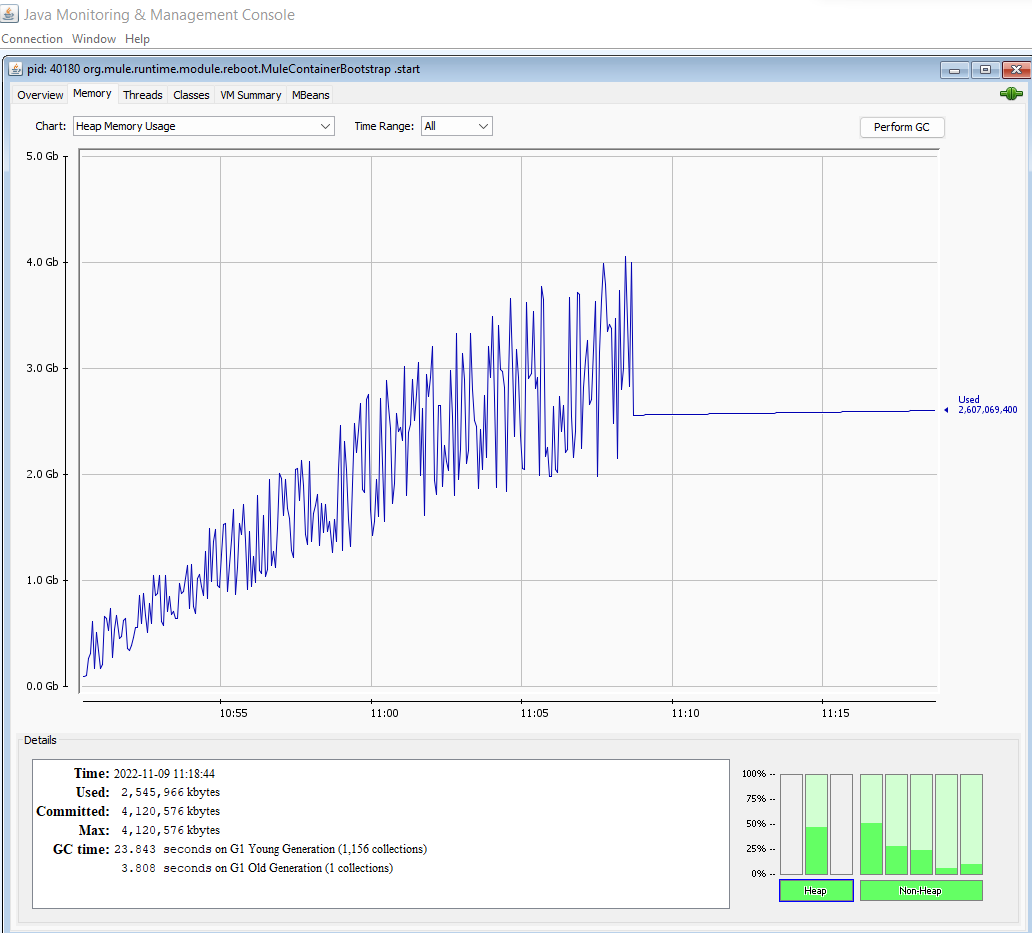
- Partial Streaming Metrics:
- 10M Records
- Streaming: Partial
- Heap size: 4GB
- Process timing: 18 minutes
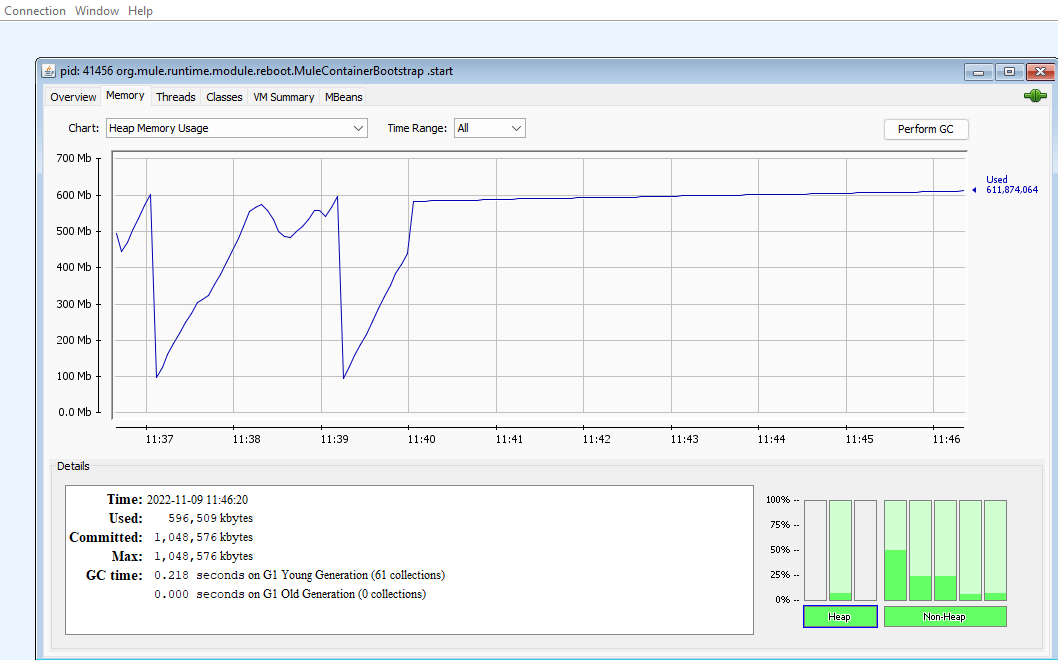
2. Full Streaming Metrics:
- 10M Records
- Heap Size: 1GB
- Streaming: Yes
- Process timing: 3 minutes
- Testing Metrics:

Code:
<?xml version="1.0" encoding="UTF-8"?> <mule xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd http://www.mulesoft.org/schema/mule/ee/core http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd"> <file:config name="File_Config" doc:name="File Config" doc:id="de7a47ca-8d15-4ddd-897d-6814acb68101" > <file:connection workingDir="C:\Downloads\a_sample_test_streaming\input\" /> </file:config> <file:config name="File_Config1" doc:name="File Config" doc:id="93ad232f-99b5-4654-ba49-1c9708ad695f" > <file:connection workingDir="C:\Downloads\a_sample_test_streaming\output\" /> </file:config> <http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" doc:id="608b8176-7c12-4098-a334-05e89504b46f" > <http:listener-connection host="0.0.0.0" port="8081" /> </http:listener-config> <flow name="sample_app_streaming_full_streaming_Flow" doc:id="a88d073e-b3b8-45f2-82d5-955772212cab" > <http:listener doc:name="Listener" doc:id="cf3b94dd-9e24-4a48-a0d8-062500b2d287" config-ref="HTTP_Listener_config" path="/test_streaming"/> <logger level="INFO" doc:name="Logger" doc:id="75cd6022-6982-4038-871b-abdbe5a1768d" message='#["start of the flow"]'/> <file:read doc:name="Read" doc:id="65f4313d-0763-44c4-be72-025c73fe62f9" config-ref="File_Config" path="input.csv"> <non-repeatable-stream /> </file:read> <ee:transform doc:name="Transform Message" doc:id="2609318a-e0c4-4a77-ae05-583c23a0c329"> <ee:message> <ee:set-payload><![CDATA[%dw 2.0 @StreamCapable() input payload application/csv output application/json deferred=true --- payload]]></ee:set-payload> </ee:message> </ee:transform> <file:write doc:name="Write" doc:id="4ffd10f8-5e1d-4f9e-8b56-a0154f22b84a" config-ref="File_Config1" path='#["output" ++ uuid() ++ ".json"]' mode="CREATE_NEW"/> <logger level="INFO" doc:name="Logger" doc:id="8ca51dcd-e669-41d4-961d-1f27c6754f6c" message='#["end of the flow"]'/> </flow> <flow name="sample_app_streaming_partial_streaming_flow" doc:id="ee465e85-3ffd-479f-a5b7-cf2200e3fe25" > <http:listener doc:name="Listener" doc:id="05c809b1-86ac-4e65-aa1d-493636941311" config-ref="HTTP_Listener_config" path="/test_streaming/for-each"/> <logger level="INFO" doc:name="Logger" doc:id="75cd6022-6982-4038-871b-abdbe5a1768d" message='#["start of the flow"]'/> <file:read doc:name="Read" doc:id="65f4313d-0763-44c4-be72-025c73fe62f9" config-ref="File_Config" path="input.csv"> <non-repeatable-stream /> </file:read> <foreach doc:name="For Each" doc:id="6f787bad-a0aa-45bf-8efa-066514a4f8e8" collection="payload" batchSize="1000"> <ee:transform doc:name="Transform Message" doc:id="2609318a-e0c4-4a77-ae05-583c23a0c329"> <ee:message> <ee:set-payload><![CDATA[%dw 2.0 @StreamCapable() input payload application/csv output application/json deferred=true --- payload]]></ee:set-payload> </ee:message> </ee:transform> <file:write doc:name="Write" doc:id="4ffd10f8-5e1d-4f9e-8b56-a0154f22b84a" config-ref="File_Config1" path='#["output" ++ uuid() ++ ".json"]' mode="CREATE_NEW" /> </foreach> <logger level="INFO" doc:name="Logger" doc:id="8ca51dcd-e669-41d4-961d-1f27c6754f6c" message='#["end of the flow"]'/> </flow> </mule> |
Execution Table Metrics Report:
sno |
records-size |
file size |
heap size |
Data format |
execution time |
with streaming |
throughput(records/second) |
output chunks file |
|
|
|
|
|
|
|
|
|
1 |
1M |
30MB |
4GB |
JSON |
30sec |
Y |
33,333 |
1 |
2 |
10M |
2GB |
4GB |
JSON |
3:59sec |
Y |
45000 |
1 |
3 |
10M |
2GB |
4GB |
JSON |
00:18:08 |
partial streaming |
9,225 |
10,000 with 1000 records chunk |
4 |
10M |
2GB |
1GB |
JSON |
0:03:46 |
y |
45k |
1 |
Mule 3 Observations:
Mule Runtime: 4.3.0
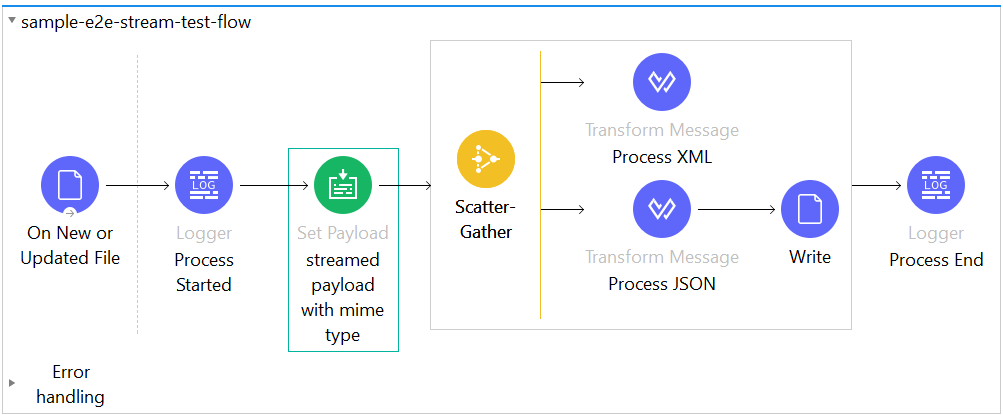
Create a prototype application to understand the e2e streaming with basic sample flow. Try to read an input CSV file through on new or updated file connector in repeatable streaming mode as we want to refer the file in concurrent method with scatter-gather.
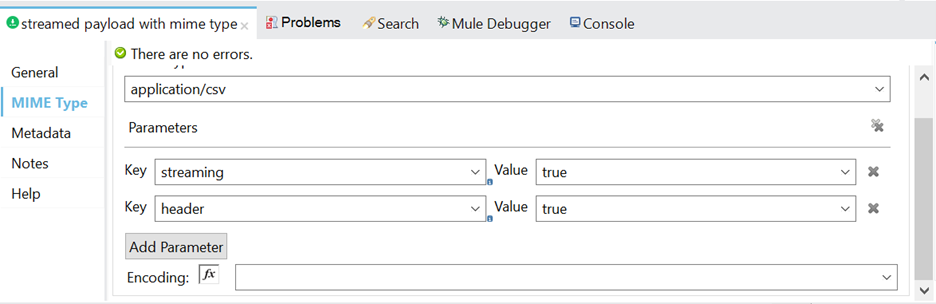
Use a set payload connector for setting a mime-type with streaming properties to achieve octet-stream or byte streaming with proper specification of mime-type for an ingested input file and add it as an additional property. After that process, the input file
concurrently with scatter-gather to get two formats of data, one is for XML format, and the other is for JSON format, and then write it into a file via the local file system.
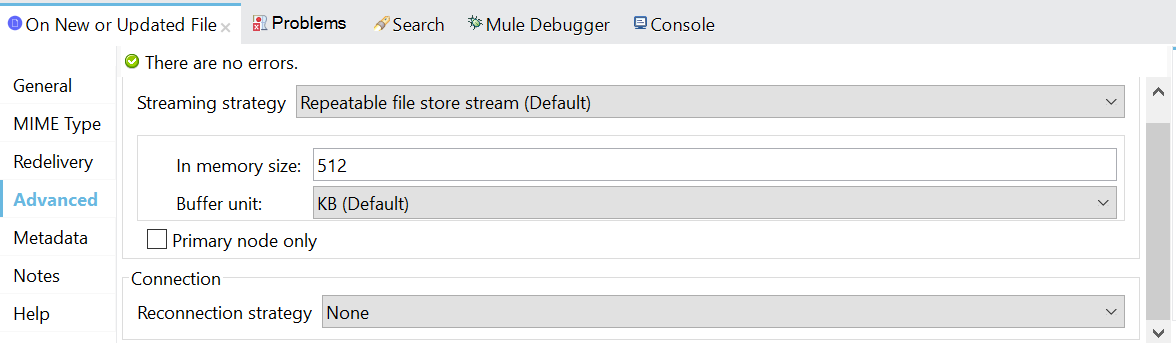
- Property configuration of On New or Update connector to read input file in repeatable stream mode.
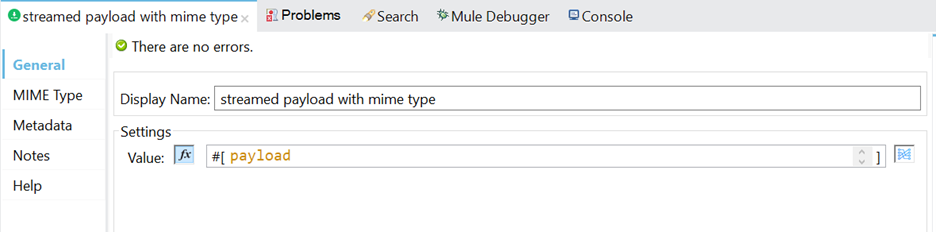
- Property configuration of set Payload connector.
- Process XML dwl file.
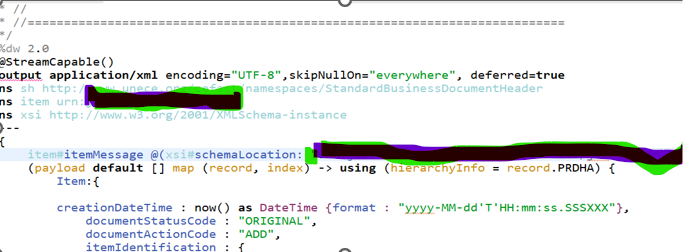
- Process JSON dwl file.
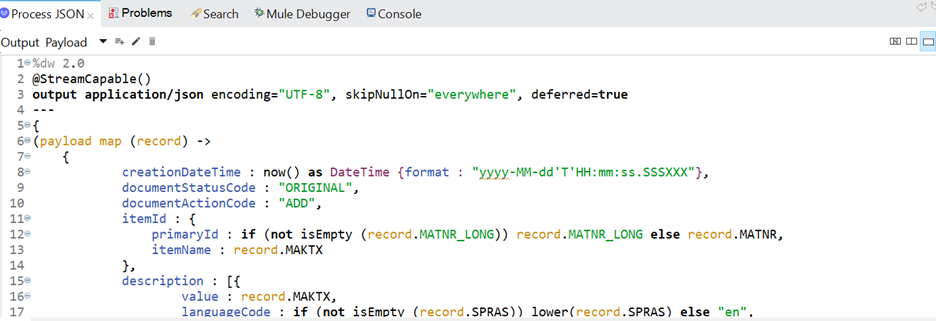
Output:
Execution time of JSON: 0:54:00 for 1M Item records
Execution time of XML: 0:01:09 for 1M Item records
Streaming With Grouping Logic
Observation:
We have tested a few entities in the Adapter which have grouping logic like Item, Actual vehicle load outbound, Production method, etc., where we have processed the data with grouping logic like grouping the data based on a few columns ex: material number or Item number, etc.
which will be applicable to the whole ingested payload. In this case, the Input payload will get loaded into memory at the time of DWL execution due to group by function, and then further transformation will get processed, which can result in back pressure in case of a huge payload that causes the application to restart abruptly or may cause more resource utilization.
Below is the Testing report:
Entity |
Total Records |
Heap Size |
File size |
Status |
Data Format |
Time Taken |
ISSUE |
Item |
1M |
2GB |
149.7MB |
FAILED |
JSON |
- |
Restart the adapter |
Item |
1M |
3GB |
|
PASSED |
JSON |
0:15:53 |
|
Item |
1M |
4GB |
|
PASSED |
JSON |
0:07:53 |
|
Item |
1M |
6GB |
|
PASSED |
JSON |
0:03:24 |
|
Item |
1M |
8GB |
|
PASSD |
JSON |
0:01:59 |
|
Streaming Without Grouping Logic
Observation:
We have also tested entities that do not have grouping logic. So, we have tested one of the entities for millions of records on the Adapter and captured a few test results below:
Entity |
Total Records |
No. of Files |
File Size |
Status |
Data Format |
Time Taken |
Throughput Record/sec |
DMDUNIT |
1M |
1 |
149.7MB |
PASSED |
JSON |
0:01:18 |
12,820 |
DMDUNIT |
10M |
1 x 10 |
|
PASSED |
JSON |
0:03:40 |
45,454 |
DMDUNIT |
20M |
1 x 20 |
|
PASSED |
JSON |
0:07:16 |
45871 |
Observation on Existing Issue
Streaming role for faulty records or error records:
1. In case of any error, the message event is not getting redirected to the error handler.
Mulesoft Product team Response:
When we use deferred=true, it will pass the stream to the next component without directly throwing the error on the Transform Message component. This is the downside of using deferred. This is expected behavior.
2. In case of any error, the first faulty record, and subsequent records get dropped.
Mulesoft Product team Response:
All the successful records are getting processed, and error records are getting skipped. Expected behavior from Mulesoft.
3. Handle error records such that they can be pushed to an API.
Mulesoft Product team Response:
If we tried to pass failed records information to another flow using the lookup function, which cannot be used with deferred mode true. Expected behavior from Mulesoft
4. Handle exceptions for error records so that exception information can be logged and stored as per business use case.
Mulesoft Product team Response:
Able to successfully log the erroneous records to the console with a custom error message from the data weave code itself.
Opinions expressed by DZone contributors are their own.
Comments