Supply Chain Security for Tools and Prompts
Tools, routers, signatures, versioned prompts, and semantic models enforce pinned bundles at runtime and emit audit-proof evidence stamps.
Join the DZone community and get the full member experience.
Join For FreeIt's very easy to talk about secure GenAI. But did you ever think about whether your agents are running only the prompts, tool schemas, router rules, and semantic models you intended — especially after many weeks of rapid iteration? It is very hard to prove this. Most teams freeze application code and container images, but they leave one thing open: the fast-moving agent configuration supply chain.
Prompts and tool definitions change more often in production. Router rules are updated daily. Tool schemas get expanded just to add one field. A semantic model gets tweaked to fix a metric edge case. These types of edits can silently weaken policy controls, enable data-exfiltration paths, or simply reduce faithfulness until you are shipping wrong answers with confidence. For governed, trustworthy AI data systems, you must treat agent configuration like top-tier software artifacts, such as reviewing, signing, versioning, promoting, and auditing, and not like loose text files in a repository.
This article shows an agent supply chain that provides cryptographic proof of what your agent is actually allowed to do versus what it actually runs, using three building blocks: signing, versioning, and attestation.
Here, the goal is operational security — not security theater. What I mean is that when you are asked questions like, “How do you know this answer was compliant?” you can immediately point to a chain of trust, not a hope or a log file.
Why This Is a Real Supply Chain Problem
Traditionally, supply chain security focuses on code and dependencies. But in agentic systems, there is a different kind of dependency graph:
- Tool schemas such as OpenAPI, JSON Schema, or function specs
- Semantic models such as metrics, row filters, and joins
- Prompt templates
- Router rules (when to call SQL vs. retrieval vs. escalation)
- Retrieval indexes and embedding pipelines (what can be retrieved and by whom)
- Guardrail policies such as PII rules, allow/deny lists, and output constraints
Most of the time, these artifacts are stored outside the main deployment pipeline and edited by multiple people — engineers, analysts, platform teams, and others. They are sometimes updated through admin UIs and frequently tested informally. This is the perfect recipe for shadow changes that bypass review.
A Failure Story
Imagine a BI agent that answers, “What’s the revenue in Q4 for region X?” It uses the following:
- A tool schema for warehouse queries
- Output redaction rules for sensitive slices
- A semantic model mapping revenue to a governed metric
- Router rules that force KPI questions through the semantic layer
Now imagine a small change occurs in production:
- Router rules are updated to use raw SQL when the semantic layer times out
- The tool schema gets an additional endpoint,
run_sql_raw(sql_text), for troubleshooting - The prompt template is tweaked to try harder when blocked by policy
No malware. No exploit. Just configuration drift.
Suddenly, the agent has a path around governance, and you might not notice until a user asks the wrong question. This is a supply chain attack surface because the change can be incidental, insider-driven, or induced through social engineering: “Can you add this tool quickly? It’s urgent.”
Agent Configuration as a Signed Release
The core idea is to ship agents as a signed configuration release, meaning the runtime can execute only configurations that are cryptographically signed and approved.
A release is a bundle containing prompt templates, tool schemas, router rules, tool allowlists, policy prompts, semantic models, and retrieval configurations such as indexes, namespaces, and guardrail policies.
Each release has an immutable version, a signature, and a set of attestations.
Architecture
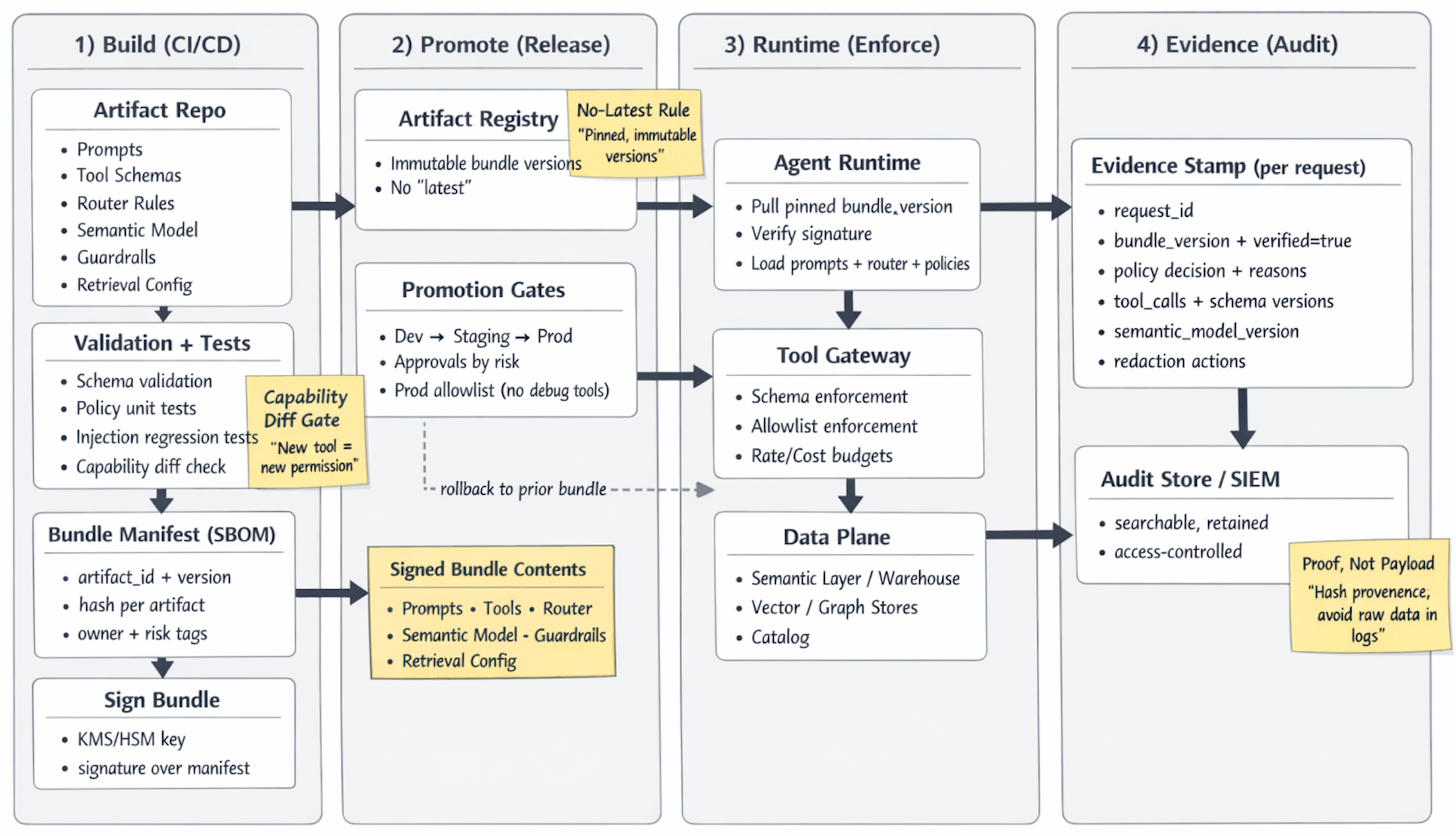
Agent Supply Chain SBOM Checklist
These are must-have artifacts.
A. Artifact Inventory
- Router rules and fallback logic
- Guardrail policies
- Tool schemas
- Prompt templates
- Evaluation suites
- Semantic models, metrics, and join contracts
- Retrieval configurations and index namespaces
B. Metadata Required for Each Artifact
- Owner
- Version
- Capability tags
- Artifact ID
- Content hash
- Review policy
- Risk level
C. Checks Required Before Signing
- Injection regression tests
- Capability diff checks
- Least-privilege checks
- Schema validation
- Policy unit tests
- Faithfulness checks
D. Promotion Controls
- Rollback by bundle version
- Dev → staging → prod promotions with approvals
- Break-glass policy
- Production forbids debug tools and raw SQL endpoints
E. Runtime Evidence
- Policy decisions logged
- Redaction actions recorded
- Tool calls match signed schemas and allowlists
- Bundle signature verified
- Retrieval provenance recorded
- Semantic model version recorded
The Three Controls That Catch Most Real-World Failures
1. Capability Diffs (Treat Tools like Permissions)
The most dangerous changes are capability expansions, not prompt edits. When a tool gains a new parameter that broadens scope, a new tool appears, a router fallback introduces a bypass, or a tool moves from read to write, fail the build or require extra approvals. This single control prevents a shocking number of accidental backdoors.
2. The “No Latest” Rule
Agents should never load the latest prompt, semantic model, or tool schema. Pinning to a single bundle version makes behavior deterministic and debuggable.
3. Environment Allowlists
Production should have stricter rules than development. In production, force KPI questions through the semantic layer, forbid raw SQL tools, lower retry budgets, restrict retrieval namespaces, and cap multi-hop exploration. If you allow development capabilities in production, you will eventually regret it.
Rollout Plan Without Slowing the Team
You can follow a phased approach to roll this out. You don't need a “big rewrite.”
Phase 1: Inventory and versioning
- Create immutable bundle versions
- Move prompts, tools, router rules, and models into a repo
- Enforce “no latest” at runtime
Phase 2: Signing
- Sign the bundle manifest
- Verify signatures at runtime before loading
Phase 3: Evidence stamps
- Build a dashboard showing which bundle served which traffic
- Emit bundle version, policy decisions, and tool-call metadata per request
Phase 4: Policy-based approvals
-
Automatically require approvals for capability diffs and high-risk changes
Conclusion
Governed AI needs governed artifacts. When incidents are finally traced, nothing “mystical” happened. The LLM didn’t suddenly become unsafe. We allowed the agent’s behavior to change outside a controlled release.
Once prompts, tools, semantic models, and routers are treated as supply chain artifacts, the conversation with security and governance changes overnight. You stop saying “we think it’s safe” and start saying “this is the chain of trust.”
If you are building analytics agents in high-stakes or regulated environments, this is the difference between a demo that impresses and a system that endures: proving what ran, making rollbacks boring, and shipping agent behavior like software.
Opinions expressed by DZone contributors are their own.
Comments