Tackling Technology Challenges for Social Networking Applications With TiDB
Discuss some features and optimizations of Distributed SQL databases that help optimize social network benchmark performance.
Join the DZone community and get the full member experience.
Join For FreeRecently, researchers at UC Berkeley published TAOBench, an end-to-end benchmark for social network workloads based on the traces collected from TAO, the distributed database for Meta. Among the typical data operations in social network applications, 99.7% are read, while only 0.2% are write and 0.01% are write transactions. Some other findings include:
- Transaction hotkeys are often co-located.
- Read and write hotspots appear on different keys.
- Contention can result intentionally.
All these characteristics of social network application workloads pose special challenges.
In this article, we will share the typical technological challenges faced by social network applications. Based on the findings from TAOBench, we will also discuss some features and optimizations of Distributed SQL databases that help optimize social network benchmark performance.
The Underlying Technical Challenges of Social Networking Applications
Social network applications allow users to share information, such as text, photos, videos, and links, and to interact with each other through various features, such as messaging, forums, and groups. These objects and features work together to describe relationships. As a user of a social application, you will have many needs that pose data challenges:
- You don't want unauthorized people to see your posts, but you do want people relevant to you to see them.
- You want your posts visible immediately, not delayed for hours.
- You don't want to miss replies that come in late. Late replies also confuse users.
- You want to access the information anytime, anywhere.
The underlying technology challenges of social network applications include scalability, privacy, security, and data management.
- Scalability: This is the ability of a system to handle an increasing amount of traffic and data without becoming slow or unresponsive. Social network applications must handle large amounts of data and traffic: they often have millions of users who are constantly generating and accessing data.
- Privacy and security: These are vital for social network applications. These applications often contain sensitive personal information, such as user profiles, messages, and connections, and they need to protect this information from unauthorized access and disclosure.
- Data management: Applications need to be able to efficiently store, process, and retrieve large amounts of data while also ensuring data integrity and availability.
All these needs are even more challenging at hyper-scale—a scale that increases with time. As the TAO paper mentions, "A single Facebook page may aggregate and filter hundreds of items from the social graph…. It must be efficient, highly available, and scale to high query rates."
How Do Distributed SQL Databases Fit?
To handle the high volume of data and traffic that social networks generate, database systems must be able to scale horizontally, using multiple servers and other resources to distribute the workload and improve performance.
In addition to scalability, social network databases must be able to support fast and efficient querying to provide users with a smooth and responsive experience. This involves using specialized indexing and data structures, as well as complex query optimization algorithms.
Distributed SQL databases are designed to handle large amounts of data and traffic and can be easily scaled horizontally across multiple servers and other resources. They may also offer features such as high availability, fault tolerance, and flexible data modeling, which can be useful for social network applications.
Indications in the TAOBench Test
In the TAOBench test, a UC Berkeley scholar tested several distributed cloud databases with equivalently priced infrastructure resources. The result is shown below.
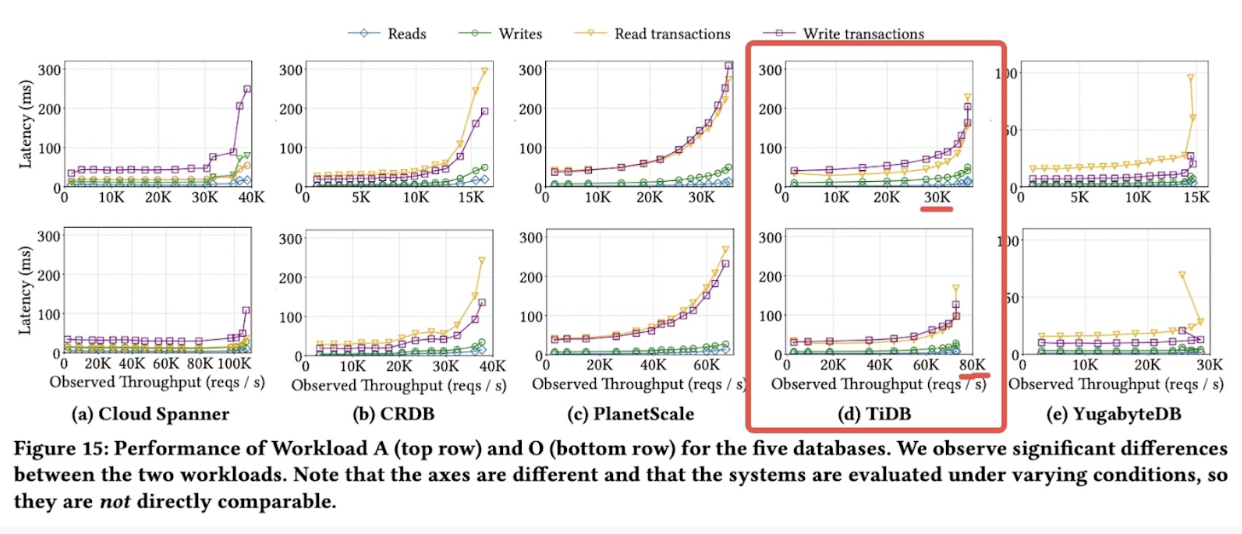
TAOBench’s benchmark on distributed databases
The figure shows that the latency of all databases increases when the throughput reaches a certain level. (Each database has different scalability and performance limits.) This is because these databases (except for Cloud Spanner) are limited to resources of equal cost. Compared to other vendors, TiDB, a distributed SQL database, demonstrates stable performance with the best scalability. This allows it to achieve higher throughput.
TiDB’s Architecture and Optimizations for Social Networking
TiDB is a Distributed SQL database that offers scalability, high availability, ACID transactions, and MySQL compatibility, making it ideal for OLTP scenarios. Today, TiDB plays a vital role in many social networking companies, such as Zhihu (China's Quora), Redbook, Pinterest, and Bilibili. Many enterprises are using TiDB to help them deal with large-scale data issues. TiDB also provides true Hybrid Transactional/Analytical Processing (HTAP) capabilities that simplify technology stacks by combining OLTP and real-time analysis.
As a Distributed SQL database, TiDB excels in TAOBench tests for performance and scaling. There are some good architectural reasons:
- Consistency and isolation: ACID and distributed transaction support based on Percolator
- High availability: data replicas based on Raft
- High throughput: horizontal elastic, scalable nodes to support Multi-write
- Relational data access: MySQL compatibility
- Ability to handle hotspot issues: Auto split and rebalance with the data region
In addition, certain aspects of TiDB's design make it well-suited for networking applications.
Auto Dynamic Sharding and Rebalancing
As the TAOBench paper says, "Transaction hotkeys are often colocated." The hot spot issue is a difficult one in social networking applications.
In TiDB, the fundamental data storage unit for management and distribution is called a "Region.” Regions can be split and merged based on the amount of data they manage and can be scheduled to move between nodes.
Typically, data is distributed evenly across all storage nodes, and TiDB automatically balances the resources of each store based on the load. A storage node’s CPU and disk usage may become a bottleneck. TiDB’s Placement Driver (PD) estimates the load of the data regions based on the statistics such as the number of requests and amount of data written and synchronized. PD can schedule the balancing operation accordingly.
Data region rebalancing with PD
In a social network, hotspots may be concentrated within one data Region. TiDB samples a data region to analyze the distribution of workload. It then finds a suitable split point to allow the hot data Region to split into smaller Regions. After splitting, the hotspot balancing scheduler can move the hotspots into different nodes. With these two scheduling features, TiDB can fully utilize the distributed nature of storage, IO, and computing. This keeps performance stable — even in cases of severe hot-spotting.
Hotspots processing in TiDB
Write Transaction Optimization for Colocated Participants
Distributed systems that support cross-row and cross-node transactions typically use 2-phase-commit (2PC) to achieve atomicity. TiDB's 2PC implementation is based on Percolator. In TiDB’s Percolator model, a transaction is considered committed once the primary key is committed. This requires at least two network round trips. However, not all transactions require 2PC to achieve atomicity. If a transaction only involves data hosted on one node, atomic commits can be achieved with only one round of RPCs.
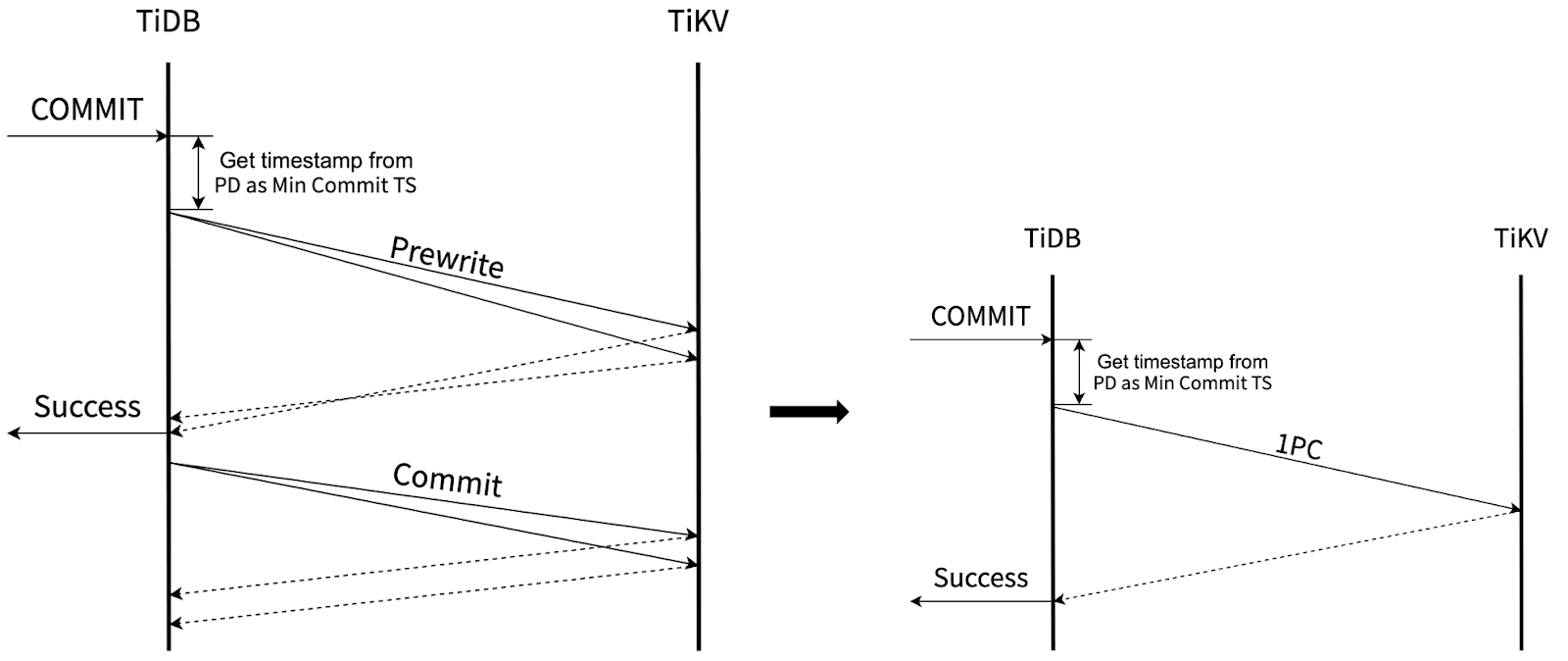
TiDB’s optimized process for write transactions
The TAOBench paper says, "Hotkeys in write transactions tend to be colocated on the same shards." This optimization in TiDB effectively reduces the number of transaction commit phases. In the test results, we observed that Commit Operations per Second (OPS) dropped from 6,000 to less than 1,000, indicating that most 2PCs were reduced to 1PC. However, since writes in TAOBench only account for approximately 0.2% of all traffic, the overall Queries per Second (QPS) only saw a slight improvement.
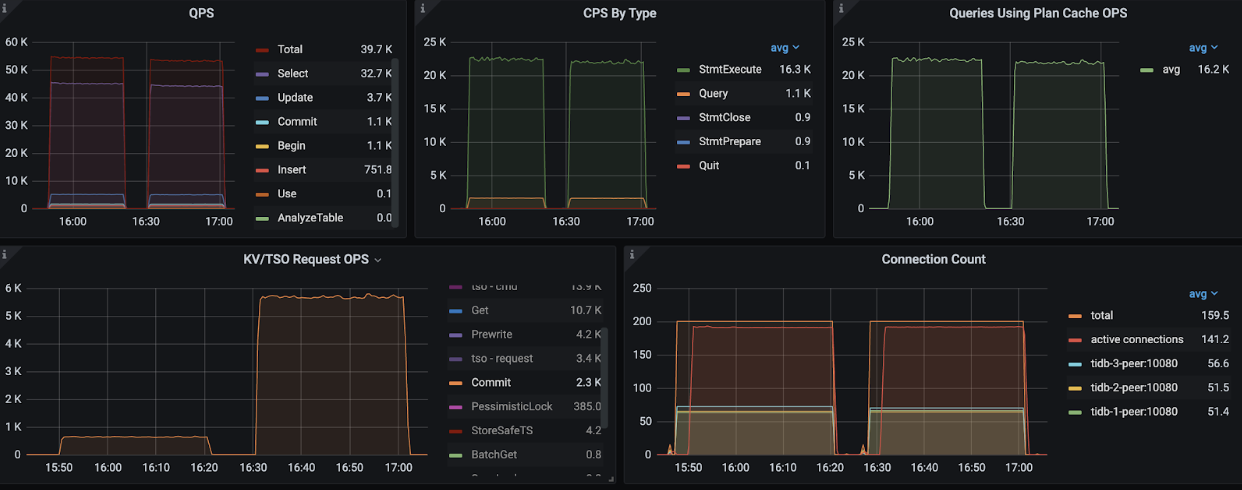
Commit performance observed in TAOBench
A potential topic for future optimization is using data affinity to colocate as much relevant data as possible in one data region. This can reduce the overhead of 2PC and improve performance.
Plan Cache for Read-Heavy Workload
TiDB supports plan cache for SQL statements. This allows it to skip the optimization phase, which includes rule-based optimization and cost-based optimization. For read-heavy workloads, skipping these processes saves computing resources and improves performance. Based on our testing, enabling the plan cache improves QPS by about 10.5%.
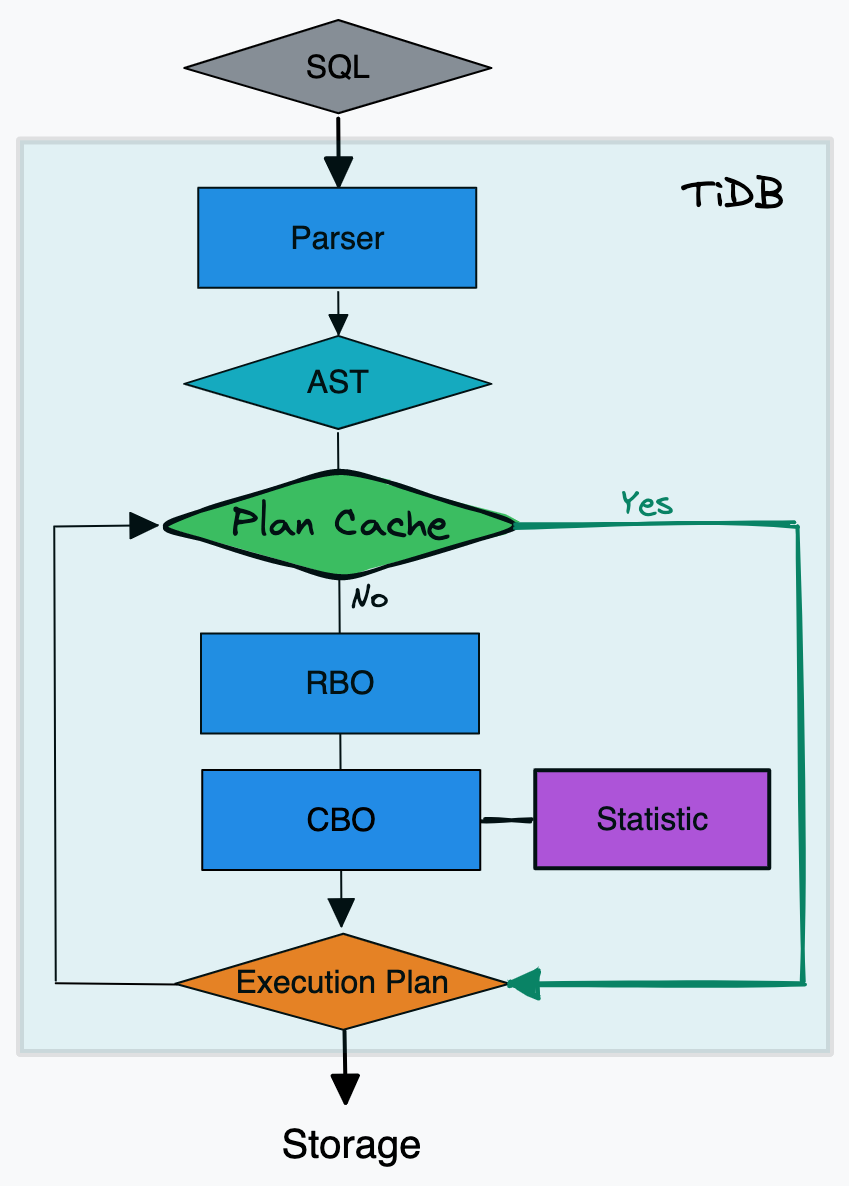
Plan cache in TiDB
Semi-Auto-Tuning Garbage Collection
For any data-intensive system, garbage collection (GC) is a resource-intensive background task. The GC threshold parameters can significantly affect the system's performance, particularly when it consumes a lot of CPU resources. Go GC auto-tuning, an optimization proposed by an Uber engineer, can reduce unnecessary GC operations and save overhead on frequent lightweight operations. TiDB adopted this optimization, which significantly improved throughput for TAOBench and many other Online Transactional Processing (OLTP) workloads. However, there’s a tradeoff. Although this method reduces unnecessarily frequent GC, in extreme cases, it may increase the risk of out-of-memory (OOM) crashes. Results can be found in the following graphic.
Continuous Iteration and Evaluation
In addition to the features and optimizations we’ve discussed, the evolution of the product itself is essential to address scalability challenges. TiDB iterates quickly and often, with a release cadence of one to two months. To capture the performance gains across different versions, the team also set up TAOBench to compare the performance of TiDB 6.4 with TiDB 5.0. As indicated in the chart, we achieved a 30% QPS improvement over the past year and a half.

TiDB’s overall performance comparison on TAOBench
Conclusion
Overall, the workload of a social network database can be quite challenging. It requires advanced technologies and techniques to manage and optimize the data to give users a seamless and enjoyable experience. To learn more, you can watch this Meetup playback.
Opinions expressed by DZone contributors are their own.
Comments