Overview
Scalability, High Availability, and Performance
The terms scalability, high availability, performance, and mission-critical can mean different things to different organizations, or to different departments within an organization. They are often interchanged and create confusion that results in poorly managed expectations, implementation delays, or unrealistic metrics. This Refcard provides you with the tools to define these terms so that your team can implement mission-critical systems with well understood performance goals.
Scalability
It's the property of a system or application to handle bigger amounts of work, or to be easily expanded, in response to increased demand for network, processing, database access or file system resources.
Horizontal scalability
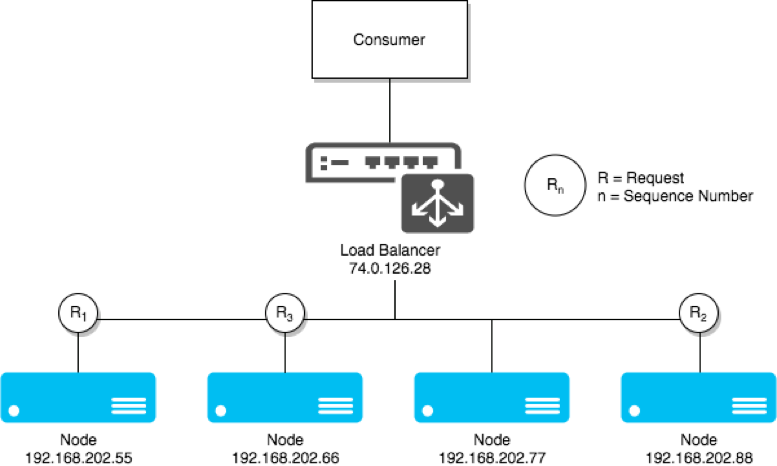
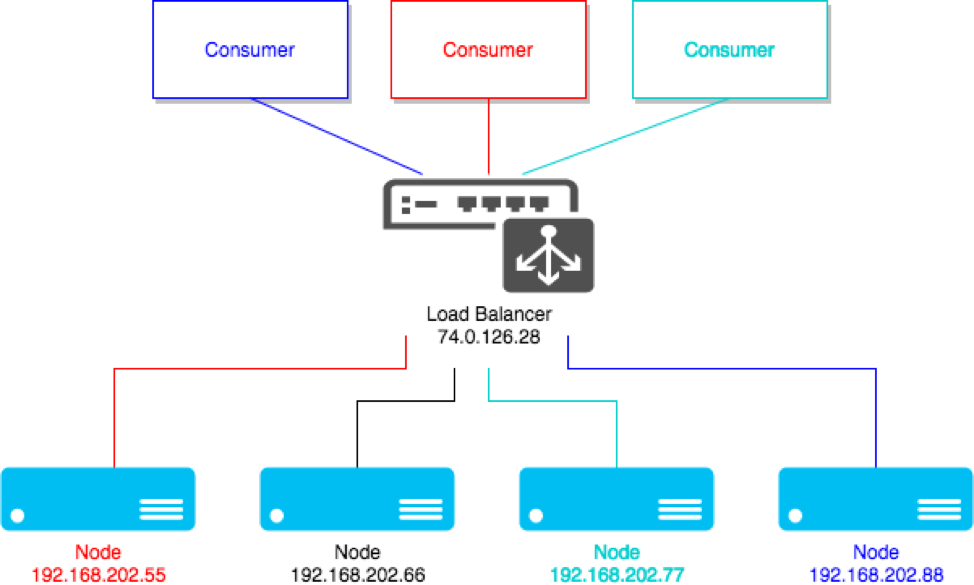
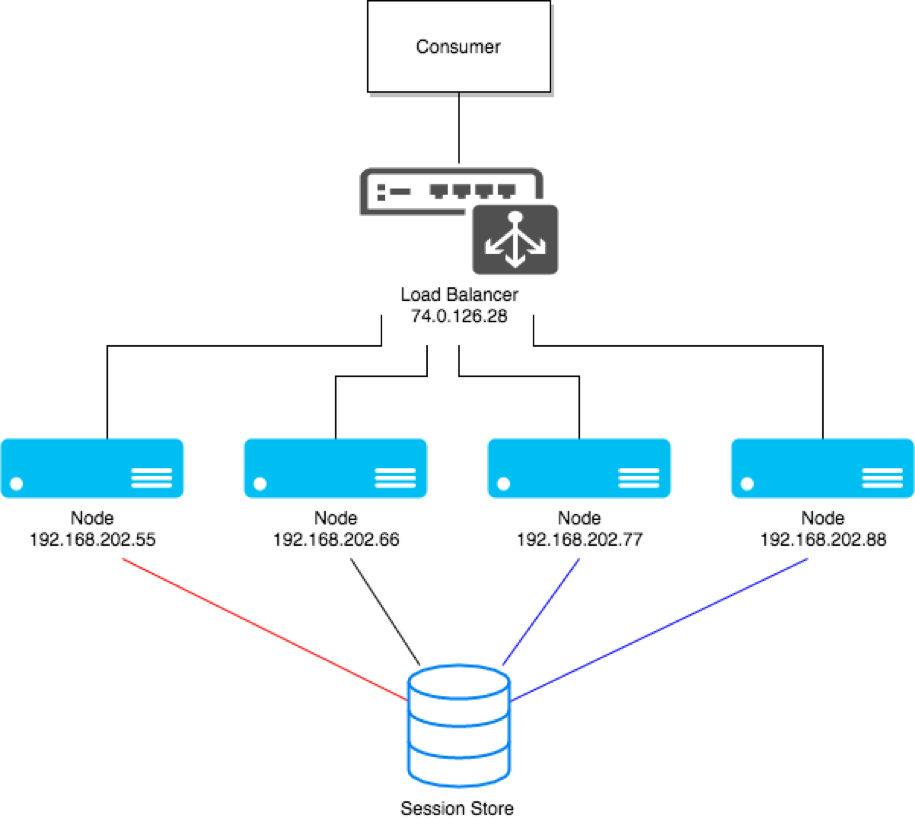
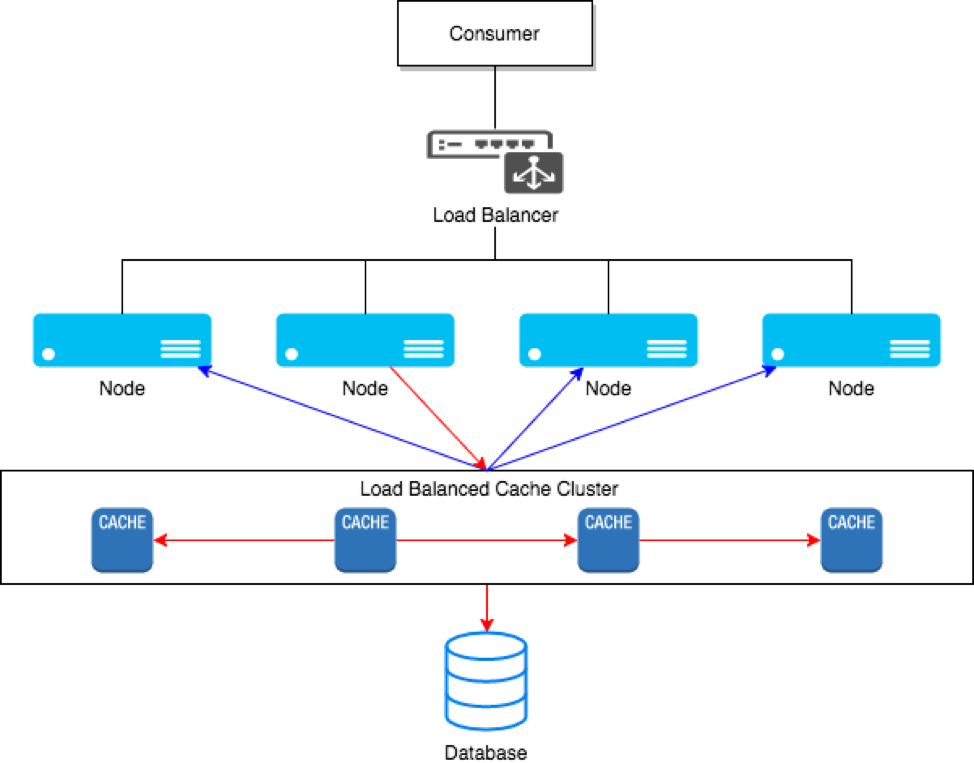
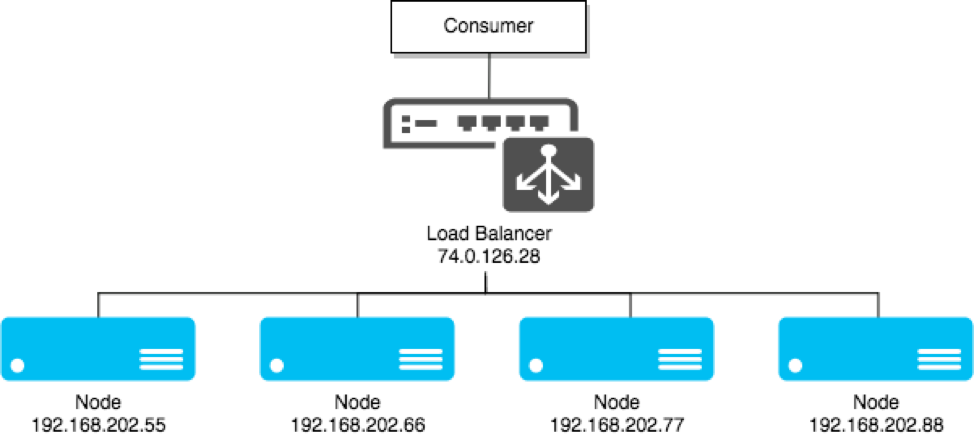
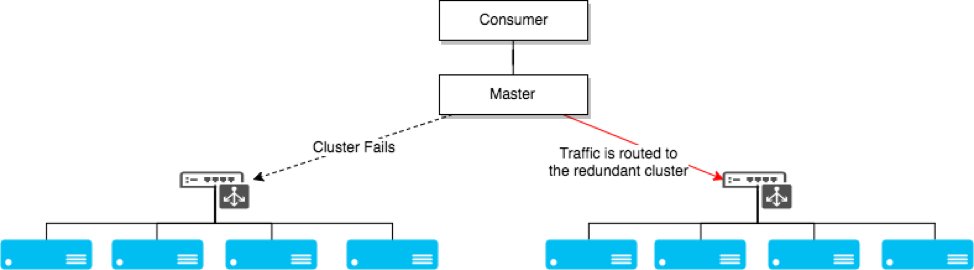
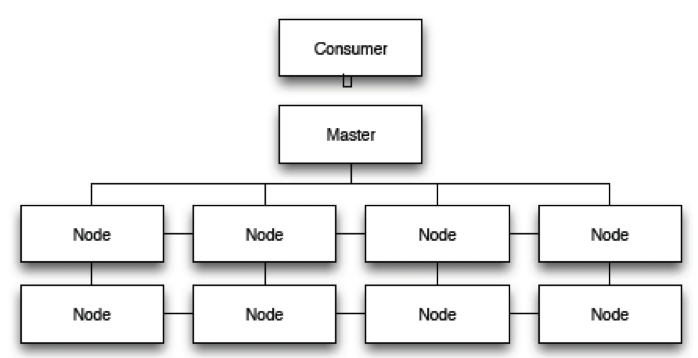
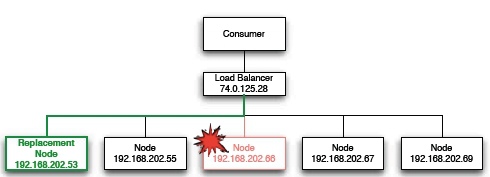
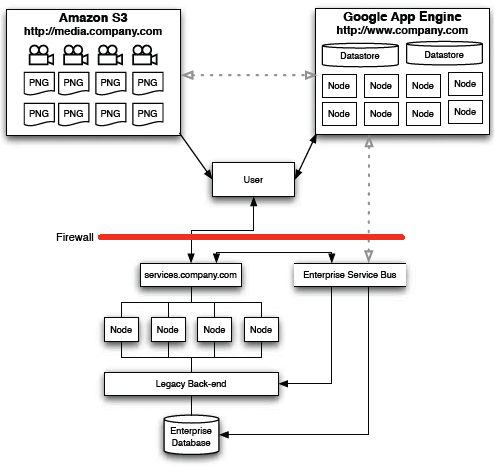
A system scales horizontally, or out, when it's expanded by adding new nodes with identical functionality to existing ones, redistributing the load among all of them. SOA systems and web servers scale out by adding more servers to a load-balanced network so that incoming requests may be distributed among all of them. Cluster is a common term for describing a scaled out processing system.
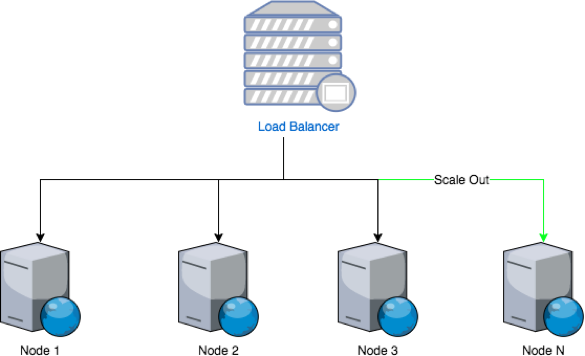
Figure 1: Clustering
Vertical scalability
A system scales vertically, or up, when it's expanded by adding processing, main memory, storage, or network interfaces to a node to satisfy more requests per system. Hosting services companies scale up by increasing the number of processors or the amount of main memory to host more virtual servers in the same hardware.
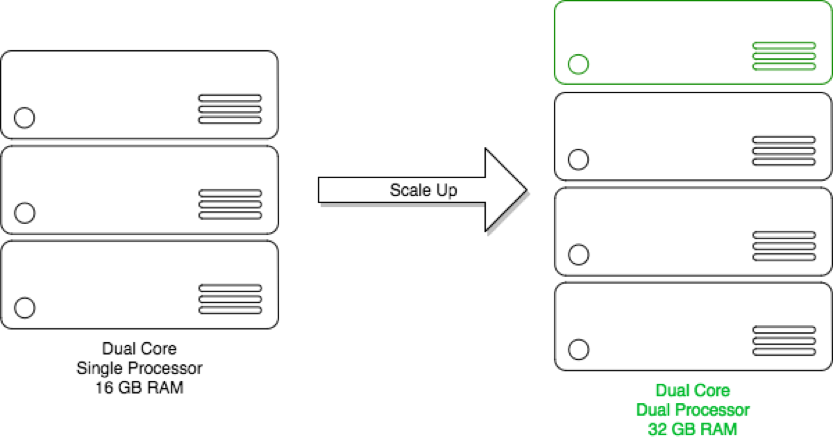
Figure 2:Virtualization
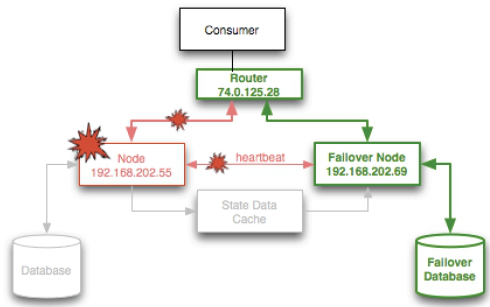
High Availability
Availability describes how well a system provides useful resources over a set period of time. High availability guarantees an absolute degree of functional continuity within a time window expressed as the relationship between uptime and downtime.
A = 100 – (100*D/U), D ::= unplanned downtime, U ::= uptime; D, U expressed in minutes
Uptime and availability don't mean the same thing. A system may be up for a complete measuring period, but may be unavailable due to network outages or downtime in related support systems. Downtime and unavailability are synonymous.
Measuring Availability
Vendors define availability as a given number of "nines" like in Table 1, which also describes the number of minutes or seconds of estimated downtime in relation to the number of minutes in a 365-day year, or 525,600, making U a constant for their marketing purposes.
| Availability % | Downtime in Minutes | Downtime per Year | Vendor Jargon |
| 90 | 52,560.00 | 36.5 days | one nine |
| 99 | 5,256.00 | 4 days | two nines |
| 99.9 | 525.60 | 8.8 hours | three nines |
| 99.99 | 52.56 | 53 minutes | four nines |
| 99.999 | 5.26 | 5.3 minutes | five nines |
| 99.9999 | 0.53 | 32 seconds | six nines |
Table 1: Availability as a Percentage of Total Yearly Uptime
Analysis
High availability depends on the expected uptime defined for system requirements; don't be misled by vendor figures. The meaning of having a highly available system and its measurable uptime are a direct function of a Service Level Agreement. Availability goes up when factoring planned downtime, such as a monthly 8-hour maintenance window. The cost of each additional nine of availability can grow exponentially. Availability is a function of scaling the systems up or out and implementing system, network, and storage redundancy.
Service Level Agreement (SLA)
SLAs are the negotiated terms that outline the obligations of the two parties involved in delivering and using a system, like:
- System type (virtual or dedicated servers, shared hosting)
- Levels of availability
- Minimum
- Target
- Uptime
- Network
- Power
- Maintenance windows
- Serviceability
- Performance and Metrics
- Billing
SLAs can bind obligations between two internal organizations (e.g. the IT and e-commerce departments), or between the organization and an outsourced services provider. The SLA establishes the metrics for evaluating the system performance, and provides the definitions for availability and the scalability targets. It makes no sense to talk about any of these topics unless an SLA is being drawn or one already exists.
Elasticity
Elasticity is the ability to dynamically add and remove resources in a system in response to demand, and is a specialized implementation of scaling horizontally or vertically.
As requests increase during a busy period, more nodes can be automatically added to a cluster to scale out and removed when the demand has faded – similar to seasonal hiring at brick and mortar retailers. Additionally, system resources can be re-allocated to better support a system for scaling up dynamically.