Taking the Fear Out of Migrations
When introducing a new feature, we aim to seamlessly transition from the old to the new as quickly as possible by changing our existing data model.
Join the DZone community and get the full member experience.
Join For FreeThere are few things in software where I’d advocate a ‘one true way,’ but the closest I come is probably migrations. There’s a playbook that we follow to give us the best odds of a smooth switchover:
-
Make the new data models.
-
Write to both the old and the new model.
-
Start reading from the new model.
-
Drop the old data model.
A Worked Example
status which, for each incident, contained one of those four strings. We wanted to move to a world where customers could choose their own statuses, both renaming them and choosing how many they wanted. So how did we do this?
1. Make the New Data Models
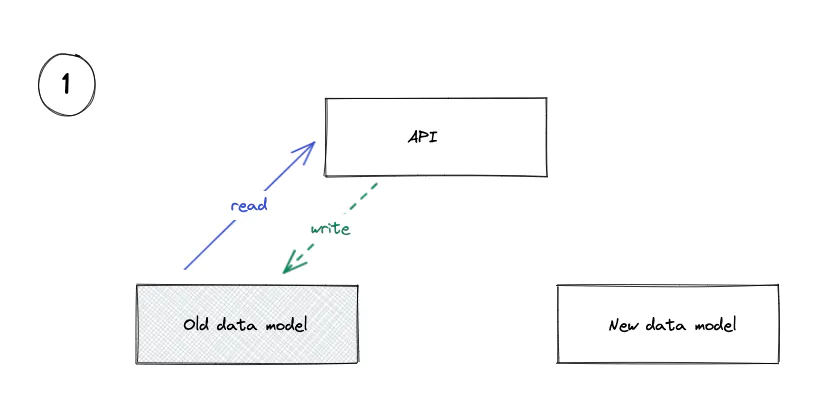
We’ve got to agree on the target data model: what the new world will look like. We need a new table to represent the statuses configured against each organization: incident_statuses, and a column on our incidents table to store which status it’s currently in: incident_status_id.
Migrating is going to take us some time, so we’d want to have fairly high confidence in the new model before we start work to avoid wasted effort.
public.incidents (
id text not null
organisation_id text not null
incident_status_id text not null
...
)
public.incident_statuses (
id text not null
organisation_id text not null
name text not null
description text not null
)IncidentStatus in our codebase.
create table incident_statuses (
...
);
alter table incidents add column incident_status_id text not null references incident_statuses(id);
2. Write to Both the Old and the New Model
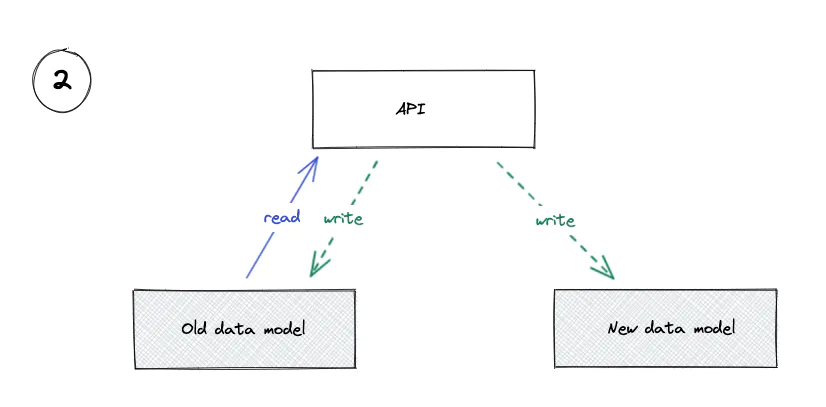
Backfill any Dependent Data Models
This isn’t always necessary: it depends on the migration that you’re doing.
In our case, all our customers have a single configuration currently represented in code (in an enum investigating, fixing, monitoring, closed). We can represent this configuration in our new incident_statuses table by creating four rows for each organization.
This is low risk: we can take our time to run the backfill and verify that it’s worked as expected. Nothing is reading from this data yet, so it’s easy for us to change our minds (e.g., if we decide to change the descriptions of a particular status).
We need to do this first as we’ll be relying on foreign keys in our database—if these rows don’t exist, we can’t refer to them elsewhere.
Write to the New Data Model
fixing, we make two changes:
update incidents set status='fixing' where id='I123';
update incidents set incident_status_id = (
select id from incident_statuses where name='Fixing'
) where id='I123';incident_status_id value. Again, this is low risk: we can take our time to verify that this is working as expected and make changes here without causing production impact, as nothing is reading from this column.
Backfill the Existing Data
incident_status_id. We can go through each incident, find the corresponding incident_status, and update the column.
This is still low risk: again, we can take whatever time we need to verify the results and can run the backfill multiple times if we find that there’s a bug (provided you make your backfill re-runnable, which you definitely should!)
3. Start Reading From the New Model
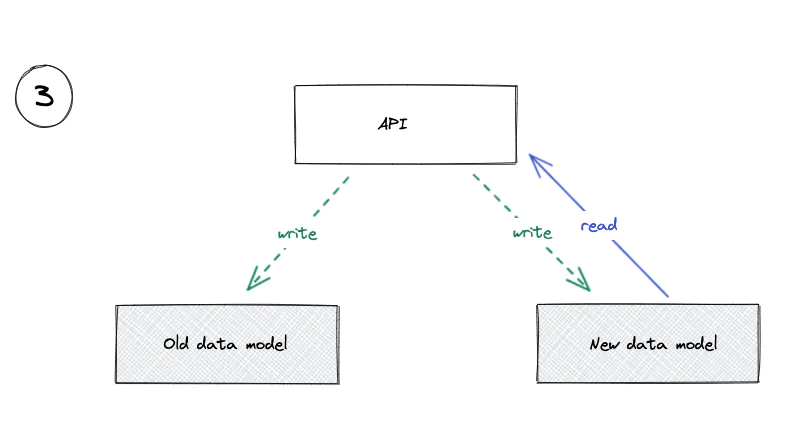
Read From Both Sources and Compare
Depending on your risk appetite and the complexity of the change, you might be able to skip straight to the next step, or (at the other extreme) you might run this comparison for a number of weeks.
Now that all our data is represented in both the old and the new data model, we can start reading from both and check if they match. If we ever see them disagree, we can log an error that’ll be picked up by our alerting tools. We can run this code in production for as long as we need to gain confidence in our system.
In our case, we’d be reading incident.status and incident.incident_status_id and making sure they’re giving us the same answer.
Only Read From the New Model
Once you’re confident that your new model has the correct data, we can start using the new model as our ‘source of truth.’ That means when someone asks us what status an incident is, we use incident.incident_status_id to tell us. When someone asks us to list all the statuses (e.g., to show in a dropdown), we look for all the incident_statuses owned by that organization.
This should be the scary moment: if your new model isn’t storing the right data, it’s going to start causing issues. But as we have been able to read and compare the new and the old model, we’ve got confidence that this is now safe.
This is a great opportunity to use a feature flag—you’re still writing to both the old and the new models, so it’s easy to revert back to step five (via a feature flag) if you see any issues without causing any service interruption.
4. Drop the Old Data Model
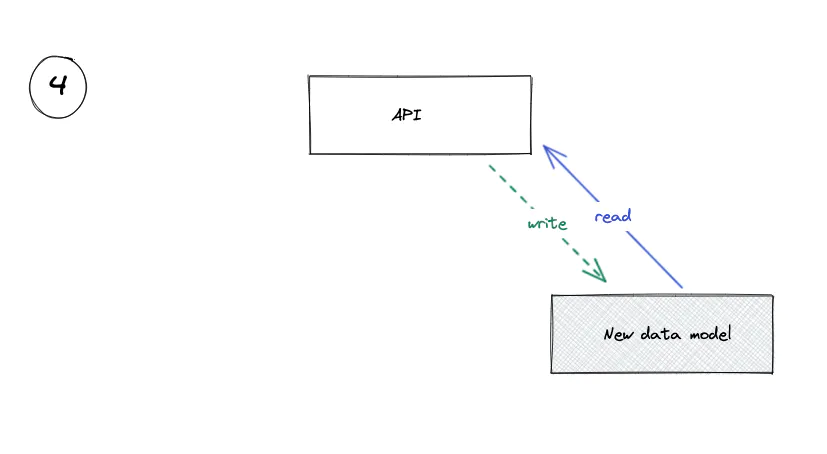
Stop Using the Old Data Model
Once we’ve been reading from the new model for a while (again, the length of time depends on context), we can drop the old data model and the code that reads from it and writes to it.
This will also make our code feel simpler again: we can just read and write to the database like we normally would.
This is the first one-way door that we’re taking: once we stop writing to the old data model, we can’t easily go back. However, it doesn’t feel scary. We’ve not been using the old data model since step five, and nothing’s gone wrong (yet), so we should be good to go.
Drop the Old Data Model
Now, there are some columns in our database that we aren’t using, and we haven’t been for a while. We should drop them so that our colleagues aren’t confused in the future.
This might have some interesting downstream implications: you should check your data pipelines to see if anything is relying on the columns!
If you’re feeling very risk-averse, you can always take a backup of the data you’re deleting. I’ve never used a backup like this, but I’ve often taken them just in case.
And…We’re Done!
We’ve now got the new data model ready and raring to go, and all our existing APIs and UIs are working as expected so that the real fun can begin.
In our case, we’ve been doing this migration to enable new functionality: customers want to rename their incident statuses. Next up, we can focus on shipping the new feature without having to worry about our existing data or functionality.
This is where we’ll build new APIs and UIs that allow our users to create, edit, and delete incident statuses. Because we’ve already got the new data model, and we’ve got confidence that it’s working, we don’t have to worry about the downstream impacts: we’re just letting customers make changes in the UI, which we can already make directly in the database.
So, What Are the Advantages of This Approach?
You Never Have to Rush
Deployments Are Less Scary
It Doesn’t Have to Take Long
You Can Parallelize Effort
-
Someone is working on the two backfills.
-
Someone is working on writing the new data model.
-
Someone is working on reading from the new data model.
-
Someone is building the new functionality enabled by the new data model.
Published at DZone with permission of Lisa Karlin Curtis. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments