How TBMQ Uses Redis for Persistent Message Storage
Learn how we use Redis to scale MQTT session persistence in TBMQ — replacing PostgreSQL and improving performance with Lua scripts and the Lettuce async client.
Join the DZone community and get the full member experience.
Join For FreeTBMQ was primarily designed to aggregate data from IoT devices and reliably deliver it to backend applications. Applications subscribe to data from tens or even hundreds of thousands of devices and require reliable message delivery. Additionally, applications often experience periods of downtime due to system maintenance, upgrades, failover scenarios, or temporary network disruptions. IoT devices typically publish data frequently but subscribe to relatively few topics or updates.
To address these differences, TBMQ classifies MQTT clients as either application clients or standard IoT devices. Application clients are always persistent and rely on Kafka for session persistence and message delivery. In contrast, standard IoT devices — referred to as DEVICE clients in TBMQ — can be configured as persistent depending on the use case.
This article provides a technical overview of how Redis is used within TBMQ to manage persistent MQTT sessions for DEVICE clients. The goal is to provide practical insights for software engineers looking to offload database workloads to persistent caching layers like Redis, ultimately improving the scalability and performance of their systems.
Why Redis?
In TBMQ 1.x, DEVICE clients relied on PostgreSQL for message persistence and retrieval, ensuring that messages were delivered when a client reconnected. While PostgreSQL performed well initially, it had a fundamental limitation — it could only scale vertically.
We anticipated that as the number of persistent MQTT sessions grew, PostgreSQL’s architecture would eventually become a bottleneck. For a deeper look at how PostgreSQL was used and the architectural limitations we encountered, see our blog post.
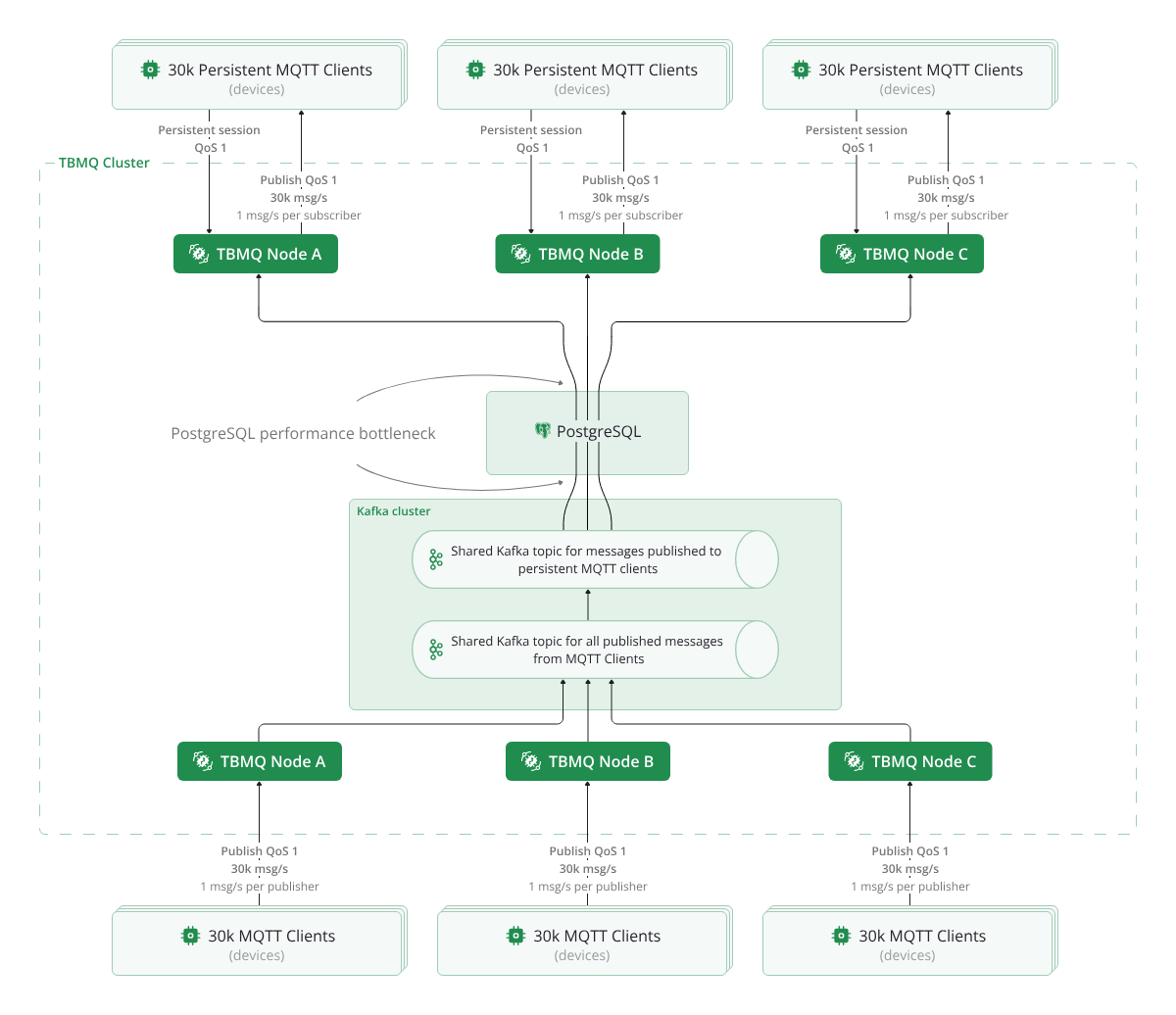
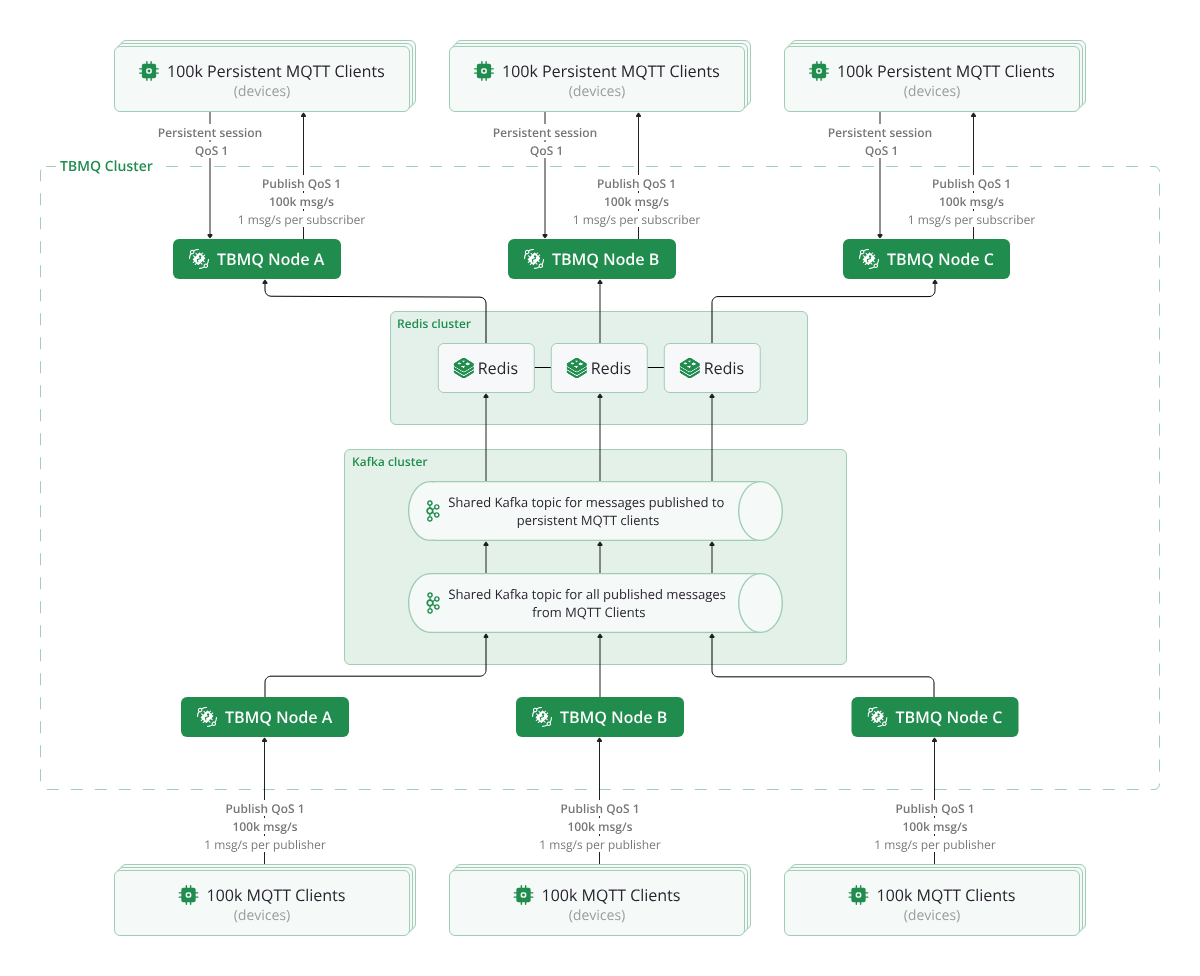
To address this, we evaluated alternatives that could scale more effectively with increasing load. Redis was quickly chosen as the best fit due to its horizontal scalability, native clustering support, and widespread adoption.
Migration to Redis
With these benefits in mind, we started our migration process with an evaluation of data structures that could preserve the functionality of the PostgreSQL approach while aligning with Redis Cluster constraints to enable efficient horizontal scaling.
Redis Cluster Constraints
While working on a migration, we recognized that replicating the existing data model would require multiple Redis data structures to efficiently handle message persistence and ordering. This, in turn, meant using multiple keys for each persistent MQTT client session.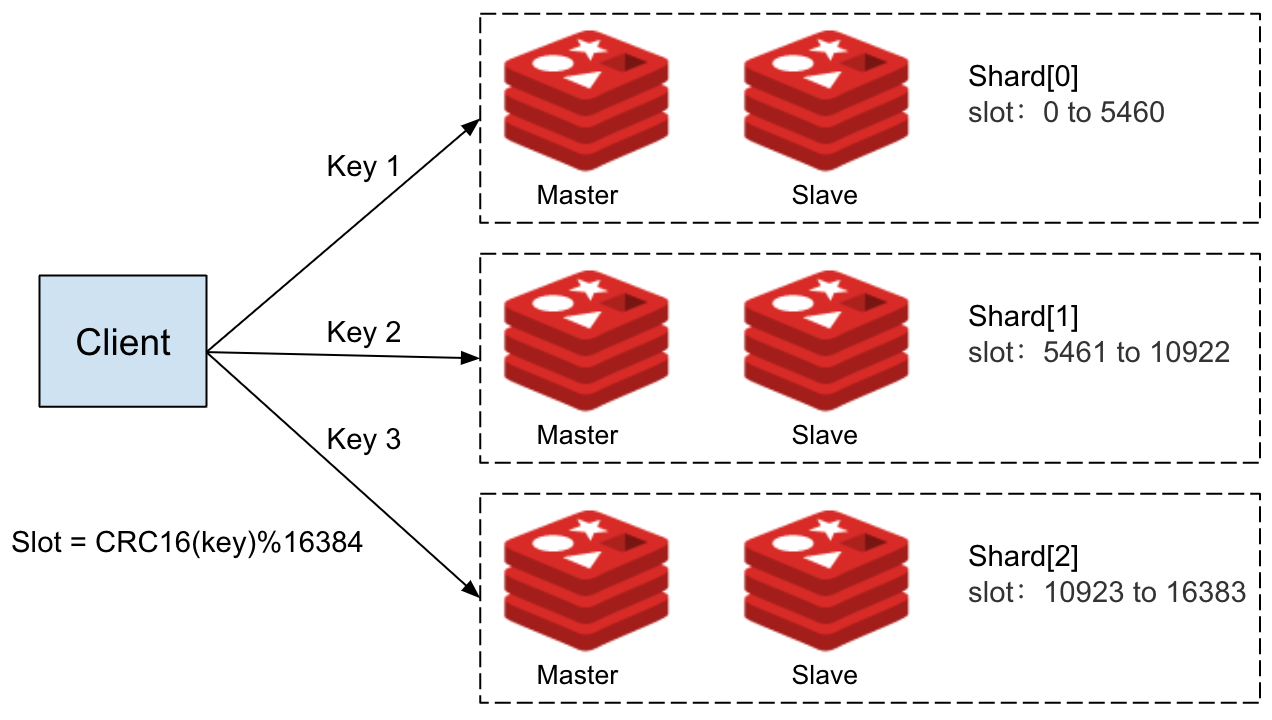
Redis Cluster distributes data across multiple slots to enable horizontal scaling. However, multi-key operations must access keys within the same slot. If the keys reside in different slots, the operation triggers a cross-slot error, preventing the command from executing. We used the persistent MQTT client ID as a hash tag in our key names to address this. By enclosing the client ID in curly braces {}, Redis ensures that all keys for the same client are hashed to the same slot. This guarantees that related data for each client stays together, allowing multi-key operations to proceed without errors.
Atomic Operations via Lua Scripts
Consistency is critical in high-throughput environments where many messages may arrive concurrently for the same MQTT client. Hashtagging helps to avoid cross-slot errors, but without atomic operations, there is a risk of race conditions or partial updates. This could lead to message loss or incorrect ordering. It is important to make sure that operations updating the keys for the same MQTT client are atomic.
Redis is designed to execute individual commands atomically. However, in our case, we need to update multiple data structures as part of a single operation for each MQTT client. Executing these sequentially without atomicity opens the door to inconsistencies if another process modifies the same data in between commands. That’s where Lua scripting comes in. Lua script executes as a single, isolated unit. During script execution, no other commands can run concurrently, ensuring that the operations inside the script happen atomically.
Based on this information, we decided that for any operation, such as saving messages or retrieving undelivered messages upon reconnection, we will execute a separate Lua script. This ensures that all operations within a single Lua script reside in the same hash slot, maintaining atomicity and consistency.
Choosing the Right Redis Data Structures
One of the key requirements for persistent session handling in an MQTT broker is maintaining message order across client reconnects. After evaluating various Redis data structures, we found that sorted sets (ZSETs) provided an efficient solution to this requirement.
Redis sorted sets naturally organize data by score, enabling quick retrieval of messages in ascending or descending order. While sorted sets provided an efficient way to maintain message order, storing full message payloads directly in sorted sets led to excessive memory usage. Redis does not support per-member TTL within sorted sets. As a result, messages persisted indefinitely unless explicitly removed. Similar to PostgreSQL, we had to perform periodic cleanups using ZREMRANGEBYSCORE to delete expired messages. This operation carries a complexity of O(log N + M), where M is the number of elements removed. To overcome this limitation, we decided to store message payloads using strings data structure while storing in the sorted set references to these keys.
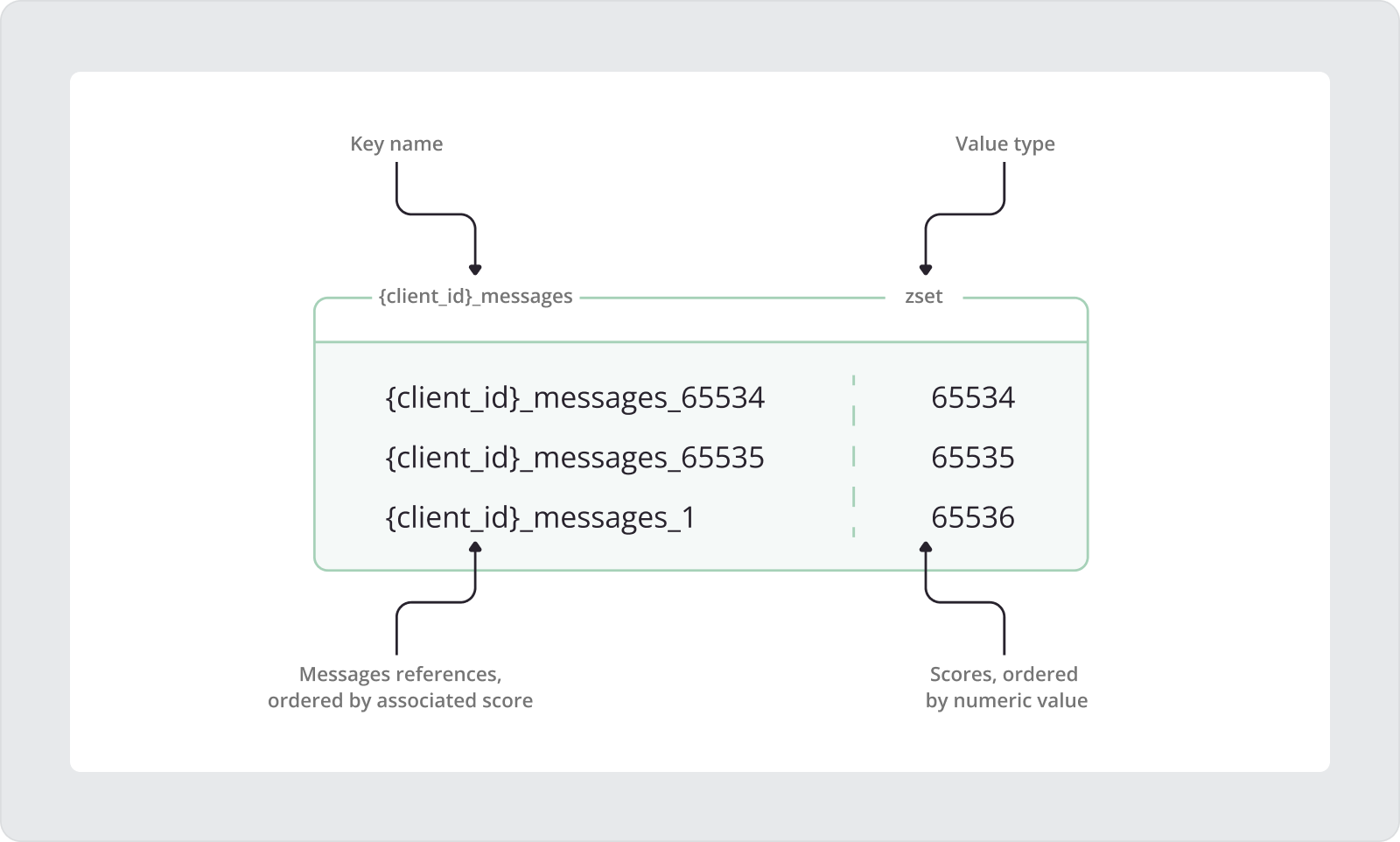
client_id is a placeholder for the actual client ID, while the curly braces {} around it are added to create a hash tag.
In the image above, you can see that the score continues to grow even when the MQTT packet ID wraps around. Let’s take a closer look at the details illustrated in this image. At first, the reference for the message with the MQTT packet ID equal to 65534 was added to the sorted set:
ZADD {client_id}_messages 65534 {client_id}_messages_65534Here, {client_id}_messages is the sorted set key name, where {client_id} acts as a hash tag derived from the persistent MQTT client’s unique ID. The suffix _messages is a constant added to each sorted set key name for consistency. Following the sorted set key name, the score value 65534 corresponds to the MQTT packet ID of the message received by the client. Finally, we see the reference key that points to the actual payload of the MQTT message. Similar to the sorted set key, the message reference key uses the MQTT client’s ID as a hash tag, followed by the _messages suffix and the MQTT packet ID value.
In the next iteration, we add the message reference for the MQTT message with a packet ID equal to 65535 into the sorted set. This is the maximum packet ID, as the range is limited to 65535.
ZADD {client_id}_messages 65535 {client_id}_messages_65535So, at the next iteration MQTT packet ID should be equal to 1, while the score should continue to grow and be equal to 65536.
ZADD {client_id}_messages 65536 {client_id}_messages_1This approach ensures that the message’s references will be properly ordered in the sorted set regardless of the packet ID’s limited range.
Message payloads are stored as string values with SET commands that support expiration (EX), providing O(1) complexity for writes and TTL applications:
SET {client_id}_messages_1 "{
\"packetType\":\"PUBLISH\",
\"payload\":\"eyJkYXRhIjoidGJtcWlzYXdlc29tZSJ9\",
\"time\":1736333110026,
\"clientId\":\"client\",
\"retained\":false,
\"packetId\":1,
\"topicName\":\"europe/ua/kyiv/client/0\",
\"qos\":1
}" EX 600Another benefit, aside from efficient updates and TTL applications, is that the message payloads can be retrieved:
GET {client_id}_messages_1Or removed:
DEL {client_id}_messages_1with constant complexity O(1) without affecting the sorted set structure.
Another very important element of our Redis architecture is the use of a string key to store the last MQTT packet ID processed:
GET {client_id}_last_packet_id
"1"This approach serves the same purpose as in the PostgreSQL solution. When a client reconnects, the server must determine the correct packet ID to assign to the next message that will be saved in Redis. Initially, we considered using the sorted set’s highest score as a reference. However, since there are scenarios where the sorted set could be empty or completely removed, we concluded that the most reliable solution is to store the last packet ID separately.
Managing Sorted Set Size Dynamically
This hybrid approach, leveraging sorted sets and string data structures, eliminates the need for periodic cleanups based on time, as per-message TTLs are now applied. In addition, following the PostgreSQL design, we needed to somehow address the cleanup of the sorted set based on the message limit set in the configuration.
# Maximum number of PUBLISH messages stored for each persisted DEVICE client
limit: "${MQTT_PERSISTENT_SESSION_DEVICE_PERSISTED_MESSAGES_LIMIT:10000}"This limit is an important part of our design, allowing us to control and predict the memory allocation required for each persistent MQTT client. For example, a client might connect, triggering the registration of a persistent session, and then rapidly disconnect. In such scenarios, it is essential to ensure that the number of messages stored for the client (while waiting for a potential reconnection) remains within the defined limit, preventing unbounded memory usage.
if (messagesLimit > 0xffff) {
throw new IllegalArgumentException("Persisted messages limit can't be greater than 65535!");
}To reflect the natural constraints of the MQTT protocol, the maximum number of persisted messages for individual clients is set to 65535.
To handle this within the Redis solution, we implemented dynamic management of the sorted set’s size. When new messages are added, the sorted set is trimmed to ensure the total number of messages remains within the desired limit, and the associated strings are also cleaned up to free up memory.
-- Get the number of elements to be removed
local numElementsToRemove = redis.call('ZCARD', messagesKey) - maxMessagesSize
-- Check if trimming is needed
if numElementsToRemove > 0 then
-- Get the elements to be removed (oldest ones)
local trimmedElements = redis.call('ZRANGE', messagesKey, 0, numElementsToRemove - 1)
-- Iterate over the elements and remove them
for _, key in ipairs(trimmedElements) do
-- Remove the message from the string data structure
redis.call('DEL', key)
-- Remove the message reference from the sorted set
redis.call('ZREM', messagesKey, key)
end
endMessage Retrieval and Cleanup
Our design not only ensures dynamic size management during the persistence of new messages but also supports cleanup during message retrieval, which occurs when a device reconnects to process undelivered messages. This approach keeps the sorted set clean by removing references to expired messages.
-- Define the sorted set key
local messagesKey = KEYS[1]
-- Define the maximum allowed number of messages
local maxMessagesSize = tonumber(ARGV[1])
-- Get all elements from the sorted set
local elements = redis.call('ZRANGE', messagesKey, 0, -1)
-- Initialize a table to store retrieved messages
local messages = {}
-- Iterate over each element in the sorted set
for _, key in ipairs(elements) do
-- Check if the message key still exists in Redis
if redis.call('EXISTS', key) == 1 then
-- Retrieve the message value from Redis
local msgJson = redis.call('GET', key)
-- Store the retrieved message in the result table
table.insert(messages, msgJson)
else
-- Remove the reference from the sorted set if the key does not exist
redis.call('ZREM', messagesKey, key)
end
end
-- Return the retrieved messages
return messagesBy leveraging Redis’ sorted sets and strings, along with Lua scripting for atomic operations, our new design achieves efficient message persistence and retrieval, as well as dynamic cleanup. This design addresses the scalability limitations of the PostgreSQL-based solution.
Migration from Jedis to Lettuce
To validate the scalability of the new Redis-based architecture for persistent message storage, we selected a point-to-point (P2P) MQTT communication pattern as a performance testing scenario. Unlike fan-in (many-to-one) or fan-out (one-to-many) scenarios, the P2P pattern typically involves one-to-one communication and creates a new persistent session for each communicating pair. This makes it well-suited for evaluating how the system scales as the number of sessions grows.
Before starting large-scale tests, we conducted a prototype test that revealed the limit of 30k msg/s throughput when using PostgreSQL for persistence message storage. At the moment of migration to Redis, we used the Jedis library for Redis interactions, primarily for cache management. As a result, we initially decided to extend Jedis to handle message persistence for persistent MQTT clients. However, the initial results of the Redis implementation with Jedis were unexpected. While we anticipated Redis would significantly outperform PostgreSQL, the performance improvement was modest, reaching only 40k msg/s throughput compared to the 30k msg/s limit with PostgreSQL.

This led us to investigate the bottlenecks, where we discovered that Jedis was a limiting factor. While reliable, Jedis operates synchronously, processing each Redis command sequentially. This forces the system to wait for one operation to complete before executing the next. In high-throughput environments, this approach significantly limited Redis’s potential, preventing the full utilization of system resources.
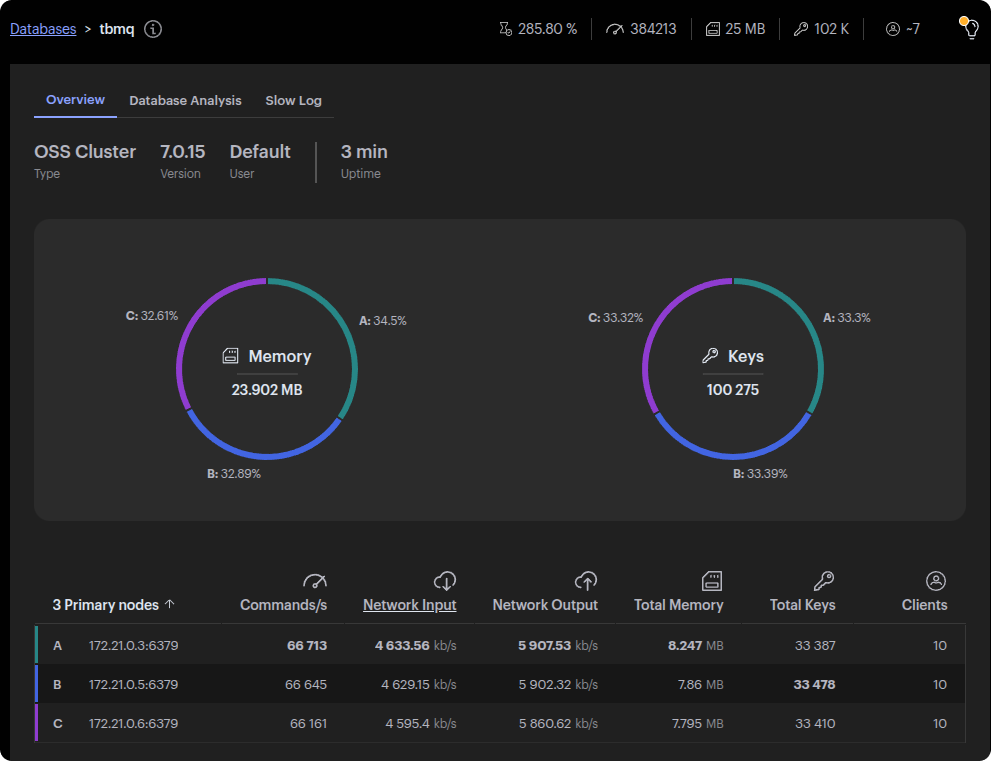
RedisInsight shows ~66k commands/s per node, aligning with TBMQ’s 40k msg/s, as Lua scripts trigger multiple Redis operations per message.
To overcome this limitation, we migrated to Lettuce, an asynchronous Redis client built on top of Netty. With Lettuce, our throughput increased to 60k msg/s, demonstrating the benefits of non-blocking operations and improved parallelism.
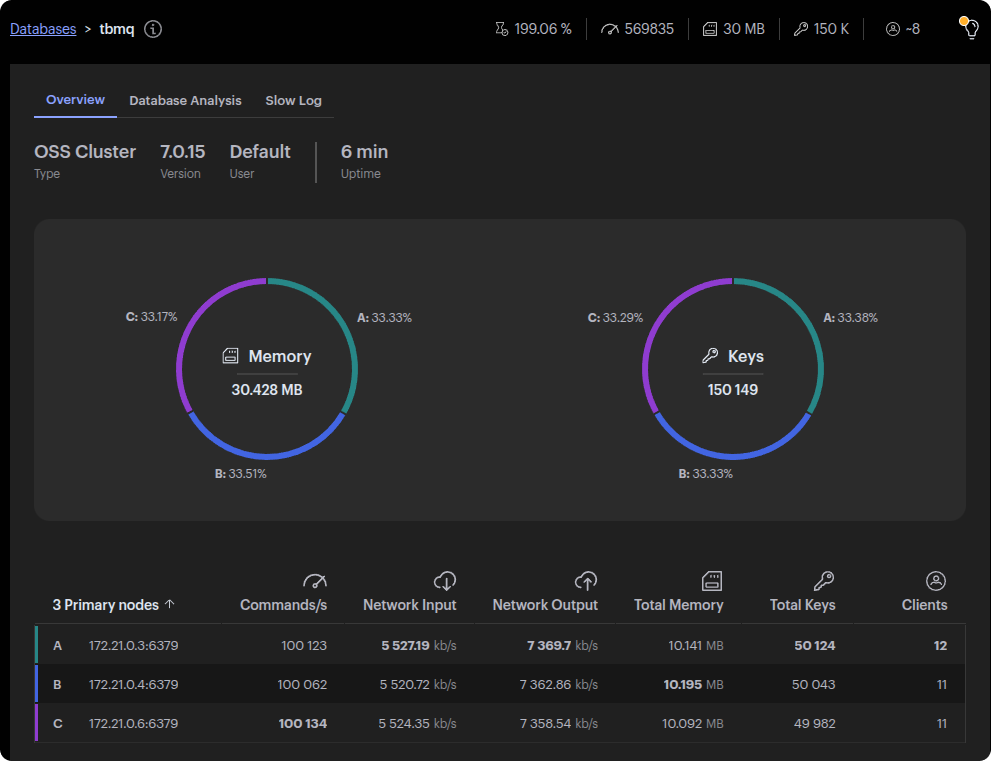
At 60k msg/s, RedisInsight shows ~100k commands/s per node, aligning with the expected increase from 40k msg/s, which produced ~66k commands/s per node.
Lettuce allows multiple commands to be sent and processed in parallel, fully exploiting Redis’s capacity for concurrent workloads. Ultimately, the migration unlocked the performance gains we expected from Redis, paving the way for successful P2P testing at scale. For a deep dive into the testing architecture, methodology, and results, check out our detailed performance testing article.
Conclusion
In distributed systems, scalability bottlenecks often emerge when vertically scaled components, like traditional databases, are used to manage high-volume, session-based workloads. Our experience with persistent MQTT sessions for DEVICE clients demonstrated the importance of designing around horizontally scalable solutions from the start.
By offloading session storage to Redis and implementing key architectural improvements during the migration, TBMQ 2.x built a persistence layer capable of supporting a high number of concurrent sessions with exceptional performance and guaranteed message delivery.
We hope our experience provides practical guidance for engineers designing scalable, session-aware systems in distributed environments.
Opinions expressed by DZone contributors are their own.
Comments