The Battle of the Crawlers: Apache Nutch vs. StormCrawler
This post has everything you need to know about the efficiency of Apache Nutch and StormCrawler. Read on to find out more on the benchmark analysis and conclusion drawn from the study.
Join the DZone community and get the full member experience.
Join For FreeHappy New Year everyone!
For this first blog post of 2017, we'll compare the performance of StormCrawler and Apache Nutch. As you probably know, these are open source solutions for distributed web-crawling and we provided an overview last year of both as well as a performance comparison when crawling a single website.
StormCrawler has been steadily gaining in popularity over the last 18 months and a frequent question asked by prospective users is how fast it is compared to Nutch. Last year's blog post provided some insights into this but now we'll go one step further by crawling not a single website, but a thousand. The benchmark will still be on a single server though but will cover multi-million pages.
Disclaimer: I am a committer on Apache Nutch and the author of StormCrawler.
Meet the Contestants
Please have a look at our previous blog post for a more detailed description of both projects. This Q and A should also be useful.
Apache Nutch is a well-established web crawler based on Apache Hadoop. As such, it operates by batches with the various aspects of web crawling done as separate steps (e.g. generate a list of URLs to fetch, parse the web pages, and update its data structures.)
In this benchmark, we'll use the 1.x version of Nutch. There is a 2.x branch but as we saw in a previous benchmark, it is a lot slower. It also lacks some of the functionalities of 1.x and is not actively maintained.
StormCrawler, on the other hand, is based on Apache Storm, a distributed stream processing platform. All the web crawling operations are done continuously and at the same time.
What we can assume (and observed previously) is that StormCrawler should be more efficient as Nutch does not fetch web pages continuously, but only as one of the various batch steps. On top of that, some of its operations — mainly the ones that deal with the crawldb, the datastructure used by Nutch — take increasingly longer as the size of the crawl grows.
The Battleground
We ran the benchmark on a dedicated server provided by OVH with the following specs:
Intel Xeon E5 E5 1630v3 4c/8t 3.7 / 3.8 GHz
64 GB of RAM DDR4 ECC 2133 MHz
2x480GB RAID 0 SSD
Ubuntu 16.10 server
We installed the following software:
Apache Storm 1.0.2
Elasticsearch 2.4
Kibana 4.6.3
StormCrawler 1.3-SNAPSHOT
Hadoop 2.7.3
Apache Nutch 1.13-SNAPSHOT
Finally, the resources and configurations for the benchmark can be found on https://github.com/DigitalPebble/stormcrawlerfight.
Apache Nutch
The configuration for Nutch can be found in the GitHub repo under the nutch directory. This should allow you to reproduce the benchmarks if you wished to do so.
The main changes to the crawl script, apart from the addition of a contribution I recently made to Nutch, was to:
- Set the number of fetch threads to 500
- Change the max size of the fetchlist to 50,000,000
- Use 4 reducer tasks
- Remove the link inversion and dedupe steps
The latter was done in order to keep the crawl to a minimum. We left the setting for the limitation of fetch time to 3 hours. The aim of this was to avoid long tails in the fetching step, where the process is busy fetching from only a handful of slow servers.
In order to optimise the crawl, we limited the number of URLs per hostname in the fetchlist to 100, which guarantees a good distribution of URLs and again, prevents the long tail phenomenon, which is commonly observed with Nutch. We also tried to avoid the conundrum whereby setting too low a duration for the fetching step requires more crawl iterations, meaning that more generate and update steps are necessary.
Note: we initially intended to index the documents into Elasticsearch, however, this step proved unreliable and caused errors with Hadoop. We ended up deactivating the indexing step from the script, which should benefit Nutch when comparing to StormCrawler.
We ran 10 crawl iterations between 2016.12.16 11:18:37 CET and 2016.12.17 19:29:30 CET, the breakdown of times per step is as follows :
| Iteration # | Steps | Time |
| 1 | Generation | 0:00:38 |
| Fetcher | 0:00:45 | |
| Parse | 0:00:26 | |
| Update | 0:00:24 | |
| 2 | Generation | 0:00:40 |
| Fetcher | 0:23:26 | |
| Parse | 0:01:53 | |
| Update | 0:00:30 | |
| 3 | Generation | 0:00:52 |
| Fetcher | 0:55:46 | |
| Parse | 0:08:24 | |
| Update | 0:01:07 | |
| 4 | Generation | 0:01:15 |
| Fetcher | 1:08:36 | |
| Parse | 0:19:00 | |
| Update | 0:02:01 | |
| 5 | Generation | 0:02:03 |
| Fetcher | 2:14:20 | |
| Parse | 0:47:59 | |
| Update | 0:04:34 | |
| 6 | Generation | 0:03:55 |
| Fetcher | 4:20:02 | |
| Parse | 1:30:58 | |
| Update | 0:08:46 | |
| 7 | Generation | 0:06:44 |
| Fetcher | 3:52:36 | |
| Parse | 1:09:40 | |
| Update | 0:08:15 | |
| 8 | Generation | 0:08:31 |
| Fetcher | 3:48:35 | |
| Parse | 1:04:27 | |
| Update | 0:08:32 | |
| 9 | Generation | 0:10:00 |
| Fetcher | 3:51:57 | |
| Parse | 1:18:38 | |
| Update | 0:09:27 | |
| 10 | Generation | 0:11:44 |
| Fetcher | 3:32:35 | |
| Parse | 0:59:13 | |
| Update | 0:09:39 | |
| 33:08:53 |
What you can observe is that the generate and update steps do take an increasingly longer time, as mentioned above.
The stats from the final update step were :
| db_fetched | 10,626,298 |
| db_gone | 686,834 |
| db_redir_perm | 123,087 |
| db_redir_temp | 217,191 |
| db_unfetched | 64,678,627 |
Which gives us a total of 11,653,410 URLs processed (fetch + gone + redirs) in a total time of 1930 minutes.
On average, Nutch fetched 6,038 URLs per minute.
The graph below shows the bandwidth usage of the server when the Nutch crawl was running.
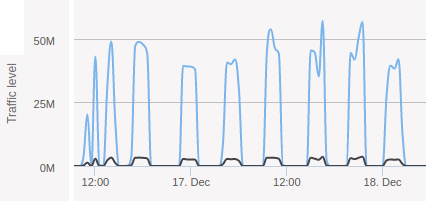 Network graph of Nutch crawl
Network graph of Nutch crawl
This is a good illustration of the batch nature of Nutch, where the fetching is only one part of the whole process.
Let's now see how StormCrawler fared in a similar situation.
StormCrawler
StormCrawler can use different backends for storing the status of the URLs (i.e. which is what the crawldb does in Nutch). For this benchmark, we used the Elasticsearch module of StormCrawler as it is the most commonly used. This means that we won't just be storing the content of the webpages to Elasticsearch, we'll also be using it to store the status of the URLs as well as displaying metrics about the crawl with Kibana.
We ran the crawl for over 2 and a half days and got the following values in the status index:
| DISCOVERED | 188,396,525 |
| FETCHED | 32,656,149 |
| ERROR | 2,901,502 |
| REDIRECTION | 2,050,757 |
| FETCH_ERROR | 1,335,437 |
Which means a total of 38,943,845 webpages processed over 3977 minutes, i.e. an average of 9792.26 pages per minute.
The network graph looked like this:
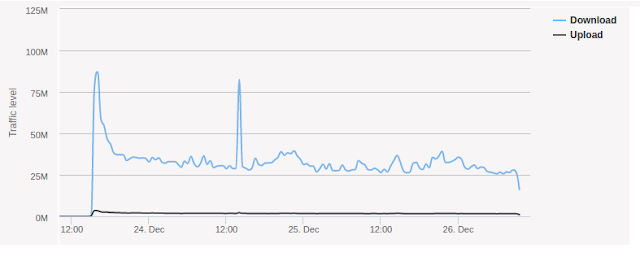 Network graph of StormCrawler crawl
Network graph of StormCrawler crawl
Which, apart from an unexplained and possibly unrelated spike on Christmas day, shows a pretty solid use of the bandwidth. Whereas Nutch was often around the 50M mark, StormCrawler is lower but constant.
The metrics stored in Elasticsearch and displayed with Kibana gave a similar impression:
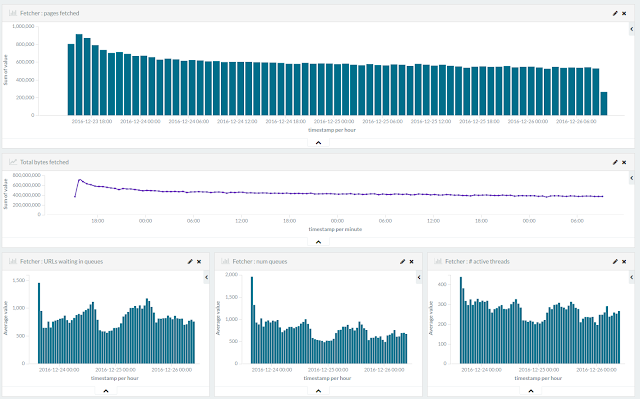 StormCrawler metrics displayed with Kibana
StormCrawler metrics displayed with Kibana
Interestingly, the Storm UI indicated that the bottleneck of the pipeline was the update step, which is not unusual given the 'write-heavy' nature of StormCrawler.
Conclusion
This benchmark as set out above shows that StormCrawler is 60% more efficient than Apache Nutch. We also found StormCrawler to run more reliably than Nutch but this could be due to a misconfiguration of Apache Hadoop on the test server. We had to omit the indexing step from the Nutch crawl script because of reliability issues, whereas the StormCrawler topology did index the documents successfully. This would have added to the processing time of Nutch.
The main explanation lies in the design of the crawlers: Nutch achieves greater spikes in the fetching step but does not fetching continuously as StormCrawler does. I had compared Nutch to a sumo and StormCrawler to a ninja previously but it seems that the tortoise and hare parable would be just as appropriate.
It is important to bear in mind that the raw performance of the crawlers is just one aspect of an overall comparison. One should also consider the frequency of releases and contributions as well as more subjective aspects such as the ease of use and versatility. There is also of course the question of the functionalities provided. To be fair to Nutch, it currently does thing that StormCrawler does not yet support such as document deduplication and scoring. On the other hand, StormCrawler too has a few aces up its sleeve with Xpath extraction, sitemap processing and live monitoring with Kibana.
As often said in similar situations: “your mileage might vary”. The figures given here depend on the particular seed list and hardware, you might get different results on your specific use case. The resources and configurations of the benchmark being publicly available, you can reproduce it and extend it as you wish.
Hopefully we’ll run more benchmarks in the future. These could cover larger scale crawling in fully distributed mode and/or comparing different backends for StormCrawler (e.g. Redis+RabbitMQ vs. Elasticsearch).
Happy crawling!
Published at DZone with permission of Julien Nioche. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments