The Flavors of APIs
Check out the different flavors of APIs.
Join the DZone community and get the full member experience.
Join For Free
In today’s tech landscape, APIs are a hot topic. The rise of microservice-based architectures as opposed to legacy monoliths has further driven the necessity of robust APIs. With microservices, powerful applications are broken up – i.e. distributed as discrete components across numerous logical and physical machines. This is possible in part due to the availability of cloud computing – virtualized access to almost limitless compute and storage resources made available in a pay-as-you-go model, provided by large technology companies operating massive data centers around the globe.
These microservices-based architectures are a contrast to the large-scale, tightly coupled applications of the past that were better designed to run on the limited infrastructure available at the time. When applications required more resources, they would need to scale vertically (i.e. adding more memory, CPU, or storage to the machine). The ubiquity of computing resources in the cloud allows modern applications to instead scale horizontally, by distributing the load over many less powerful machines. Further, applications can be designed intelligently – with components running on infrastructure that better meets the unique load. This ultimately leads to bite-sized chunks of the larger application having infrastructure which is uncoupled from the rest.
With this style of computing, however, comes the requirement for a lightweight communication mechanism which allows for two things:
- Consumers (either humans or other systems) to interact with a specific part — and only that specific part — of the broader application.
- The various distributed components to interact with each other.
Enter: the modern API. Built on the HTTP protocol, and capable of sharing data of the network in a lightweight fashion, the API is the piping of the web that connects users and technologies.

And similarly to how changes in both technology and human behavior-led organizations to switch from monolithic development practices to microservices – consumers of digital applications have changed in recent years as well. With new ways of building and deploying applications come new ways of integrating them with other areas of your landscape.
While it is true that many of the traditional software patterns still exist as they did years ago, despite changes in technology —new requirements have emerged and old requirements are now amplified given the prominence of digital applications in our day-to-day lives.
That said, let’s take a look at various flavors of APIs, how they work, and the scenarios in which each is useful.
The RESTful or REST-like API
The REST API is the vanilla soft-serve of API flavors. It’s very common. Most software developers are familiar with the workings of these APIs, and most software companies offer a suite of them available to their customers and development community.
“RESTful” (or “REST-like”) APIs are those which conform to all or most of the principles and constraints of REST, as defined by Roy Fielding in his 2000 dissertation titled “Architectural Styles and the Design of Network-based Software Architectures”. Let’s take a look at a few of these constraints:
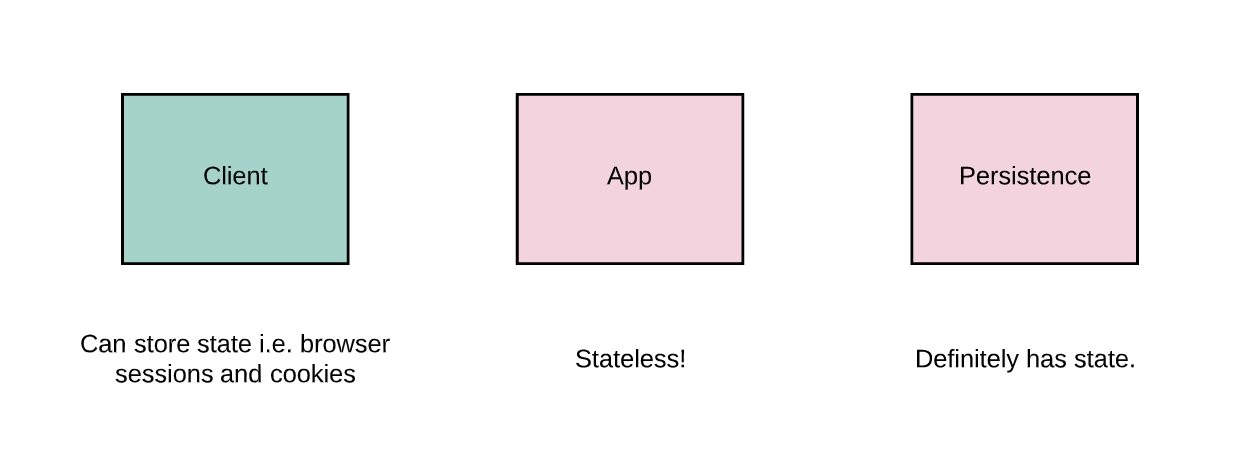
- Client-Server Separation: The client-side and server-side of a system are independent components that communicate over the network. Each time the client-side needs data, it makes another request to the server-side.

- Stateless: the API is a way to transfer a point-in-time representation of a system’s state. The server itself won’t remember things about the client between requests, and each request should have all of the information required in order to fulfill it. It is not the job of the application to store or remember things, and that is deferred to the client, or to a persistent store like a database.
Here is an example. I’m accessing a website that requires authentication in order to view some of the content. As I am browsing through the content, my browser (the client) is making requests to the server to serve up the data. In a RESTful scenario, each and every one of these requests contains my authentication token, so that the server understands that I have access to view the content. After each request, it doesn’t remember this or assume anything.
Client-Server Communication Methods
So, we’ve covered off the separation between client and server. But how are these requests and responses actually communicated? This is where the concepts of HTTP come into play.
The HTTP methods are based off of verbs, which are accessing resources. The same way I would go to the store to get some groceries — a client goes to a location (URL) to get (method) a resource (URI). Everything on the web is a resource, and each resource has a uniform resource identifier. We use unified resource locators to find those resources. Finally, we use the methods to indicate what we want to do with those resources. In the example below, we’re using the HTTP GET method — to get the resource.

However, you can use a number of different methods to do a number of different things. HTTP methods support the standard CRUD operations and more. Some other examples are shown below, where we include additional data along with the request in order to perform specific actions.


Parameterization
Parameters are a fun way to do specific things with your REST API. In the example directly above, we used “id” as a path parameter within the URL path, in order to let the server know that the operation we’re doing applies specifically to that resource.
Additionally, in both examples, we passed some text-based JSON data to the URL using an HTTP payload request body. The body allows us to structure data for the receiving server in standard format.
This is just a quick glimpse at features of RESTful APIs. We intentionally did not cover off some of the advanced topics like security, management, versioning, or even design/development. We will leave those for another time.
Functions and Remote Procedure Calls
Let’s take a step back to the “microservices model” we discussed in the opening bit. Recall that we emphasized that consumers of microservices can either be humans (via the web or mobile client), or other microservices and systems acting as a client.
We now understand that REST APIs are an excellent mechanism for communicating with clients in a north-south scenario — particularly due to its browser-friendly implementation and human-readable format. But what about the east-west scenario for communication directly between microservices in a distributed system? This is where gRPC shines.
gRPC builds on the traditional remote function or procedure calls utilized in systems of the past. Essentially, an RPC or RFC is a type of API that allows a function or procedure to be called as if it were local — despite that function or procedure living on a remote server. It leverages a form of a client-server model and incorporates the concept of a stub. gRPC takes this concept and optimizes it for modern cloud infrastructure. If RPC is traditional icecream, gRPC is a more compact form — the icecream bar.
The examples below walks through the request-response pattern of a traditional remote procedure call, and contrasts that will some of the features of gRPC.
- In an RPC model, the client is requested to perform an action. If this involves accessing a remotely located function/procedure, the client invokes the client-side stub — which leverages the runtime environment to communicate with the remote runtime.
- On the remote side, the call is received in the runtime environment, goes up through the stub, to the server where it is executed— and back through the same pathway to reach the client again with the response.
gRPC takes a similar approach, albeit leveraging advanced technologies like HTTP/2, protocol buffers, and more. In the diagram below, you’ll see that the concept of stubs has translated over to gRPC. Like RESTful APIs, gRPC is designed to work across multiple languages and platforms. A gRPC stub can be implemented as part of a client (written in Java, for example).

“gRPC is based around the idea of defining a service, specifying the methods that can be called remotely with their parameters and return types”
The end result is a special API that performs very well compared to RESTful services. Let’s check out some of the differentiators below.
Protocol Buffers
Protocol Buffers — or protobufs — are a way to serialize data. Protobuf was built to be a faster and more efficient way for both storing and transferring serialized data, in comparison to the standards used in RESTful APIs like XML and JSON. Protobufs are based on the concepts of services and messages, which are defined in a definition language like below. These messages are encoded in binary for transfer over a network with the help of HTTP/2.

HTTP/2 Support
The second version of the hypertext transfer protocol has made many advances in the standard HTTP/1.1 used in most RESTful APIs. HTTP/2 adds speed, simplicity, and robustness to the protocol. For example — as we mentioned above — v2 supports binary encoding versus text-based encoding. Many of the workarounds that developers had to build into applications, are now available in the transport layer.
Some other interesting components are the support for multiplexing and server pushing. In HTTP/1.1 — as used in REST APIs — only one resource on the server can be accessed per request. In HTTP/2, many different resources can be accessed over one request (multiplexing). Servers can now also initiate the connection (push) without needing to wait for a request.
Webhooks
Let’s start by saying that Webhooks aren’t technically APIs. They are the sorbet or frozen yogurt of the API world. They are very similar in appearance, but after a second look (or taste) you’ll realize they work a little differently. Let’s think back to our other flavors of APIs. In those scenarios, there is data that exists in a system somewhere. To access this data outside the boundaries of the application, we leverage the API. We make a request to the API to get `some data`, and if we are authorized to see this data, the server will return what was requested to us. For example, if we did a GET /frozen-treats/v1/flavors , we would be returned a list of all the flavors.
But what if we wanted to get this information as it became available? To achieve this using a RESTful API, at best we would need to build polling into our application. Polling is the practice of building requests to an API endpoint on a scheduled basis in order to check if anything has been changed. And what if we didn’t have to ask the API each time something changes? Cue Webhooks.

Webhooks are a way to pass data to another system based on events, as the events occur. They replace the request/response pattern with an event-based one, and they’re very useful in comparison to polling a traditional REST API to check for new events. And, they work using the same technologies as APIs. Webhooks use POST requests and JSON payloads to send event data.
For example — in the REST section we used parameters and HTTP PUT to change a flavor of ice cream. If this change needed to be reflected immediately in another system — let’s say a digital menu app— we could leverage a Webhook that fires off that update flavorevent to another endpoint.

The digital menu app could have logic to “handle” this event, and update where needed. Without the Webhook, this app would need to continuously pull that list of all flavors and build logic to check if anything has been changed.
Hopefully by now you have a fairly decent understanding of the different flavors of APIs, and how each one can be used in different technical scenarios to achieve different results. REST APIs are great for clients requesting resources from servers, gRPC is great for communication between microservices. And Webhooks are a great way for the real-time pushing of events from one system to another.
Stay tuned for part 2 of this story — where we’ll dive in APIs for mutation and querying of distributed data sources using GraphQL.
Further Reading
Published at DZone with permission of Ryan Searle. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments