Are There Any Differences Between Table Scan and Index Scan
Join the DZone community and get the full member experience.
Join For FreeIntroduction
As we all know, developers prefer Index Seek in the case of performance of a query, and we all know what Index Seek is and how it improves performance. In this article we are not going to discuss Index Seek.
A table scan is performed on a table which does not have an Index upon it (a heap) – it looks at the rows in the table and an Index Scan is performed on an indexed table – the index itself.
Here we are trying discuss a specified scenario related to Table Scan and Index Scan.
Scenario Description
Suppose we have a table object without any Index on it. The name of the Table Object is tbl_WithoutIndex and another Table Object called tbl_WuthIndex
-- Heap Table Defination IF OBJECT_ID(N'dbo.tbl_WithoutIndex', N'U') IS NOT NULL BEGIN DROP TABLE [dbo].[tbl_WithoutIndex]; END GO CREATE TABLE [dbo].[tbl_WithoutIndex] ( EMPID INT NOT NULL, EMPNAME VARCHAR(50) NOT NULL ); GO -- Insert Some Records INSERT INTO [dbo].[tbl_WithoutIndex] (EMPID, EMPNAME) VALUES (101, 'Joydeep Das'), (102, 'Sukamal Jana'), (103, 'Ranajit Shinah'); GO -- Table with Index (Clustered Index for primary Key) IF OBJECT_ID(N'dbo.tbl_WithIndex', N'U') IS NOT NULL BEGIN DROP TABLE [dbo].[tbl_WithIndex]; END GO CREATE TABLE [dbo].[tbl_WithIndex] ( EMPID INT NOT NULL PRIMARY KEY, EMPNAME VARCHAR(50) NOT NULL ); GO -- Finding Index Name sp_helpindex tbl_WithIndex;
index_name
|
index_description
|
index_keys
|
PK__tbl_With__14CCD97D3AD6B8E2
|
clustered, unique, primary key located on PRIMARY
|
EMPID
|
-- Insert Some Records INSERT INTO [dbo].[tbl_WithIndex] (EMPID, EMPNAME) VALUES (101, 'Joydeep Das'), (102, 'Sukamal Jana'), (103, 'Ranajit Shinah'); GO
Now we are going to compare the execution plan output
SELECT * FROM [dbo].[tbl_WithoutIndex];
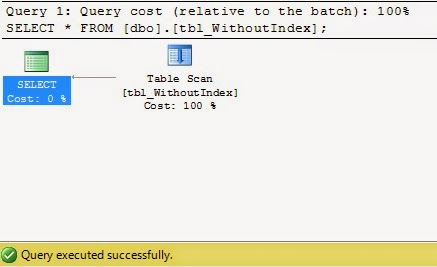
has no Index (Here I mean the clustered Index) the table is a Heap. So when we put the SELECT statement the entire table scanned.
SELECT * FROM [dbo].[tbl_WithIndex];

Here he Table has a PRIMARY KEY, so it has a Clustered Index on it. But here we are not putting the Index columns on the WHERE clause, so the Clustered Index Scan Occurs.
Close Observation of Execution Plan

Table Name
|
Estimated IO Cost
|
tbl_WithoutIndex
|
0.0032035
|
Tbl_WithIndex
|
0.003125
|
If we see the Estimated Operation Cost, it would be same for both the Query (0.0032853).
Question in Mind
Here we can see the Estimated Operation cost for both the Query is same. So Question is in the mind that, if a Index Scan occur we can drop the index and use the heap (in our case). So is there any other difference between them.
How they are Differences
Here we understand what the internal difference between Table Scan and Index Scan.
When the table scan occurs MS SQL server reads all the Rows and Columns into memory. When the Index Scan occurs, it's going to read all the Rows and only the Columns in the index.
Effects in Performance
In case of performance the Table Scan and Index Scan both have the same output, if we have use the single table SELECT statement. But it differs in the case of Index Scan when we are going to JOIN table.
Hope you like it.
Published at DZone with permission of Joydeep Das. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments