AI Is Not New, So Why Are We Seeing an Explosion in AI’s Capability?
In this post, we will look at various factors from the beginning that have contributed to the current explosion of AI capabilities.
Join the DZone community and get the full member experience.
Join For FreeDigging Into the ‘Why Now’ Question Behind the AI Explosion
Researchers, academics, and philosophers have been trying to endow machines with human-like capabilities since antiquity, but most historians would trace the beginning of AI as we know it today to the Dartmouth Summer Research Project on Artificial Intelligence (AI) over the summer of 1956 (“Dartmouth workshop,” 2020). In the 60+ years since that kickoff, researchers have tried many techniques to model intelligence, with two major schools of thought emerging – with “Classical AI” as distinct in theory and practice from “Modern AI”.
Classical AI
Classical AI relies on machines operating autonomously within a set of logical rules. Building AI meant representing the world in a set of data structures (such as trees or lists or sets) and then using rules (such as and, or, if-then-else, and so on) to reason within that knowledge space. For example, one can create rules-based translation software by representing language as a set of words, and then perform machine translation by translating those words from one language to another, and then reordering the words within defined rules regarding the order of nouns and verbs, and adjectives.
Likewise, an individual can try to solve computer vision recognition problems by first establishing the rules of what makes certain objects, themselves. For example, one can start an animal classification program by first describing cats as “four-legged animals with whiskers” and then decompose that definition into a set of subproblems ( e.g., – find legs, find whiskers) and continue breaking these problems into more detailed problems (e.g., – ‘find edges’, separate foreground and background).
Although the classical school enjoyed certain successes (in 1967 Marvin Minsky famously said that “within a generation…the problem of creating artificial intelligence will substantially be solved.” (“History of artificial intelligence,” 2020)), eventually the efforts ran into a wall. Although rules-based systems offer an easily-understood mechanism to build autonomy, researchers soon discovered that the world is too complex and messy to be fully captured into a closed representation system. This meant that many early AI experiments succeeded in carefully-controlled environments but failed to generalize to real-world situations. This led to a number of “AI Winters” when funding and research on autonomous systems came to a halt.
Modern AI
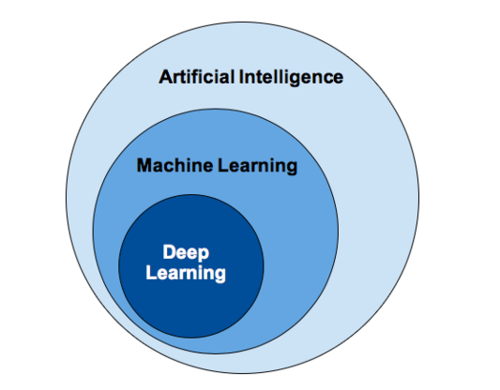
In contrast to Classical AI, Modern AI relies on letting the computer derive its own rules and logic about the world, by feeding it labeled (and sometimes unlabeled) data. Using this method, instead of attempting to describe to the computer what features a cat has, an AI developer will instead feed it thousands of pictures of cats. With a large-n amount of cats, the machine is (often but not always) able to extract the relevant features autonomously, without a human’s explicit programming. Another name for Modern AI is Machine Learning or “ML”, which is also the term we will be using throughout this report.
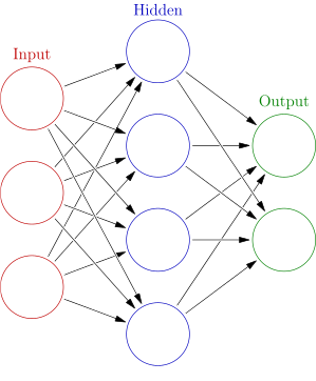
As a separate field, ML started to flourish in the 1990s. The field changed its goal from achieving artificial intelligence to tackling solvable problems of a practical nature. It shifted focus away from the symbolic approaches it had inherited from AI, and toward methods and models borrowed from statistics and probability theory. But the real inflection point for ML came in 2012 with the ImageNet competition, when an Artificial Neural Network or “ANN”-based submission called AlexNet outclassed all other competitors by 10.8 %. It was a historic moment because up to that point, ANNs (computing systems vaguely inspired by the biological neural networks that constitute animal brains) were considered nothing more than a research tool. Their success in this competition changed that perception.
So what exactly was the cause of ML development and applicational use between the 1990s and 2012? Contrary to popular belief, ANNs themselves were not invented in that period. In fact, they were first described by Warren McCulloch and Walter Pitts in 1943 (Palm, 1986) and research on them continued throughout the second half of the century. Instead, two major developments occurred which allowed ML development to succeed:
An Increase of Labeled Data
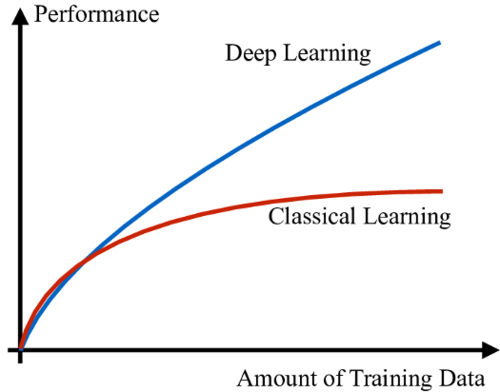
By design, ML systems learn from data. Therefore, having access to abundant data to feed the algorithm is paramount in achieving meaningful results. Moreover, for most ML applications the data must be labeled (e.g., a picture of a cat has to have the appropriate “cat” label associated). In the years leading up to 2012, large amounts of labeled data were generated, powered in large part due to the growth of digital technology and the internet.
Access to More Powerful and Cheaper Computing Capabilities
Beyond data, ML algorithms need many compute cycles to “look” at thousands (and often millions) of examples before they can learn the right features. Leading up to 2012, computing power became more abundant, cheaper, while at the same time more effective implementations of algorithms arrived for GPUs (which are better suited for ML, compared to CPUs).
Put together, data, compute and ANNs started a new era in ML known as Deep Learning or “DL”.
Published at DZone with permission of Neil Serebryany. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments