Multi-Scale Feature Learning in CNN and U-Net Architectures
Multi-scale feature learning helps CNNs and U-Net models combine global context with fine details, improving accuracy in tasks like image segmentation.
Join the DZone community and get the full member experience.
Join For FreeScale variation is a persistent source of error in vision models. A semantic concept can occupy a handful of pixels or most of the frame, and dense prediction tasks such as semantic segmentation intensify the difficulty because each output location must be both correctly classified and precisely localized.
Multi-scale feature learning addresses this by designing explicit pathways that exchange information across resolutions, allowing high-frequency spatial detail and low-frequency semantic context to be fused into representations that remain informative across size regimes.
Scale as a Representational Constraint
A standard CNN creates a pyramid through downsampling. Strided operators reduce spatial resolution while increasing nominal receptive field, producing deeper feature maps that are spatially coarse but often richer in semantic abstraction than early feature maps. Feature Pyramid Networks make this hierarchy directly usable by constructing a top-down pathway with lateral connections, injecting high-level semantics into higher-resolution maps while leveraging the backbone pyramid rather than constructing explicit image pyramids.
Nominal receptive field does not fully describe how much context is used in practice. Effective receptive field analysis shows that influence concentrates near the center of the theoretical field and occupies only a fraction of it, which helps explain why depth alone may not yield robust large-context reasoning. Dense prediction, therefore, benefits from combining context expansion that preserves resolution, such as dilated convolutions, with complementary mechanisms that restore spatial detail for sharp boundaries, creating an architecture-level contract between “seeing enough” and “placing precisely.”
Multi-Scale Patterns Inside CNN Backbones
Multi-scale computation can be embedded into the backbone by running parallel receptive-field operators over a shared tensor. The Inception family popularized a parallel-branch design in which different convolutional operations process the same activation map, and their results are concatenated, improving computational utilization while mixing local and less-local cues inside each stage. Embedding scale mixture this early reduces the extent to which downstream heads must infer scale from a single resolution stream.
Dilated convolutions provide a complementary backbone-level lever when spatial density must be preserved. Dilation expands the field-of-view without additional pooling, enabling systematic aggregation of multi-scale contextual information while maintaining a dense feature grid for later fusion. A different backbone philosophy keeps multiple resolutions in parallel throughout the network and fuses them repeatedly; high-resolution networks maintain a high-resolution stream while exchanging information with lower-resolution streams to build multi-scale representations through continual exchange rather than late-stage upsampling.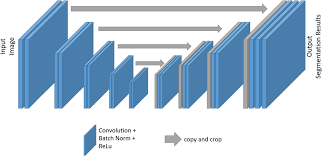
Context Pyramids and Pyramid Networks
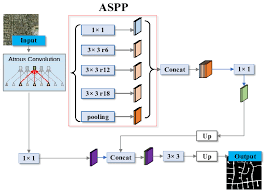
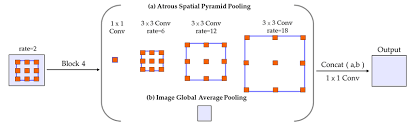
Pyramid modules make scale an explicit design axis instead of an emergent side effect. Pyramid pooling aggregates context by pooling over multiple region sizes and reinjecting those pooled features, providing global and semi-global priors that stabilize pixel-level prediction; PSPNet formalized this direction through a pyramid pooling module designed for different-region context aggregation. Atrous Spatial Pyramid Pooling follows a closely related multi-branch idea but replaces pooling bins with parallel atrous convolutions at different rates, yielding multiple effective fields-of-view from a single feature tensor.
An ASPP-style forward path is typically implemented as parallel branches plus a global pooling branch, followed by concatenation and a projection that caps channel growth. The snippet below focuses on two production-relevant concerns: aligning spatial lattices across branches and bounding the channel budget after concatenation; conv3x3_r6 and its siblings represent branches configured with different atrous rates, while image_pool represents an image-level feature branch that is resized back to the feature grid before concatenation.
def forward(self, x):
h, w = x.shape[-2:]
b0 = self.conv1x1(x)
b1 = self.conv3x3_r6(x)
b2 = self.conv3x3_r12(x)
b3 = self.conv3x3_r18(x)
b4 = F.interpolate(self.image_pool(x), size=(h, w), mode="bilinear", align_corners=False)
return self.project(torch.cat((b0, b1, b2, b3, b4), dim=1))
The explicit interpolation step pins the global branch to the same lattice as the atrous branches, even when encoder output stride changes, and the final projection prevents branch concatenation from ballooning memory as rates and branches evolve. DeepLabv3+ pairs such a multi-rate context encoder with a decoder module that refines boundaries after context has been aggregated, reflecting a common split between context gathering and spatial refinement.
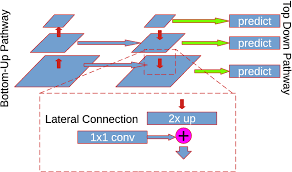
The Feature Pyramid Networks approach scales coupling from the opposite direction by constructing a top-down semantic pyramid from the backbone hierarchy. Rather than probing one tensor at multiple scales, FPN upsamples semantically strong deep features and fuses them with the same-resolution backbone features through lateral connections, yielding multi-resolution outputs for downstream heads.
The forward path below illustrates minimal fusion logic, with lateral projections (lat*) and output transforms (out*) assumed to exist, and nearest-neighbor interpolation used to match spatial lattices before addition.
def forward(self, c2, c3, c4, c5):
p5 = self.lat5(c5)
p4 = self.lat4(c4) + F.interpolate(p5, size=c4.shape[-2:], mode="nearest")
p3 = self.lat3(c3) + F.interpolate(p4, size=c3.shape[-2:], mode="nearest")
p2 = self.lat2(c2) + F.interpolate(p3, size=c2.shape[-2:], mode="nearest")
return self.out2(p2), self.out3(p3), self.out4(p4), self.out5(p5)
In addition, rather than concatenation, it enforces a shared channel space, keeping parameter growth controlled, while the explicit outputs make scale assignment a downstream decision rather than a hidden internal side effect of the backbone.
U-Net Scale Coupling and Skip-Path Designs
U-Net expresses multi-scale learning as a symmetric encoder–decoder contract: a contracting path captures context, an expanding path restores resolution, and skip connections deliver higher-resolution encoder features into decoder stages for precise localization. The architecture can be read as repeated cross-scale fusion steps in which a coarser decoder state is merged with a higher-resolution encoder representation, making skip fusion a primary mechanism for reconciling detail and context.
Skip fusion introduces a semantic gap because early encoder features carry local detail but may be poorly matched to the abstraction level of decoder features. UNet++ addresses this gap by redesigning skip pathways into nested, dense connections and applying deep supervision so that intermediate features are progressively transformed toward decoder-like semantics before fusion. UNet 3+ generalizes the same motivation through full-scale skip aggregation and deep supervision, explicitly aiming to incorporate low-level details and high-level semantics from multiple scales.
Attention gating offers a complementary way to control multi-scale information flow without proliferating skip paths. Attention U-Net introduces attention gates that learn to suppress irrelevant regions and highlight salient structures, using a gating signal derived from a coarser scale. In implementation terms, a compact gate can project both tensors into a shared space, compute a compatibility response, and apply a sigmoid mask to the original skip tensor before fusion.
def fuse_skip(self, skip, gate):
s = self.skip_conv(skip)
g = self.gate_conv(gate)
a = torch.sigmoid(self.attn_conv(F.relu(s + g)))
return skip * a
The mask multiplication preserves high-resolution detail while filtering it through a low-resolution semantic signal, turning the skip pathway into a conditional cross-scale channel rather than a raw feature copy.
Implementation Trade-Offs That Shape Real-World Results
Fusion cost and numerical behavior often dominate multi-scale design decisions. Concatenation-based fusion is highly expressive but inflates channels and memory, while addition-based fusion constrains representations to a shared channel space and keeps costs predictable. FPN explicitly frames its design as constructing feature pyramids at marginal extra cost, and atrous pyramid modules are commonly paired with projection layers to cap channel growth after concatenation. These constraints help explain why many production architectures favor a small number of carefully engineered fusion points over indiscriminately widening every multi-scale junction, even when additional capacity could improve accuracy on paper.
Optimization choices also have a multi-scale interpretation. Deep supervision, emphasized in UNet++ and UNet 3+, applies learning signals at intermediate resolutions so that representations throughout the decoder hierarchy are shaped directly, reducing reliance on the final stage to correct all mismatches introduced by aggressive downsampling. DeepLabv3+ reflects a related principle from another lineage by pairing a multi-scale context encoder with an explicit decoder for boundary refinement, separating context aggregation from spatial reconstruction.
Multi-scale feature learning in CNN and U-Net families reduces to deliberate control over where context is gathered, where detail is preserved, and how scales are reconciled. Parallel receptive-field operators, multi-rate context pyramids, top-down semantic pyramids, and skip-coupled decoders each implement that reconciliation with different assumptions about computational budget and about where semantic abstraction should live. Across the major design lines, the recurring theme is that scale becomes easier to manage when it is explicit in the computation graph, which is why feature pyramids, atrous pyramids, and skip-aligned encoder–decoders remain the dominating building blocks for scale-robust vision systems.
Opinions expressed by DZone contributors are their own.
Comments