Top 10 Reasons Why 87% of Machine Learning Projects Fail
In this article, find out why 87% of machine learning projects fail.
Join the DZone community and get the full member experience.
Join For FreeWe see news about machine learning everywhere. Indeed, there is a lot of potential in machine learning. According to Gartner’s predictions, “Through 2020, 80% of AI projects will remain alchemy, run by wizards whose talents will not scale in the organization” and Transform 2019 of VentureBeat predicted that 87% of AI projects will never make it into production.
Why is it like that? Why do so many projects fail?
Not Enough Expertise
One of the reasons is that the technology is still new to a large audience. In addition, most of the organizations are still unfamiliar with the software tools and the required hardware.
It seems that today, anyone who has worked in data analytics or software development who has done some sample data science projects are labeling themselves as data scientists after taking a short course online.
The fact is that experienced data scientists are needed to handle most of the machine learning and AI projects, especially when it comes to defining the success criteria, final deployment, and continuous monitoring of the model.
A Disconnect Between Data Science and Traditional Software Development
A disconnect between Data Science and traditional Software development is another major factor. Traditional software development tends to be more predictable and measurable.
However, Data science is still part-research and part-engineering.
Data science research moves ahead with multiple iterations and experimentation. Sometimes, the whole project will have to loop back from the deployment phase to the planning phase since the metric that was picked is not driving user behavior.
Traditional Agile based project deliveries may not be expected from a Data science project. This will cause large scale confusion for the leader who has been working with clear deliveries at the end of each task cycles for normal software development projects.
Volume and Quality of Data
Everyone knows that the larger the dataset, the better the prediction from the AI system. Apart from the direct implications of the higher volumes, as the size of the data increases, a lot of new challenges arise.
In many such cases, you will have to merge data from multiple sources. Once you start doing it, you will realize that they are not in sync many times. This will result in a lot of confusion. Sometimes you will end up merging data that were not supposed to merge, which will result in having data points with the same name but different meanings.
Bad data at best will produce results that aren’t actionable or insightful. Bad data can also lead to misleading results.
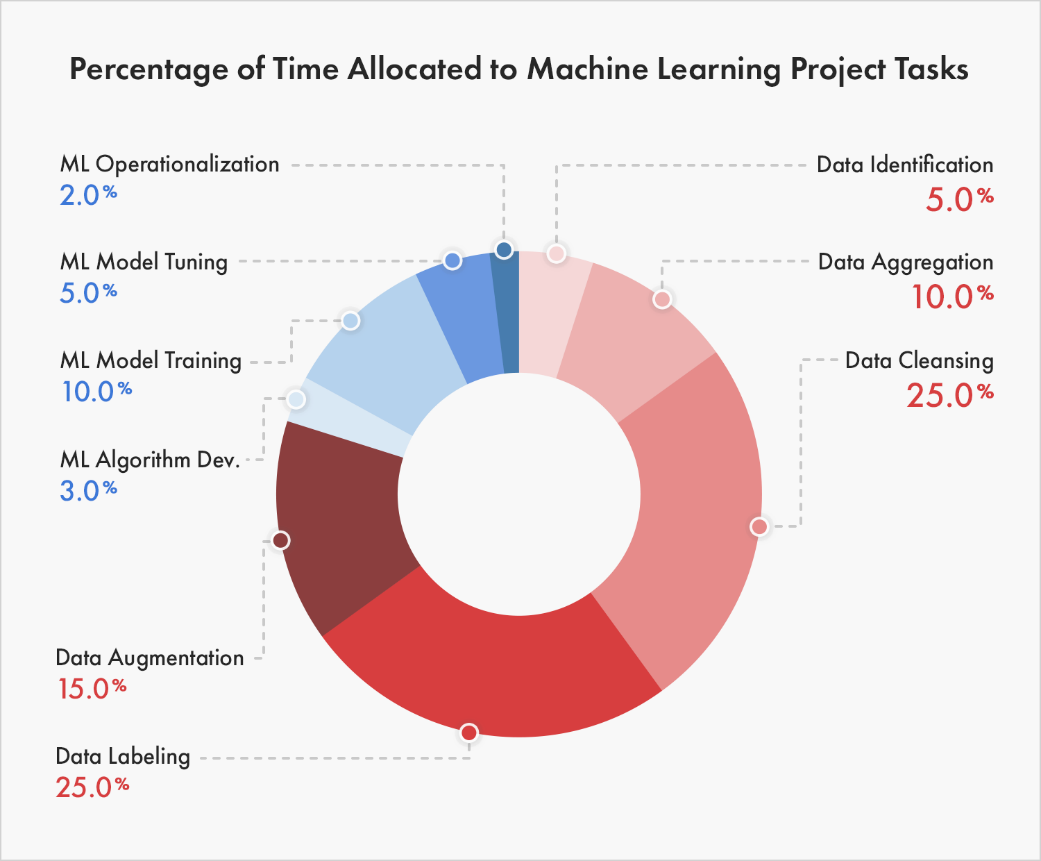
Labeling of Data
The unavailability of labeled data is another challenge that stalls many of the machine learning projects. According to the MIT Sloan Management Review,
76% of the people combat this challenge by attempting to label and annotate training data on their own and 63% go so far as to try to build their own labeling and annotation automation technology.
This means that a huge percentage of expertise of those data scientists are lost for the labeling process. This is a major challenge for the effective execution of an AI project.
This is the reason many of the companies are outsourcing the labeling task to other companies. However, it is a challenge to outsource the labeling task if it requires enough domain knowledge. Companies will have to invest in formal and standardized training of annotators if they need to maintain quality and consistency across datasets.
Another option is to develop their own data labeling tool if the data to be labeled complex. However, this often requires more engineering overhead than the Machine learning task itself.
Organizations A1re Siloed
Data is the most important entity of a machine learning project. In most organizations, these data would reside in different places with different security constraints and in different formats — structured, unstructured, video files, audio files, text, and images.
Having these data in different places in the different format itself is a challenge to handle. However, the challenge doubles when the organization is siloed, and responsible individuals are not collaborating with each other.
Lack of Collaboration
Lack of collaboration between different teams such as Data Scientists, Data engineers, data stewards, BI specialists, DevOps, and engineering, is another major challenge. This is especially important for the teams in the engineering scheme of things to Data science since there are a lot many differences in the way they work and the technology they use to fulfill the project.
It is the engineering team who is going to implement the machine learning model and take it to the production. So, there needs to be a proper understanding and strong collaboration between them.
Technically Infeasible Projects
Since the cost of Machine learning projects tends to be extremely expensive, most of the enterprises tend to target a hyper-ambitious “moon-shot” project that will completely transform the company or the product and give oversized return or investment.
Such projects will take forever to complete and will push the data science team to their limits.
Ultimately, the business leaders will lose confidence in the project and stop the investment.
It is always best to focus on a single, achievable project with the proper scope and target a discrete business challenge.
Alignment Problem Between Technical and Business Teams
Many times, ML projects are started without a clear alignment on expectations, goals, and success criteria of the project between the business and data science teams.
These kinds of projects will forever stay in the research stage itself because they never know if they are making any progress since it was never clear what the objective was.
Here, the data science team will be focused mainly on accuracy, whereas the business team will be more interested in metrics such as financial benefits or business insights. In the end, the business team ends up not accepting the outcome from the Data Science team.
Lack of Data Strategy
According to the MIT Sloan Management Review, only 50% of large enterprises with more than 100,000 employees are most likely to have a Data strategy. Developing a solid data strategy before you start the Machine learning project is critical.
You need to have a clear understanding of the following as part of Data strategy,
- The total data you have in the company
- How much of that data is really required for the projects?
- How will the required individuals have access to these data, and how easily those individuals can access them?
- Specific strategy on how to bring all these data from different sources together
- How to clean up and transform these data.
Most of the companies start without a plan or don’t start thinking that they don’t have the data.
Lack of Leadership Support
It is easy to think that “you just need to throw some money and technology at the problem and the result would come automatically”
We do not see the right support from the leadership to make sure of the needed conditions for success. Sometimes business leaders do not have confidence in the models developed by the data scientists.
This could be because of the combination of a lack of understanding of AI of the business leader and the inability of the data scientist to communicate the business benefits of the model to the leadership.
Ultimately, leaders need to understand how Machine learning works and what AI really means for the organization.
Published at DZone with permission of Prajeen MV. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments