Ultimate Guide to Kubernetes StatefulSets With a MongoDB Example
Explore managing stateful applications with Kubernetes StatefulSets — when to use them, how to deploy MongoDB, limitations, and best practices for implementation.
Join the DZone community and get the full member experience.
Join For FreeStatefulSet is a Kubernetes workload API specifically used for managing stateful applications. This is a comprehensive guide to setting up and using StatefulSets, where we look at the following topics:
- What is a StatefulSet, and when should you use it?
- Example: Setting up and running MongoDB as a StatefulSet
- Limitations of StatefulSets and what to watch out for
- Best practices while implementing StatefulSets
Stateless and Stateful Applications
Let's start with distinguishing stateless and stateful applications. A stateless application is one in which every request is treated as a new, isolated transaction independent of any previous transactions. It does not store session-specific data between requests, either on the client side or the server side.
Kubernetes is known for being great at managing stateless services. For a stateless application, pods are fully interchangeable — scaling up and down won’t result in any loss of data. Kubernetes Deployment is what we use to manage pods of stateless applications.
In contrast, stateful applications maintain data across sessions and transactions. They remember past activities and tailor user interactions based on this remembered state. For example, all databases are stateful.
So, how do we manage stateful applications in Kubernetes, given we cannot randomly restart or kill pods? This is where Statefulsets come into play.
What Is a StatefulSet?
A StatefulSet is a Kubernetes workload API object built for managing stateful applications that require stable network identities and persistent storage.
It provides certain guarantees about the ordering and uniqueness of pods and how they are deployed and scaled (see below).
- Ordering guarantees: When we deploy using a StatefulSet, pods are created sequentially and in order (unlike Deployments or ReplicaSets). This is relevant for systems where the startup order matters, such as distributed databases.
- Persistent identifiers: Each pod in a StatefulSet has a stable and predictable hostname, typically in the format <pod-name>-<ordinal-number>. Even if a pod is rescheduled, its identifier remains unchanged.
- Stable storage: When we use a StatefulSet, each pod is associated with persistent storage. This storage remains attached to the specific pod even if the pod moves to another node.
- Graceful scaling and updating: A StatefulSet allows applications to be scaled up or down in a controlled manner, ensuring operations like rolling updates don't compromise the integrity of the application.
Statefulset Controller
The StatefulSet Controller is a Kubernetes controller that watches and manages the lifecycle of pods created based on a StatefulSet pod specification. It sits at the control plane and is responsible for orchestrating the creation, scaling, and deletion of pods in the exact order as outlined in the StatefulSet definition.
Advantages of StatefulSets
- Predictability: StatefulSet ensures a predictable order of pod deployment, scaling, and deletion, which is paramount for applications like databases where the sequence of operations matters.
- Stability: Even if a pod in a StatefulSet crashes or the node hosting a pod fails, the pod's identity (name, hostname, and storage) remains consistent.
- Data safety: Paired with persistent volume claims, a StatefulSet ensures that each pod’s data is safeguarded. If a pod is rescheduled, its data remains intact.
- Easy discoverability and communication: Each pod gets its DNS, which makes service discovery and intra-pod communication more straightforward.
- Provisions for manual intervention: For those special cases where you need more control, a StatefulSet allows manual intervention without the system trying to "auto-correct" immediately.
The design and advantages of a StatefulSet provide a clear distinction from other Kubernetes objects, making it the preferred choice for managing stateful applications.
Deployment vs. StatefulSet
Let us see how StatefulSet differs from Deployment-
1. Podname and Identity
Deployment: Pods have an ID that contains the deployment name and a random hash
StatefulSet: Each pod gets a persistent identity with the Statefulset name and sequence number
2. Pod Creation Sequence
Deployment: Pods are created and deleted randomly
StatefulSet: Pods created in a sequence cannot be deleted randomly
3. Interchangeability
Deployment: All pods are identical and can be interchanged
StatefulSet: Pods are not identical and cannot be interchanged
4. Rescheduling
Deployment: A pod can be replaced by a new replica at any time
StatefulSet: Pods retain their identity when rescheduled on another node
5. Volume Claim
Deployment: All replicas share the same Persistent Volume Claim (PVC) and a volume
StatefulSet: Each pod gets a unique PVC and volume
6. Pod Interaction
Deployment: Needs a service to interact with pods
StatefulSet: Headless service handles pod network identities
When To Use Statefulset
Use Statefulsets when your application is stateful. Ask yourself - does your application require stable identities for its pods? Will your system be disrupted when a pod replica is replaced?
Replicated DBs are a good example of when you'd need a StatefulSet. One pod acts as the primary database node, handling both read and write, while other pods are read-only replicas. Each pod may be running the same container image, but each needs a configuration to set whether it’s in primary or read-only mode.
Something like:
- mongodb-0 – Primary node (read-write).
- mongodb-1 – Read-only replica.
- mongodb-2 – Read-only replica.
If you scale down a ReplicaSet or Deployment, arbitrary pods get removed, which could include the primary node in this MongoDB system.
However, when we use a StatefulSet, Kubernetes terminates pods in the opposite order to their creation, which ensures mongodb-2 gets destroyed first in this example.
StatefulSet Example: Running MongoDB in Kubernetes
Now, let us look at an example and run a MongoDB cluster in Kubernetes using a StatefulSet.
Step 1: Set up a Headless Service
The identity of pods in a StatefulSet is closely tied to its stable network identity, making a headless service vital.
A headless service is defined by having its clusterIP set to None, ensuring stable network identities for the pods.
Here's a YAML for our MongoDB service:
apiVersion: v1
kind: Service
metadata:
name: mongodb
labels:
app: mongodb
spec:
ports:
- name: mongodb
port: 27017
clusterIP: None
selector:
app: mongodb
Let’s deploy the service to the cluster:
$ kubectl apply -f mongodb-service.yaml
service/mongodb created
Step 2: Deploying the MongoDB StatefulSet
The following YAML is for the StatefulSet. It describes running three replicas of the MongoDB image:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongodb
spec:
selector:
matchLabels:
app: mongodb
serviceName: mongodb
replicas: 3
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo:latest
ports:
- name: mongodb
containerPort: 27017
volumeMounts:
- name: data
mountPath: /data/db
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
Now, let's apply the StatefulSet configuration:
$ kubectl apply -f mongodb-statefulset.yaml
statefulset.apps/mongodb created
Let's check the new pods to see them in action:
 Status of the pods
Status of the pods
We can see that the three pods are created sequentially, ensuring the initialization of one before the very next pod does.
Each new pod in this MongoDB StatefulSet will have its distinct Persistent Volume and Persistent Volume Claim. These claims are spawned from the StatefulSet's volumeClaimTemplates field.
Persistent Volumes provide a piece of storage in the cluster, independent of any individual pod that uses it. They are resources in the cluster, just like nodes are cluster resources. PVs have a lifecycle independent of any individual pod that uses storage volumes from the PV.
Let's look at the PVs.
$ kubectl get pv
...
The output shows the Persistent Volumes available in the cluster. For our MongoDB StatefulSet with three replicas, here's what we see:
$ kubectl get pvc
...

We see above the Persistent Volume Claims made by the three pods. Having dedicated storage ensures that our MongoDB instance retains its data irrespective of pod life cycles, which is vital for any database system.
Step 3: Scaling the MongoDB Cluster
Let's now see how to scale our MongoDB instances:
$ kubectl scale sts mongodb --replicas=5
statefulset.apps/mongodb scaled Let's confirm that the pods are created sequentially.
$ kubectl get pods
...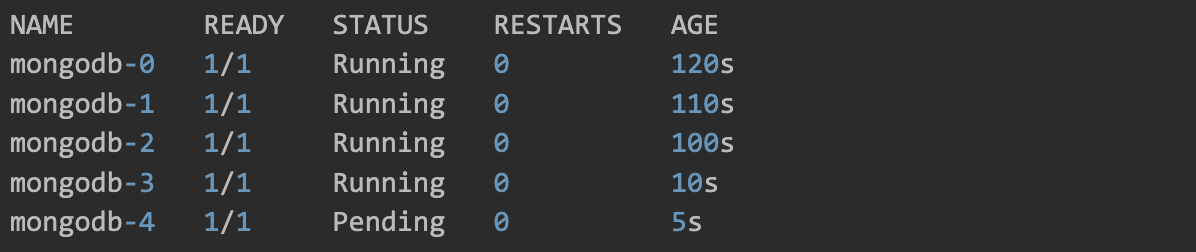
We can see here from the age that the pods were created sequentially and when.
Similarly, let's see how to scale down:
$ kubectl scale sts mongodb --replicas=2
statefulset.apps/mongodb scaled
Kubernetes will now terminate pods in the same volume in the reverse creation order.
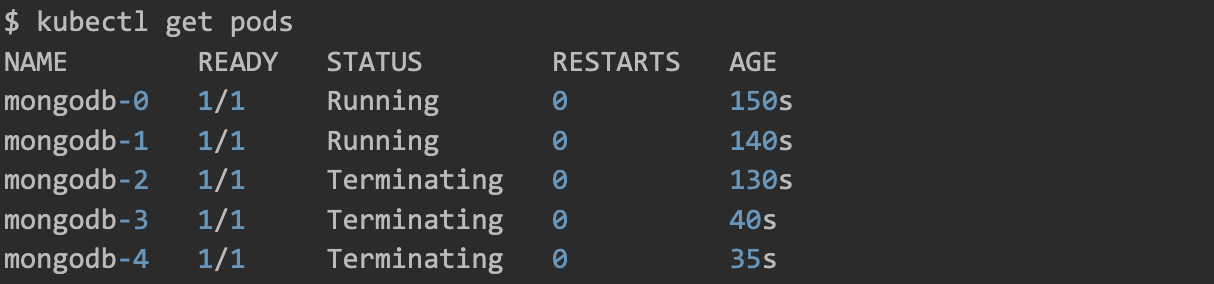
As you can see, the last pods are terminated first.
This example showcases how the StatefulSet ensures that MongoDB, a stateful application, runs smoothly, scaling when needed and retaining crucial data using Kubernetes.
Limitations of StatefulSets
While Kubernetes StatefulSet offers a host of options to manage stateful applications, there are some constraints. Understanding these constraints will help us make informed decisions for our specific use case.
1. Slower Rollout
The sequential scaling process of a Statefulset ensures consistency and order, but it also leads to slower rollouts, especially for large-scale applications.
2. Manual Intervention To Clean/ Restore State
If a pod in a StatefulSet becomes corrupt, simply deleting the pod may not always resolve the problem. The attached persistent storage might still contain one or more of the corrupted pods in the statefulset. In such cases, manual intervention might be required to clean or restore the state.
3. Resizing Is Complex
A StatefulSet is tightly bound to the storage resources of its Persistent Volume Claims (PVCs). Once a PVC is created, it can't easily be resized. If we need to expand storage volumes, we often have to undergo a more complex process depending on the storage provider you're using.
4. Backup Complexity
Backing up the data of the previous pod in a stateful application managed by a StatefulSet requires more thoughtful planning. We need to ensure data consistency across multiple pods, especially in distributed databases where data can be partitioned.
5. Challenges With Network Configurations
A StatefulSet relies on headless services for network identity. While this ensures a unique hostname, it introduces complexities, especially when we need to set up inter-pod communication or handle scenarios where specific pods need to be reachable externally.
Statefulset Best Practices
Given what we know about Statefulset, here are some best practices to keep in mind
1. Use Unique and Relevant Names for Your StatefulSets Pods
This helps in identifying and managing specific StatefulSets pods and their resources more easily.
2. Manage Initialization and Ordering
Use Init containers to perform pre-initialization tasks sequentially. This ensures that critical setup tasks, such as data population or configuration initialization, are completed before the main application container starts.
spec:
template:
spec:
initContainers:
- name: init-container-1
image: init-image-1
# Add init container configuration here
- name: init-container-2
image: init-image-2
# Add init container configuration here
containers:
- name: main-container
image: main-image
# Add main container configuration here
If your StatefulSet requires a specific order for pod initialization (e.g., a database primary must start before replicas), you can implement custom logic within your init containers or use tools like wait-for-it or wait-for to manage pod readiness.
3. Handle Scaling Carefully
Make sure you understand the dependencies and requirements of your stateful application before scaling a StatefulSet. Scaling up should preserve data consistency, while scaling down may require proper data migration or backup strategies. Use strategies like quorum-based replication or partitioning to maintain data integrity while scaling.
4. Define Pod Disruption Budgets (PDBs)
PDBs allow you to set policies that limit the number of pods that can be simultaneously disrupted during events like scaling down or maintenance. To define a Pod Disruption Budget for your StatefulSet, create a PodDisruptionBudget resource and specify the maxUnavailable field, which determines the maximum number of unavailable pods at any given time. For example, to ensure at most one pod is unavailable during scaling or maintenance, set maxUnavailable: 1.
Here's a quick how-to
A. Create a Pod Disruption Budget YAML file (e.g., pdb.yaml) for your StatefulSet
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: example-pdb
spec:
maxUnavailable: 1 # Adjust this value according to your requirements
selector:
matchLabels:
app: your-statefulset-label
B. Add the PDB to your Kubernetes cluster
kubectl apply -f pdb.yaml
5. Backup and Restore Data
Implement backup and restore mechanisms for the data stored in persistent volumes. This ensures data availability and resilience in case of failures or disaster recovery scenarios. You can use one of many backup tools or write custom scripts.
Observability and Troubleshooting for Statefulsets
In general, observability for a StatefulSet in Kubernetes is quite similar to that for a Deployment (both can be instrumented with the same metrics & logging solutions like Prometheus and FluentD), but there are some differences to consider.
In some ways, it is easier to track individual pods with Statefulset as StatefulSets assign stable, predictable names to their pods, such as pod-0, pod-1, etc. This allows us to troubleshoot/ debug more easily. In contrast, Deployments use random pod names, and we need to rely more on labels and selectors.
However, we'd want to track some additional metrics and logs for StatefulSets, like metrics that capture the state of individual pods, data distribution, data replication, synchronization, and consistency across pods. We might also want to monitor various pod states as we scale up or down, like "Pending," "Running," or "Terminating," to ensure that data is correctly moved or replicated during these transitions.
Similarly, for alerts — we'd typically want to include additional alerts related to specific pod behavior or state transitions, such as changes in replica count, identity, or storage utilization.
For a more comprehensive read on how to set up Observability well, see here.
Often, the most pesky issues are caused by Statefulsets, and they are harder to mock and debug. If you're in staging and trying to figure out if an issue is caused by a stateful application, instead of trying to mock the state of the Statefulset, you could use open-source tools like Klone to avoid mocking altogether and debug faster. There's also a category of emerging AI products like ZeroK.ai that automatically help identify likely causes using AI by running automated investigations on your Observability data that could be worth exploring.
Summary
In this article, we examined how StatefulSets work and how they differ from a Deployment. We set up and ran MongoDB as a StatefulSet and examined the limitations and best practices while implementing StatefulSets. StatefulSets go a long way in reducing the complexity of deploying and managing stateful applications in Kubernetes.
Published at DZone with permission of Vivek Badani. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments