Unleashing Powerful Analytics: Technical Deep Dive into Cassandra-Spark Integration
Cassandra-Spark integration enables fast, scalable, real-time analytics by combining Cassandra’s storage power with Spark’s distributed processing efficiency.
Join the DZone community and get the full member experience.
Join For FreeApache Cassandra has long been favored by organizations dealing with large volumes of data that require distributed storage and processing capabilities. Its decentralized architecture and tunable consistency levels make it ideal for handling massive datasets across multiple nodes with minimal latency. Meanwhile, Apache Spark excels in processing and analyzing data in-memory; this makes it an excellent complement to Cassandra for performing real-time analytics and batch processing tasks.
Why Cassandra?
Cassandra's architecture makes it particularly suitable for large-scale data operations. It is a NoSQL database. More specifically, it is a wide-column store, and according to the CAP theorem, it favors Availability and Partition tolerance (AP). It can trade performance to achieve stronger consistency through tunable settings, at the cost of performance.
Pros
- Decentralized: All nodes have the same role. There is no master or slave. Easier configuration.
- Linear Scalability: Offers the best read/write throughputs for very large clusters (although latency can be higher compared to other systems).
- Fault-Tolerant: Data is replicated across datacenters, and failed nodes can be replaced without downtime.
- Tunable Consistency: A level of consistency can be chosen on a per-query basis.
Cassandra is easy to set up and play with because it has auto-discovery of nodes and does not need a load balancer or a specific master configuration.
We can simply install three instances of Cassandra on three different nodes, and they can form a cluster automatically (each node only needs to be informed of another node’s IP address at first). Then, queries can be run against any instance.
Cons
Cassandra is a very efficient distributed database, but is not appropriate for all use-cases because:
- Cassandra tables are optimized for specific query patterns. To query on different criteria or using different ordering fields, extra Tables or Materialized Views must be created for those queries. Cassandra Query Language (CQL) sounds like you can query anything, like in SQL, but this makes it impossible.
- No aggregation or joining.
When combined with Apache Spark, a lightning-fast analytics engine, Cassandra becomes an even more formidable platform for performing complex analytics tasks at scale. In this article, we'll explore how Cassandra and Spark can be leveraged together to unlock the full potential of their data for analytics purposes.
Why Spark?
- Fast in-memory data processing
- Advanced analytics capabilities through MLlib
- Real-time stream processing
- SQL-like interface through Spark SQL
- Graph processing capabilities via GraphX
Setting up the environment
Before diving into analytics with Cassandra using Spark, it's essential to set up the environment. This typically involves deploying Cassandra clusters and configuring Spark to interact with Cassandra's data through connectors like the DataStax Spark Cassandra Connector or the Spark Cassandra Connector provided by Apache. Once the environment is established, users can seamlessly integrate Spark into their Cassandra workflows to perform a wide range of analytics tasks. There’s a variety of articles and resources out there that can help you with this:
[1]: https://cassandra.apache.org/doc/stable/cassandra/getting_started/installing.html
[2]: https://spark.apache.org/docs/latest/quick-start.html
[3]: https://github.com/datastax/spark-cassandra-connector (The glue for this experiment)
Key integration features
- Native Protocol Support: The connector uses Cassandra's native protocol for efficient data transfer.
- Predicate Pushdown: Query optimization by pushing filters to Cassandra before data transfer.
- Parallel Data Transfer: Leverages both systems' distributed nature for optimal performance.
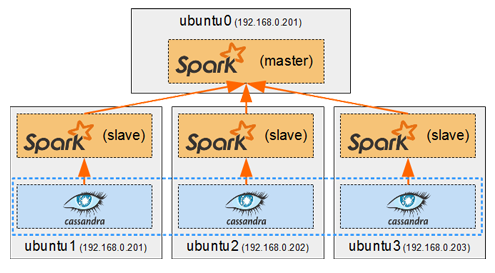
Performing analytics with Spark and Cassandra
One of the key advantages of using Spark with Cassandra is its ability to leverage Cassandra's data model and distributed storage for efficient data processing. Spark can directly read and write data to and from Cassandra tables, allowing users to run complex analytics queries, perform data transformations, and generate insightful visualizations using Spark's rich set of libraries and APIs.
Technical setup with Python
1. Dependency configuration
Include the connector in Spark sessions:
|
from pyspark.sql import SparkSession |
2. Data Loading and Predicate Pushdown
|
# Read from Cassandra with server-side filtering |
3. Advanced Transformations
|
from pyspark.sql.functions import udf |
4. Writing Results Back to Cassandra
|
df_processed.write \ |
Real-time analytics and stream processing
Spark's support for streaming data processing makes it particularly well-suited for performing real-time analytics on data ingested from Cassandra. By integrating Spark Streaming with Cassandra's Change Data Capture (CDC) capabilities or using tools like Apache Kafka as a message broker, organizations can analyze streaming data in near real-time, enabling timely decision-making and proactive insights generation.
The following example processes CDC logs from Cassandra using Spark Streaming:
|
stream = spark.readStream \ |
Machine learning and advanced analytics
In addition to traditional analytics tasks, Spark opens up possibilities for advanced analytics and machine learning with Cassandra data. By leveraging Spark's MLlib and ML packages, users can build and train machine learning models directly on data stored in Cassandra, enabling predictive analytics, anomaly detection, and other sophisticated use cases without the need for data movement or duplication.
The following is an example for training a K-means model on Cassandra data:
|
from pyspark.ml.clustering import KMeans |
Performance tuning and best practices
While combining Spark with Cassandra offers immense potential for analytics, it's essential to follow best practices to ensure optimal performance and reliability. This includes data modeling considerations for Cassandra tables, tuning Spark configurations for efficient resource utilization, monitoring cluster health and performance metrics, and implementing data governance and security measures to safeguard sensitive data.
1. Data Modeling:
- Align Spark partitions with Cassandra token ranges using repartitionByCassandraReplica
- Use wide partitions (10-100MB) to minimize overhead.
2. Write Optimization:
- Batch writes using spark.cassandra.output.batch.size.rows=500
- Use asynchronous writes with spark.cassandra.output.concurrent.writes=64
3. Cluster Configuration:
- Set spark.executor.memoryOverhead=1GB to avoid OOM errors.
- Enable speculative execution for fault tolerance.
4. Monitoring:
- Use Spark UI (port 4040) and Cassandra’s nodetool for latency/throughput metrics .
Conclusion
This technical guide demonstrates how to harness Cassandra’s distributed storage with Spark’s computational power for advanced analytics. By optimizing data pipelines, leveraging predicate pushdown, and integrating ML workflows, organizations can achieve sub-second latency for terabyte-scale datasets. For further exploration, refer to the Spark-Cassandra connector documentation.
Published at DZone with permission of Abhinav Jain. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments