Build a Serverless Application for Audio-To-Text Conversion
Learn how to use Amazon Transcribe and AWS Lambda to build an audio-to-text conversion application written in Go.
Join the DZone community and get the full member experience.
Join For FreeIn this blog post, you will learn how to build a Serverless speech-to-text conversion solution using Amazon Transcribe, AWS Lambda, and the Go programming language. Audio files uploaded to Amazon Simple Storage Service (S3) will trigger a Lambda function which will submit an asynchronous job to Amazon Transcribe (using the AWS Go SDK) which will, in turn, store the result in another S3 bucket.
You will be using the Go programming language for the business logic (thanks to the aws-lambda-go library) as well as the infrastructure component (Go bindings for AWS CDK) to deploy the solution.
The code is available on GitHub.
Introduction to Amazon Transcribe
Amazon Transcribe is a service that utilizes Machine Learning models to convert speech to text automatically. It offers various features that can enhance the accuracy of the transcribed text, such as language customization, content filtering, multi-channel audio analysis, and individual speaker speech partitioning. Amazon Transcribe can be used as a standalone transcription service or to add speech-to-text capabilities to any application. You can transcribe media in real-time (streaming) or you can transcribe media files located in an Amazon S3 bucket (batch).
Amazon Transcribe can be used for a variety of use cases, including:
- Customer service and support: Transcribe customer service calls, chats, and emails, enabling companies to analyze customer feedback, identify issues, and improve customer experience.
- Education and research: Transcribe lectures, seminars, and research interviews, allowing researchers and educators to create searchable, accessible text transcripts.
- Accessibility: Provide closed captions for live streams, webinars, and other events, making content accessible to viewers.
- Media and entertainment: Transcribe podcasts, interviews, and other audio content, enabling media companies to create searchable, accessible text transcripts.
Let's learn Amazon Transcribe with a hands-on tutorial.
Prerequisites
Before you proceed, make sure you have the following installed:
- Go programming language (v1.18 or higher)
- AWS CDK
- AWS CLI
Clone the project and change to the right directory:
git clone https://github.com/abhirockzz/ai-ml-golang-transcribe-speech-to-text
cd ai-ml-golang-transcribe-speech-to-text
Use AWS CDK To Deploy the Solution
The AWS Cloud Development Kit (AWS CDK) is a framework that lets you define your cloud infrastructure as code in one of its supported programming and provision it through AWS CloudFormation.
To start the deployment, simply invoke cdk deploy and wait for a bit. You will see a list of resources that will be created and will need to provide your confirmation to proceed.
cd cdk
cdk deploy
# output
Bundling asset LambdaTranscribeAudioToTextGolangStack/audio-to-text-function/Code/Stage...
✨ Synthesis time: 4.42s
//.... omitted
Do you wish to deploy these changes (y/n)? y
Enter y to start creating the AWS resources required for the application.
If you want to see the AWS CloudFormation template which will be used behind the scenes, run cdk synth and check the cdk.out folder.
You can keep track of the stack creation progress in the terminal or navigate to the AWS console: CloudFormation > Stacks > LambdaTranscribeAudioToTextGolangStack.
Once the stack creation is complete, you should have:
- Two S3 buckets - Source bucket to upload audio files and the target bucket to store the transcribed text files
- A Lambda function to convert audio to text using Amazon Transcribe
- A few other components (like IAM roles, etc.)
You will also see the following output in the terminal (resource names will differ in your case). In this case, these are the names of the S3 buckets created by CDK:
✅ LambdaTranscribeAudioToTextGolangStack
✨ Deployment time: 98.61s
Outputs:
LambdaTranscribeAudioToTextGolangStack.audiofilesourcebucketname = lambdatranscribeaudiotot-audiofilesourcebucket05f-182vj224hnpfl
LambdaTranscribeAudioToTextGolangStack.transcribejobbucketname = lambdatranscribeaudiotot-transcribejoboutputbucke-1gi0bu6r1d1jn
.....
You can now try out the end-to-end solution!
Convert Speech to Text
To try the solution, you can either use a mp3 audio file of your own. I really enjoy listening to the Go Time podcast. For demo purposes, I will simply use one of its episodes and upload (the MP3 file) it to the source S3 bucket using the S3 CLI.
export SOURCE_BUCKET=<enter source S3 bucket name - check the CDK output>
curl -sL https://cdn.changelog.com/uploads/gotime/267/go-time-267.mp3 | aws s3 cp - s3://$SOURCE_BUCKET/go-time-267.mp3
# verify that the file was uploaded
aws s3 ls s3://$SOURCE_BUCKET
This will invoke a batch transcribe job. You can check the status of the job in the AWS console: Amazon Transcribe > Jobs. Once it completes, you should see a new file (in the output S3 bucket) with the same name as the audio file you uploaded, but with a .txt extension. This is the output file generated by Amazon Transcribe.
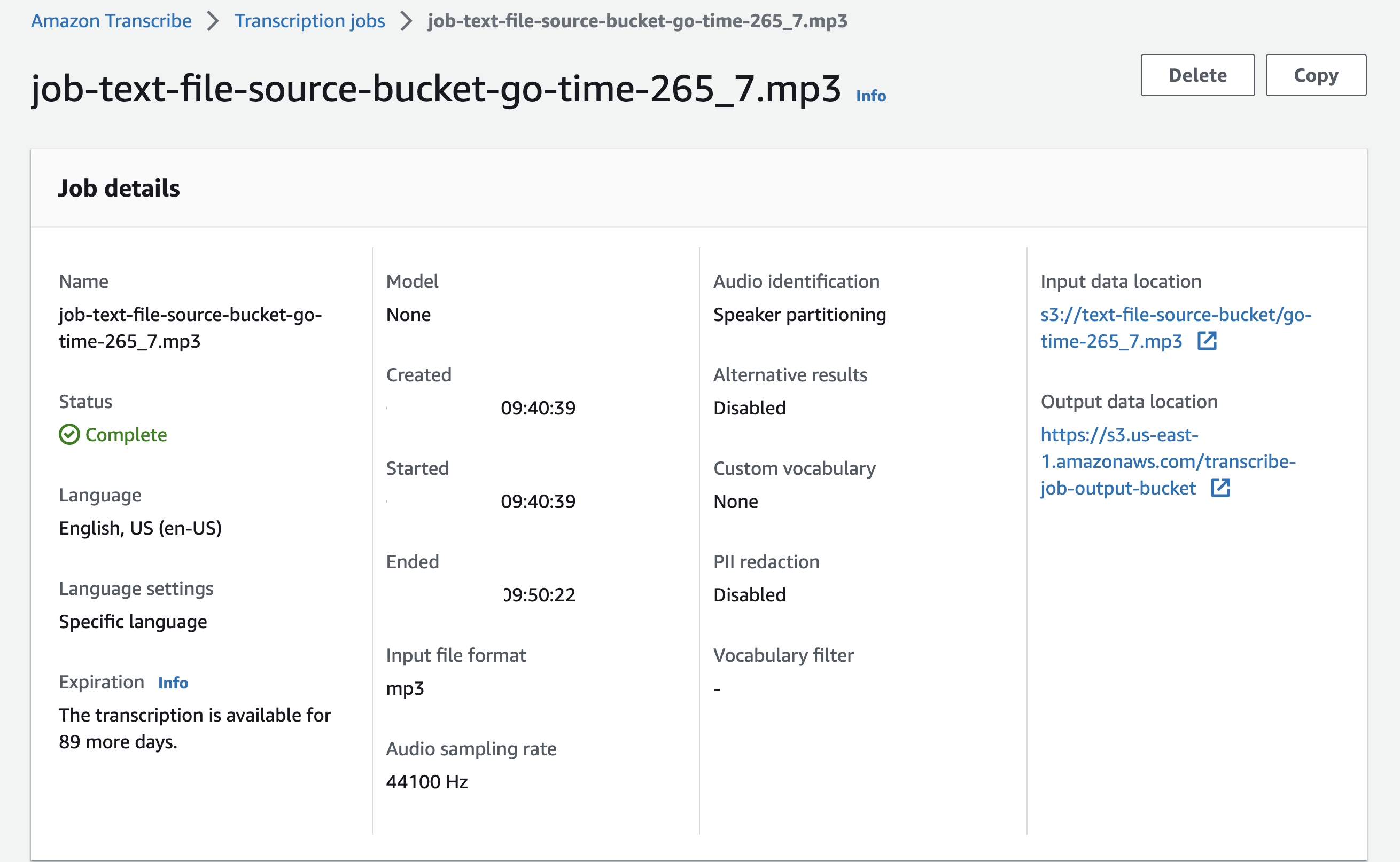
Download and open the output file.
export TARGET_BUCKET=<enter target S3 bucket name - check the CDK output>
# list contents of the target bucket
aws s3 ls s3://$TARGET_BUCKET
# download the output file
aws s3 cp s3://$TARGET_BUCKET/go-time-267.txt .
Interestingly enough, it has a JSON payload that looks like this:
{
"jobName": "job-go-time-267",
"accountId": "1234566789",
"results": {
"transcripts": [
{
"transcript": "<transcribed text output...>"
}
]
},
"status": "COMPLETED"
}
You can use the transcript property to extract the actual text.
Don’t Forget To Clean Up
Once you're done, to delete all the services, simply use:
cdk destroy
#output prompt (choose 'y' to continue)
Are you sure you want to delete: LambdaTranscribeAudioToTextGolangStack (y/n)?
You were able to set up and try the complete solution. Before we wrap up, let's quickly walk through some of the important parts of the code to get a better understanding of what's going on behind the scenes.
Code Walkthrough
We will only focus on the important parts: some of the code has been omitted for brevity.
CDK
You can refer to the complete CDK code here.
We start by creating the source and target S3 buckets.
sourceBucket := awss3.NewBucket(stack, jsii.String("audio-file-source-bucket"), &awss3.BucketProps{
BlockPublicAccess: awss3.BlockPublicAccess_BLOCK_ALL(),
RemovalPolicy: awscdk.RemovalPolicy_DESTROY,
AutoDeleteObjects: jsii.Bool(true),
})
outputBucket := awss3.NewBucket(stack, jsii.String("transcribe-job-output-bucket"), &awss3.BucketProps{
BlockPublicAccess: awss3.BlockPublicAccess_BLOCK_ALL(),
RemovalPolicy: awscdk.RemovalPolicy_DESTROY,
AutoDeleteObjects: jsii.Bool(true),
})
Then, we create the Lambda function and grant it the required permissions to read from the source bucket and write to the target bucket. A managed policy is also attached to the Lambda function's IAM role to allow it to access Amazon Transcribe.
function := awscdklambdagoalpha.NewGoFunction(stack, jsii.String("audio-to-text-function"),
&awscdklambdagoalpha.GoFunctionProps{
Runtime: awslambda.Runtime_GO_1_X(),
Environment: &map[string]*string{"OUTPUT_BUCKET_NAME": outputBucket.BucketName()},
Entry: jsii.String(functionDir),
})
sourceBucket.GrantRead(function, "*")
outputBucket.GrantReadWrite(function, "*")
function.Role().AddManagedPolicy(awsiam.ManagedPolicy_FromAwsManagedPolicyName(jsii.String("AmazonTranscribeFullAccess")))
We add an event source to the Lambda function to trigger it when a new file is uploaded to the source bucket.
function.AddEventSource(awslambdaeventsources.NewS3EventSource(sourceBucket, &awslambdaeventsources.S3EventSourceProps{
Events: &[]awss3.EventType{awss3.EventType_OBJECT_CREATED},
}))
Finally, we export the bucket names as CloudFormation output.
awscdk.NewCfnOutput(stack, jsii.String("audio-file-source-bucket-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("audio-file-source-bucket-name"),
Value: sourceBucket.BucketName()})
awscdk.NewCfnOutput(stack, jsii.String("transcribe-job-bucket-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("transcribe-job-bucket-name"),
Value: outputBucket.BucketName()})
Lambda Function
You can refer to the complete Lambda Function code here.
func handler(ctx context.Context, s3Event events.S3Event) {
for _, record := range s3Event.Records {
sourceBucketName := record.S3.Bucket.Name
fileName := record.S3.Object.Key
err := audioToText(sourceBucketName, fileName)
}
}
The Lambda function is triggered when a new file is uploaded to the source bucket. The handler function iterates over the S3 event records and calls the audioToText function.
Let's go through it.
func audioToText(sourceBucketName, fileName string) error {
inputFileNameFormat := "s3://%s/%s"
inputFile := fmt.Sprintf(inputFileNameFormat, sourceBucketName, fileName)
languageCode := "en-US"
jobName := "job-" + sourceBucketName + "-" + fileName
outputFileName := strings.Split(fileName, ".")[0] + "-job-output.txt"
_, err := transcribeClient.StartTranscriptionJob(context.Background(), &transcribe.StartTranscriptionJobInput{
TranscriptionJobName: &jobName,
LanguageCode: types.LanguageCode(languageCode),
MediaFormat: types.MediaFormatMp3,
Media: &types.Media{
MediaFileUri: &inputFile,
},
OutputBucketName: aws.String(outputBucket),
OutputKey: aws.String(outputFileName),
Settings: &types.Settings{
ShowSpeakerLabels: aws.Bool(true),
MaxSpeakerLabels: aws.Int32(5),
},
})
return nil
}
- The
audioToTextfunction submits a transcription job to Amazon Transcribe. - The transcription job is configured to output the results to a file in the target bucket.
- The name of the output file is derived from the name of the input file.
Conclusion and Next Steps
In this post, you saw how to create a Serverless solution that converts text to speech using Amazon Transcribe. The entire infrastructure life-cycle was automated using AWS CDK. All this was done using the Go programming language, which is well-supported in AWS Lambda and AWS CDK.
Here are a few things you can try out to improve/extend this solution:
- Build and develop another function that's triggered by the transcribed file in the output bucket, parse the JSON content, and extract the transcribed text. Update the CDK code to include this functionality.
- Try to generate transcriptions in real time with Amazon Transcribe streaming.
Happy building!
Published at DZone with permission of Abhishek Gupta. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments