Using a Possibility Tree for Fast String Parsing
Here is a high-speed user-agent parser with minimal string operations. Each character in the string is only visited once and used to traverse a trie of known products.
Join the DZone community and get the full member experience.
Join For FreeThe Raygun data processing pipeline is kept pretty busy — handling over 90 million crash reports daily. So, needless to say, we need the processing pipeline to be as efficient as possible to reduce resource usage and avoid costly scaling.
One of the many operations during processing is to parse a user-agent string (UA string) wherever one is present. We've gone through several rounds of performance optimizations over the years, and during one of these rounds, the user-agent parser stuck out as the slowest component. From the UA string, we determine the operating system, browser, device, and their versions (throughout this post, I’ll sometimes refer to all 3 of these things as “products”). This information is used for indexing so that Raygun users can filter their crash reports by these dimensions.
Here, we'll take a look at how we went about replacing the user-agent parser with a much more efficient implementation, using a possibility tree to speed up the parsing of data flowing through the Raygun processing pipeline by 45x. (While user-agent strings may be on the way out, my hope is that there are still some valuable lessons here about technical problem-solving and performance tuning that can be applied to plenty of other contexts.)
A Closer Look at the Problem
Let's take a look at how the original user-agent parser was working.
First, we passed the user-agent string to the parser, requesting it to determine the browser. The parser brute-force iterated up to a few hundred regexes one by one, seeing if any of them had a match on the user-agent string. The first regex that produced a match would have its result returned, including both the browser and its version.
This process was then repeated for the operating system and the device, each with its own set of a few hundred regexes. I winced when I came across this, knowing the slowdown even a single regex can have on performance.
Brainstorming
I couldn't imagine making this existing implementation much faster, so I started pondering about replacing it entirely. Around the time I looked into this, there was a bit of discussion among the Raygun team about how minimizing string operations is a good performance optimization direction. Iterating potentially several hundred regexes to parse a single user-agent string is a lot of string operations, so there's major room for improvement.
The first approach I considered was to break down the whole user-agent string into tokens and work out which tokens represent the different products. Because this approach isn’t looking for known products, an advantage this could have is automatically supporting new browsers, devices, and operating systems without needing to update the parser to specifically look for them. Unfortunately, there isn't a clear standard on how a user-agent string is formatted. Or at least, not everyone producing these strings follows the same pattern. So we can't just say, for example, “The 4th token is always the browser name”. We could probably analyze a lot of UA strings to derive some rules based on the most common patterns and then look out for edge cases that don't fit those. But still, I expected that this overall approach could result in a lot of `SubString` and `Compare` operations, so I kept exploring.
As I thought about this more, I pictured some software that could take a single pass over the user-agent string from start to finish and, once it reaches the end, has all the information it needed to parse out. One thing that helps here is that we already know a lot of the strings that we're looking for within the user-agent string. For example, we know that "Samsung," "Windows," and "Opera" could appear, and if they do, we've found some of the information that we need.
This all reminded me of a guest lecture I saw in university — there was a demo where, as a user is typing, we can take each character as it appears and traverse along a pre-initialized tree of possible next characters (a data structure known as a Trie in computer science). Based on the nodes of the tree that get traversed in this way, we can predict what known words the user is typing.
So here's what I came up with:
- When the user-agent itself is initialized, populate a tree of possible characters that lead to known browsers, operating systems, and devices.
- Iterate through each character of the user-agent string from beginning to end, as I’d imagined.
- As we start reading a new word in the user-agent string, keep track of a pointer that traverses the tree based on the characters visited in the UA string.
- If we reach a node that matches what was observed in the UA string, then we know that the token is present.
- Otherwise, we're reading a token that we don't have prior knowledge of (e.g., a new browser that's just come out or a string of characters that we're not even interested in).
- Regardless, we rinse and repeat for the next token until we reach the end of the UA string.
Getting Approval To Rebuild Something That Others Have Worked On for Years
Implementing an entire user-agent parser is no small feat. There are many, many products that can appear in user-agent strings. Not to mention, this keeps growing over time as new browsers, devices, and operating systems are released, so we constantly need to be on the lookout. Due to user-agent strings not necessarily following a strict, consistent pattern, we’d be spending a lot of time catering to many special cases. I’ll also mention here that I hadn’t had much prior experience with analyzing UA strings, so a lot of the decisions behind what products/versions to pull out came from a lot of online searching and comparing what _other_ user-agent parsers were returning.
After all this research, I proposed that we not build an entire user-agent parser. Instead, we’d collect a sample of the most common UA strings going through the Raygun processing pipeline and just focus on supporting those. Then, after parsing a UA string, if either the browser, device, or OS is missing, we would fall back to the existing parser to fill in any gaps.
We would also instrument the new user-agent parser to gauge how it’s performing and how often it’s falling back to the old parser. If performance starts to waiver due to an unsupported user-agent string becoming more popular, we will spend a little time adding support for this to the new parser.
Proposal approved.
Time To Get To Work
With a plan in place, I started modeling the tree and populating it with data. The core of the tree implementation is a Dictionary that maps from one of the possible characters to the next tree node.
private class TreeNode
{
public TreeNode()
{
Children = new Dictionary<char, TreeNode>();
}
public Dictionary<char, TreeNode> Children { get; }
public string Result { get; set; }
public TreeNodeType Type { get; set; }
}The Result property is set on nodes that have reached a fully known token. If we traverse to one such node, we can grab this pre-initialized Result from it, rather than using substring to extract it out of the UA string or recreating it from the characters traversed through the tree. The Type property is an enum that’ll tell us whether the token is intended to be used for the browser, device, or OS.
The data to populate the tree is stored within a plain text file. Headers such as “# Browsers:” are used to identify the different types of products. To begin with, I added a few tokens that have some commonality.
# Browsers:
Safari
# Devices:
Samsung
Samsung Galaxy
Samsung Nexus
# OperatingSystems:
AndroidDuring the initialization of the user-agent parser, the tree population algorithm reads each character of each line and traverses the tree that’s been accumulated so far. When it comes across a node that doesn't contain a character already read, it then adds a new node to the tree.
Figure 1: A Trie Populated With a Sample of Product Names
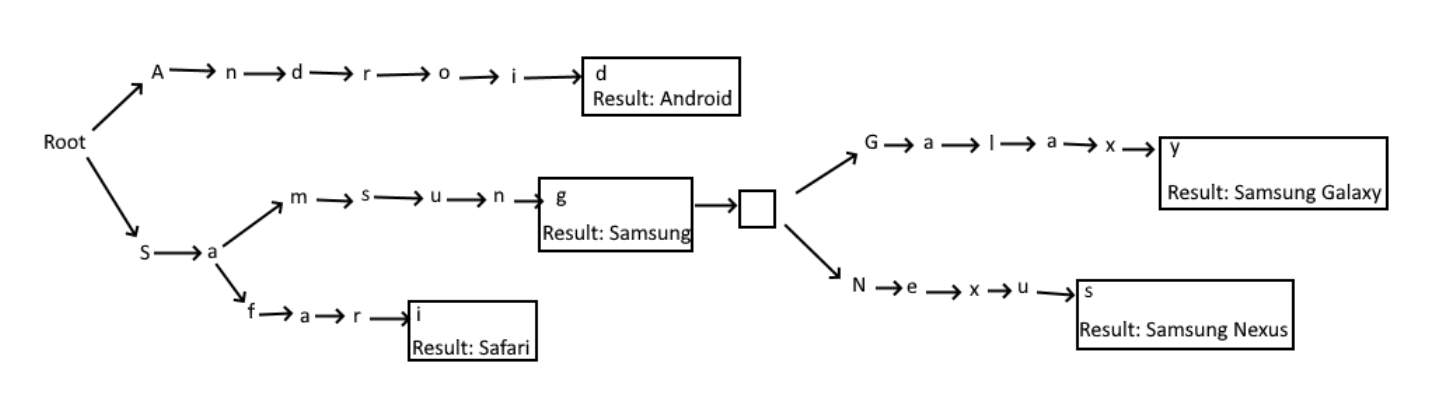
With the tree model populated with some initial data, it's time to try to fetch out tokens that match within a given UA string. Below is a simplified version of the core parsing algorithm. Note that although there are nested loops, the inner loops are advancing the same variable as the outer loop - so that each character is only visited once.
private static List<TreeNode> ExtractTokens(TreeNode root, string uaString)
{
List<TreeNode> tokens = new List<TreeNode>();
int uaStringLength = uaString.Length;
for (int i = 0; i < uaStringLength; i++)
{
TreeNode candidateTreeNode = null;
TreeNode currentTreeNode = root;
// At the beginning of each iteration of the main loop,
// traverse the possibility tree until we find, or fail to find a known product.
while (i < uaStringLength)
{
char currentChar = uaString[i];
currentTreeNode.Children.TryGetValue(currentChar, out TreeNode next);
if (next != null)
{
if (next.Result != null)
{
candidateTreeNode = next;
}
}
else
{
break;
}
currentTreeNode = next;
i++;
}
if (candidateTreeNode != null)
{
tokens.Add(candidateTreeNode);
}
else
{
// If we reach this point, then we do not recognize the product.
// The loop variable 'i' might now be in the middle of said unknown product.
// Increment i until the next known product delimiter, ready for the next round of the main loop.
while (i < uaStringLength)
{
if (_productSeparators.Contains(uaString[i]))
{
break;
}
i++;
}
}
}
return tokens;
}The code above contains our top-level loop that iterates each character of the UA string. For traversing the tree, we keep track of the tree node we're currently on, which starts from the root node. A nested while loop further iterates along the UA string while looking up each character from the tree node that we're up to. If we come across a tree node with the `Result` property set, we take note of it and keep going.
In the small sample of tokens I listed above, we could come across Samsung but subsequently find that it's actually Samsung Galaxy after continuing to traverse the characters. When this happens, we replace the previous candidate's Result that we'd found with the latest match.
Once we find there is no child node matching the next character, we break out of the while loop. If we find a matching token, we add the tree node to a “tokens” list that later gets returned from the method. If not, the UA string pointer could currently be in the middle of a word, so we advance the pointer to the next separator character (brackets, semicolon, space, slash, or comma) without bothering to consult the tree. Stepping to the next character, we reset the current tree node to be the root and repeat the token-matching process until we reach the end of the UA string.
Testing what I’ve built so far with this UA string:
Mozilla/5.0 (Linux; Android 4.2.2; de-de; Samsung Nexus S Build/JDQ39) AppleWebKit/535.19 (KHTML, like Gecko) Version/1.0 Chrome/18.0.1025.308 Mobile Safari/535.19
We ended up fetching the correct "Samsung Nexus" token.
Returning Different Text Than What Appears in the UA String
Sometimes, the characters we scan through the UA string don't exactly match what we want to be displayed to the user.
Take, for example, "HTC-HTC_Desire_," which can appear in a UA string, but we want it to be reformatted to "HTC Desire". We can make use of the existing Result property on the tree to state what we want the token to actually be expressed as. To let the initialization code of the tree know to use different wording, I updated the plain text file to add a vertical bar followed by the desired text:
HTC-HTC_Desire_|HTC Desire
When populating the possibility tree, if this vertical bar is present, the text after the vertical bar is what gets set on the Result property. This catered for a large number of name corrections—adding spaces, removing duplicate text (like the example above), adding missing manufacturer names, making casing consistent, etc.
Consider Casing During Initialization, Not While Parsing
Known tokens can appear with different casings within UA strings. For example: “Android,” “android,” or “ANDROID,” which we want to all consistently match the known OS cased as “Android." The way that I’d originally supported this was lowercasing all tokens as the possibility tree was being populated and then lowercase every character visited in the UA string before looking it up in the tree.
While performance profiling this user-agent parser implementation, this lowercasing operation was taking a lot of time, so I had to get rid of it. To achieve this, I moved the casing concerns into the initialization of the possibility tree. Every time we add an alphabet character to the dictionary, we map both the lowercase and uppercase characters to the same next tree node. The Result property then, of course, gets set to the consistent casing that we want to appear in Raygun. Now, while iterating the characters of the UA string, we can traverse the tree in the same way, no matter what case variation a product can appear in the UA strings. This simple change improved the overall performance of this parser implementation by about 25%!
Compressing the Possibility Tree
Another slow aspect of this implementation was the dictionary lookups. A single lookup is quick, but it all adds up—and the core operation of this implementation is to perform lots of dictionary lookups. So, I was looking for a way to reduce this. By analyzing the structure of the tree, I noticed that there were a lot of long tendrils that didn’t branch. You can see an example of this in Figure 1 with “N e x u s” and “G a l a x y, " etc.
To reduce the dictionary lookups, I compressed these long tendrils into single nodes. To do this, I introduced a RemainingCheck property to the tree nodes that stores what used to be spread out across multiple nodes. These data structures are known as Radix Trees or Patricia Tries in computer science. The previous example of the tree structure would be simplified to this:
Figure 2: Compressed Version of Figure 1
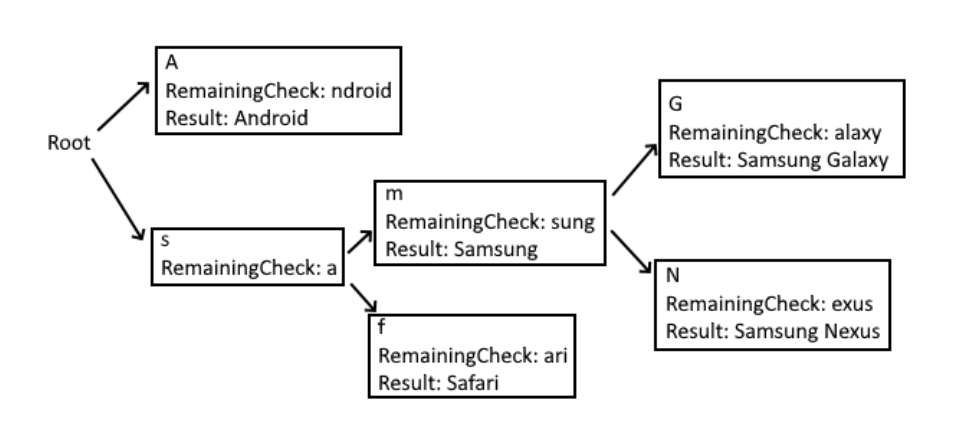
When reaching one of these compressed nodes, the parsing logic will stop traversing the tree and instead iterate the characters of the RemainingCheck and compare them with the next characters in the UA string that we’re up to. Unfortunately, these compressed nodes lost the ability to use the casing optimization I mentioned above. The reduced dictionary lookups, however, still meant there was a performance gain. When checking each character against the RemainingCheck (which was always initialized as lowercase), we first do an exact match and only lowercase the character from the UA string if it doesn’t match. Most casing inconsistencies are found at the beginning of a product name, whereas the RemainingCheck generally deal with the end of the product name. This meant that performing lowercase operations here was uncommon, which helped.
Handling UA Strings That Mention Multiple Products
As I started adding support for more products to the possibility tree, one of the challenges I encountered was that sometimes a UA string would mention multiple different products. I believe this is because one product could be leveraging the underlying technology of another. Take, for example, the following UA string:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.9600
This contains mention of Chrome, Safari, and Edge. The actual result we want here is Edge. The new user-agent parser at this stage will return a collection containing all 3 of these matching tokens because Chrome and Safari are also tokens we look for in other UA strings.
The way the existing user-agent parser handled this was by listing the Regexes in a specific order. The first one that produced a match would return its result. So, I solved this problem in a similar way. I reordered the entries in the plain text file used to populate the possibility tree so that Edge took precedence over Chrome and Safari. The tree structure, of course, loses this ordering, so I added a new Order property to the tree nodes to maintain it. Any node that had the Result property set to signify a matching token would also be provided the numerical Order, which appears in the initialization file.
In the ExtractTokens code snippet above, we’re returning a collection of matching tree nodes. After fetching this collection, we can group by Type and then extract the token with the lowest Order. Note that it’s faster to iterate all of them to find the minimum rather than bothering to sort the collection (O(n) versus O(n log n) complexity).
Parsing Out the Product Versions
So far, we’re able to determine known browser, OS, and device token names out of the user-agent string, but there’s another piece of information that we can’t prepopulate into the tree—the version numbers. Most of the time, the version number immediately follows the name, generally separated by a space or a slash. So, after finding a match on a known name, we need to find a start and end index following the name that we can use to substring the version out of the UA string.
The ExtractTokens method is now going to need to return a different model to include this additional information we need for each token. Note that at this stage, we’re just including the start and end index rather than doing a substring to extract the actual value. Remember how I said that we could find multiple browser tokens, but we only need one of them? If we wait to substring out the version for just the token that’s later deemed to be the one we want, we can minimize the substring operations to squeeze a little more performance out of this thing. After all, the fastest thing to do is nothing.
private class UserAgentToken
{
public TreeNode Product { get; set; }
public int VersionStartIndex { get; set; }
public int VersionEndIndex { get; set; }
}After the parser finds a matching token, we use the following code to continue iterating over the UA string to determine the start/end indices of the version:
// Simple preliminary check to see if the current character is a valid first character of a version.
if (char.IsDigit(uaString[i]) || char.IsLetter(uaString[i]))
{
currentToken.VersionStartIndex = i;
if (i == uaStringLength - 1)
{
// Special logic for reaching the end of the UA string. Break out of the main loop.
currentToken.VersionEndIndex = uaStringLength;
break;
}
// Micro optimization - we know the current character passed the preliminary 'is version' check.
// So move to the next character now.
i++;
// Loop past characters to determine when we reach the end of the version:
// This code has been simplified - we actually look out for different characters depending on if we are parsing a Browser or an Operating System etc
bool endVersion = false;
while (i < uaStringLength)
{
if (!char.IsDigit(uaString[i]) && uaString[i] != PERIOD && uaString[i] != DASH && uaString[i] != UNDERSCORE)
{
endVersion = true;
break;
}
i++;
}
if (endVersion)
{
// Successfully found the version for the current product.
currentToken.VersionEndIndex = i;
if (uaString[i - 1] == PERIOD || uaString[i - 1] == DASH)
{
currentToken.VersionEndIndex—;
}
}
else if (i >= uaStringLength - 1)
{
// Special logic for reaching the end of the UA string. Break out of the main loop.
currentToken.VersionEndIndex = uaStringLength;
break;
}
}
else
{
// The preliminary 'is version' check failed.
// 'i' is currently at the first character of what we thought might be a version.
// We decrement this now to cancel out the effects of incrementing 'i' when the loop continues.
// That way, 'i' is ready for the next loop - the first character of the next product scan.
i--;
}But that's just the easy part of looking up versions. Now, we encounter the nightmare of user-agent string parsing — the version that follows the product name isn't always the actual version of the product. Sometimes, we need to transform them in various ways, look up the version from elsewhere in the UA string, or both. Sometimes, there are even obscure situations specific to a single product that are completely different from everything else. To tackle this, I created the `IVersionMapper` interface with a variety of implementations.
private interface IVersionMapper
{
string GetVersion(string uaString, int startIndex, int endIndex, List<UserAgentToken> tokens);
}I updated the text file that populates the tree so that each line can describe what version mapper to use and any options that come with it. Here’s an explanation of what a couple of the common ones did.
Getting the Version From Elsewhere in the UA String
Sometimes, the version we're looking for doesn't come directly after the token. The following UA string is for “BlackBerry Browser,” which is near the beginning of the string, but the version that we want actually follows the later "Version" token. The `RedirectedVersionMapper` is configured with the name of the token to retrieve the version from instead.
Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en - GB) AppleWebKit/534.8 (KHTML, like Gecko) Version/7.1 Mobile Firefox/78.11
Mapping the Version in the UA String To Something More Generally Recognized
Sometimes, we want to change the version to something more commonly recognized. For example, in the UA string below, we can see “Windows NT 6.0”, which we want to display as “Windows Vista.” The `VersionToVersionMapper` gets configured with a dictionary that maps versions we can find in the UA string with the version that we actually want to display. After parsing out the version in the usual way from the UA string (6.0 in this case), `GetVersion` will return what it's been mapped to instead or the extracted version if there is no matching map.
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; chromeframe; SLCC1; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729)
Performance Comparison
With all of that implemented and unit-tested across 19,074 assertions, let's see how it all performed in the end.
Both parsers are implemented as singletons that need a one-time initialization to prepare for parsing. Below, we can see that the new parser takes longer to initialize and uses more memory—but keep in mind that the new parser also includes the old parser as part of its initialization to fall back on for products that I didn't include. Looking at the difference between them, I'm pleased that the new parser hasn't added much overhead. Yes, the overall resource usage has increased here, but as this only happens once on the startup of a worker, we're not concerned.
Method | Mean | Error | StdDev | Gen 0 | Gen 1 | Gen 2 | Allocated |
------------------- |-----------:|----------:|----------:|----------:|----------:|---------:|------------:|
Regex Parser | 130.755 ms | 3.6769 ms | 3.0703 ms | 6062.5000 | 2000.0000 | 625.0000 | 34930.11 KB |
Possibility Parser | 133.597 ms | 1.3170 ms | 1.1674 ms | 6433.3333 | 2125.0000 | 687.5000 | 36720.44 KB |How does it fare in the worst-case scenario? That is, the new parser has no knowledge of anything within the user-agent string and so falls back to the old parser all three times. The user-agent string for this test is:
SonyEricssonS302c/R1BB Browser/OpenWave/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1
As expected, we're taking longer and using more memory here because we're taking all the time to (unsuccessfully) try lookup tokens with the new parser, and so we're doing all the work with the old parser anyway. It's great to see this increase in time is minimal though, considering the new parser is still scanning over the entire string and traversing the tree multiple times.
Method | Mean | Error | StdDev | Gen 0 | Allocated |
------------------- |---------:|----------:|----------:|-------:|----------:|
Regex Parser | 3.391 ms | 0.0670 ms | 0.0688 ms | 7.8125 | 37.88 KB |
Possibility Parser | 3.462 ms | 0.0678 ms | 0.0781 ms | 7.9211 | 38.56 KB |For something more interesting, let's see how it handles a best-case scenario — that is, a user-agent string for which the new parser is able to fetch all the information we want without falling back to the old parser. For this test, I executed the following user-agent string:
Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_2 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5
Previously, the old parser would take 2.7 milliseconds, while the new one is down to 3 microseconds! At least a 900x improvement! Memory usage has decreased as well.
Method | Mean | Error | StdDev | Gen 0 | Allocated |
------------------- |---------:|----------:|----------:|-------:|----------:|
Regex Parser | 2.724 ms | 0.0503 ms | 0.1005 ms | 7.9063 | 34.13 KB |
Possibility Parser | 0.003 ms | 0.0002 ms | 0.0001 ms | 0.4044 | 1.66 KB |Last of all, we want to test this new parser against real data flowing through the production Raygun processing pipeline. We captured a random sample of 132,742 user agents and passed them through both the old and new parsers. The old parser took 396,767ms while the new parser completed in 8,752ms — a 45x improvement! This confirms that the performance gain of the new parser handling the most common cases outweighs the extra time spent on the cases where we need to fall back on the older one.
Conclusion
Scanning the user-agent string just once by traversing a possibility tree of known tokens was a successful way to improve our UA string parsing. Although it looks like user-agent strings may be used less commonly, this use of a trie could be applied in a range of contexts, so here's hoping this gives you a few ideas about similar approaches to solve other performance challenges.
This performance improvement allowed us to spend less on processing resources to handle more traffic. Beyond this improvement, the new parser was also able to provide a more accurate result in a lot of cases. We were previously seeing a double-up of manufacturer names, missing information in some names, and the inclusion of information we didn't want, like service provider names and mobile screen dimensions. Sometimes, the country code would be used as a device model number. The casing was inconsistent, resulting in skewed statistics on how many different types of devices were affected by a crash report, and sometimes, the result would be a random section of garbage that the regexes pulled out of the UA string. Fixing all of this increased the quality of the service we provide to our customers. What I thought was going to be a frustrating slog turned out to be an interesting challenge with satisfying results.
Published at DZone with permission of Jason Fauchelle. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments