Using AWS DMS for Data Migration From On-Premises Oracle 19 to AWS RDS PostgreSQL: Insights From Practical Migration
This article presents an in-depth look at insights from database migrations from on-premises Oracle 19 to AWS RDS PostgreSQL using AWS Data Migration Service.
Join the DZone community and get the full member experience.
Join For FreeAWS Data Migration Service (DMS) has been built to be a Swiss knife for data migrations. This article supports 13 sources and 15 target datastore types across on-premises and AWS Cloud. The only condition is that either one of the sources or target must be on AWS.
Applications that are under the wave of cloud migration and transformation, basically any approach to modernize and be cloud-native, must grapple with the question of data sooner. Application modernization/migration is but one use-case of data migration. Building data pipelines with Data Warehouse, Data Lake, and CDC for streaming solutions such as EDA, CQRS and Search, and many more. AWS Data Migration supports many of these use cases.
Having used AWS DMS for on-premised Oracle 19 to AWS RDS PostgreSQL migrations multiple times for cloud app migrations, I have recorded a series of insights (challenges and mitigation) emanating from the experiences, failures, hit and trials, and facts about source DB is set up on-premises. These can be seen as lessons learned or good choices, but in my opinion, are too commonplace for any reasonably complex heterogeneous data migration case. The migrations I reference from my work were always Full Load followed by Ongoing Replication (CDC). So, there was always a case for planning data migration in conjunction with application roll-out.
Here is a list of the insights :
- Segregate DMS infrastructure on AWS
- Risks of Elevated Oracle privileges for a Migration User
- Migrating Sequences
- Oracle Native Network Encryption vs. Oracle SSL Wallet
- Handling Oracle DBLink
- Validation state freeze for large tables on DMS Console
- Controlling Migration Concurrency and Batching
- Use DMS rules and filters to make migration predictable.
- Automate With Schema Conversion Tool
- Critical Metrics to Track
- DMS Migration Task — Validation and Pre-Migration Assessment
- Unavoidable Maintenance Windows
The article does not aim to explain the setup of AWS DMS and assumes familiarity with the fundamental AWS services. AWS DMS service is documented exceedingly well by AWS.
High-Level Design
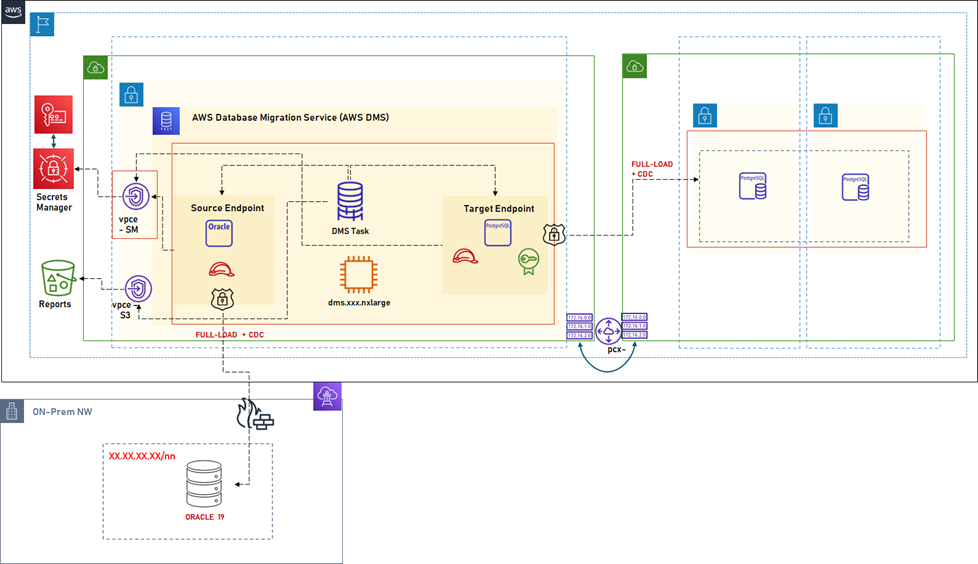
Fig. 1 – DMS Design
The design is simplified to represent a few essential components and concepts:
AWS Direct Connect: Obviously, for the hybrid data migration, high-speed connectivity between AWS VPC and On-Prem must be in place. In this case, there is a redundant AWS Direct Connectivity, and the DMS VPC uses the shared services Transit Gateway connected to the DMS VPC. The outbound endpoint (the source endpoint) in DMS makes a connection across the TGW to the Oracle instance for both full load and ongoing replication. This is the most fundamental setup.
Network Segregation and Peering: Explained more later, the DMS has been set inside its own VPC with a subnet group in the DMS VPC across two AZs to support DMS services. This choice is different from how AWS explains the potential topologies in the DMS documentation. The reasons and benefits are explained in upcoming sections.
With both Direct Connect and network segregation and peering, the data does not leave a single region. There is no cross-region data movement. This is a critical requirement for data residency for the client info sec mandate.
DNS Resolution from VPC: Although an IP address-based lookup often works, if using a CA certificate and a hostname check, the ability to do a DNS lookup from VPC to on-premises services is valuable. To enable DNS query resolution from DMS VPC, the VPC uses AWS-provided DNS lookup via Route53. Route53 is configured with a rule to delegate the DNS lookup to an Outbound DNS resolver that forwards DNS lookup queries for common on-premises domains to an on-premises DNS server.
IAM Roles: The DMS task, source, and target endpoints assume roles during various phases of the migration lifecycle. Creating a role for the DMS with least and specific privileges, along with narrow network access between security groups within the DMS VPC or with the peered RDS VPC.
Having set the background and some insights in the design, the sections to follow explain a series of decisions or practices followed during the migration to address specific issues and some insights on how key aspects of migration were handled pragmatically.
1. Segregate DMS Infrastructure on AWS
AWS DMS works with several individual services that are composed together in a data migration task. Most of these resources are VPC bound. It is possible to set up the entire DMS in the “app VPC,” i.e., the VPC where the target database (in our case AWS RDS PostgreSQL) is hosted. There are different topologies recommended by AWS. The one that we came out was emerged (refer to the design in Fig. 1) with a selective combination of those, where DMS is hosted in its own dedicated VPC and peered with the RDS VPC. A VPC endpoint with PrivateLink would have worked as well. This topology provided several advantages:
- DMS infrastructure, in this case, is temporary and needed only during the migration. So, the application services and infrastructure are isolated from a DMS infrastructure to maintain the lifecycle of these services cleanly.
- The Terraform IaC pipelines are separate and clean. Any change in either does not impact the terraform state across, which would not have been if DMS infrastructure co-existed with the “app VPC.”
- Enabling network ingress from a different DMS VPC than application VPC makes the routing rules, security groups, and NACLs in application VPC unimpacted due to DMS connectivity with an on-premises network. This also enhanced security since the on-premises network access is granted only for the specific reason of data migration.
2. Risks of Elevated Oracle Privileges for a Migration User
Depending on the scope of migration, the task can be a one-time full load and/or a continuous replication, a.k.a CDC, that is based on the Oracle Log Miner API that allows the read of the redo logs (online or archived redo logs). The DMS user for the source oracle endpoint is required to have SELECT grants on system tables, ALL_* DB objects & V_$* objects. In addition, the user also needs EXECUTE grant on DBMS_LOGMNR. This privilege set is elevated and more powerful than the usual app DB user that is provided basic CRUD access. Two more pertinent problems:
- That these grants cannot be restricted to specific schemas that are in the scope of migration and, once granted, provides access to all database schemas on Oracle 19 instance.
- And the user needs to be set in AWS Secrets to configure the source endpoint for the DMS migration task.
Depending on how the organization sees it, this may be seen as a showstopper. I had to raise a security risk, and that had to be accepted after a lot of deliberation, mostly because no equivalent solution was available. These grants were provided for a specific migration window and then removed. The migration window and, thus, the exposure of grants is important, especially for CDC, which is a long-running, continuously replicating process.
Getting the understanding of privileges right and organizational acceptance of the risk is the single most crucial step, one which I had to spend many weeks.
3. Migrating Sequences
We had extensive usage of Oracle sequences to generate incrementing sequences of numbers, used as an identifier and a PK for entities. DMS does not migrate the sequence state. The sequence number generated and used in a table is migrated as part of table data during the full load and the CDC. Once migration is done, sequences in PostgreSQL need to be re-based; otherwise, new inserts would result in PK violation errors. This scenario is explained below.
Before migration, Oracle Sequence has reached some usage numbers and is used by entities to furnish the next sequential number.
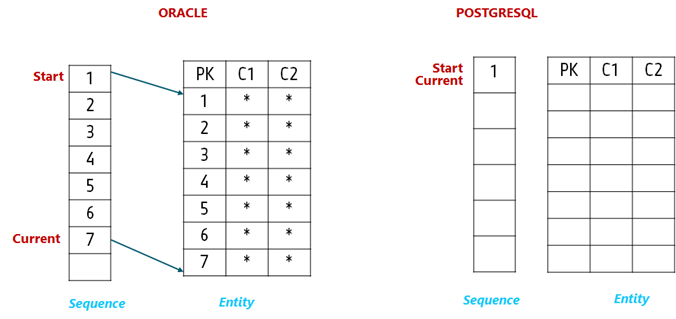
After data migration is finished (i.e., both full load and CDC), the PostgreSQL table is populated with the data by DMS. However, the state of the sequence in PostgreSQL remains unchanged.

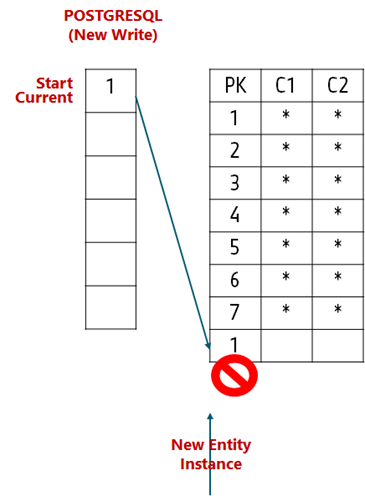
On a new write in PostgreSQL, the sequence will furnish a starting number, which is likely to be present in the table via the old Oracle sequence value generated when the data was active on Oracle.
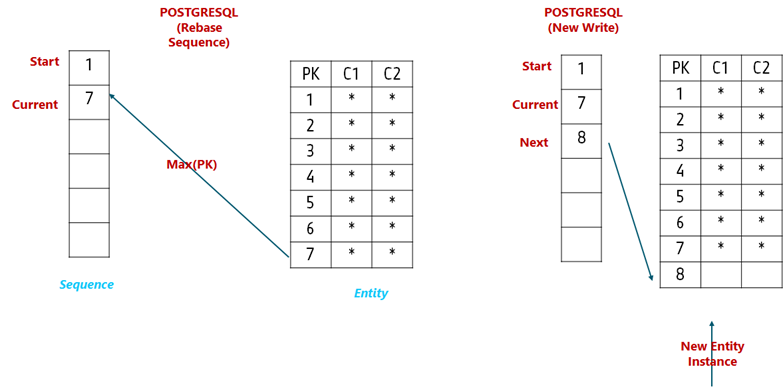
To prevent this, an additional step to rebase the sequences should be carried out before write traffic is allowed in PostgreSQL. The rebase would take the maximum value from the entity PK that refers to the sequences for values and update the sequence state
4. Oracle Native Network Encryption vs. Oracle SSL Wallet
AWS DMS allows the uploading of a public client certificate for the source and target endpoints. This allows the DMS task to use the CA certificate-based SSL connection across all phases. For Oracle as a source, the client certificate needs to be set up as Oracle Wallet, which needs to be configured in the TNS listener. Another way to encrypt the connections is via the use of Oracle Native Network Encryption (NNE), which allows connection encryption. NNE allows the secure Oracle Client and Oracle Instance to announce cryptography information and generate a secure key. With this option, no separate SSL key needs to be set up.
While DMS documentation goes into good detail on how to set up the Oracle Wallet, there isn’t much on how NNE is supported. We spent a great deal of time getting the Oracle admin to set up the wallet (with our understanding that that is the only way to encrypt connections), but it turns out that if NNE is enabled, DMS can communicate with Oracle source using NNE. This was confirmed by monitoring the sessions from DMS.
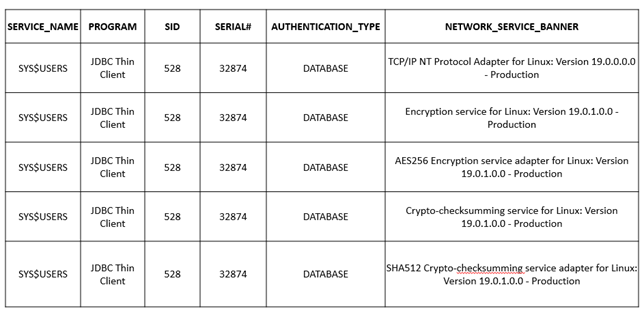
Apparently, on the same TNS listener, setting up both NNE and Wallet are not permitted (or not encouraged). Using either one of the two is usually enough. While using the NNE, the source endpoint cannot have a certificate imported and needs to have thus ssl_mode as none.
5. Handling Oracle DBLink
Oracle DB link is a feature that allows one oracle instance to create a proxy connection for another database to create a view of the target data, which is accessed locally in the source schema. The two databases are presented as one logical database to the client application.
DBLink is contentious in the microservices world. DBLink is an indirect way for one service to cross the boundaries and access the database for another service, albeit in a database-provided feature. So, whether these should be used as a pattern is a contextual discussion depending on the boundaries of the data that DBLink accesses.
When data and schema for Oracle are being migrated, the DBLink is not migrated automatically to an equivalent PostgreSQL feature. If this feature needs to be supported in the target platform as well, the DBLink will have to be handled separately.
The data migration is complimented with the application migration, and in the target state, these scenarios may exist:
- The migrated PostgreSQL needs to integrate with legacy Oracle with integration via the database itself. Possibly because the legacy application is not able to provide alternate means of integration.
- The application integrated via DBLink is not migrated along with the database to AWS RDS PostgreSQL, but there is no ReArchitecture of legacy service to provide integration via published interfaces.
In these scenarios, the integration would still need to be supported via PostgreSQL, creating proxy connections and views by connecting to upstream legacy oracle or upstream migrated PostgreSQL.
To enable this pattern, use the PostgreSQL Foreign Data Wrapper extension that allows similar functionality, albeit with support for multiple database engines.
This support should be seen as tactical with a strategic architecture to enable application-provided interfaces for integration within or across the bounded context of the services.
6. Validation State Freeze for Large Tables on DMS Console
While migrating large tables which have a validation phase configured post full load, the AWS seems to fail to update the validation status of the table even though the numbers indicate that all rows are transferred and validated.

As can be seen above, Full Load Rows and Total Rows match, validation is not pending and hasn’t either been suspended or failed, yet the validation state is “Pending Validation.”
If the DMS is used for Full Load only, then this issue can be ignored since, by this time, the DMS task has stopped. But if the CDC follows the full load, resuming the task will result in the validation starting again for this table since AWS DMS check the status field and decides to run the validation again before CDC can begin. If there are no writes to the source database, then it is okay for validation to happen again when CDC starts (just means more time to be spent on migration), albeit if the source DB begins to see writes and CDC begins to replicate additional writes, then the validation may fail due to mismatch of records. The best way to avoid this is to stop writing to source DB until all schema and tables have completed validation.
7. Controlling Migration Concurrency and Batching
DMS allows many options to optimize migration. Of course, choosing the right instance class for the DMS instance is a crucial choice (General Purpose: dms.tN.xxxx, Compute Optimized: dms.cN.Mxlarge , memory optimized : dms.rN.Mxlarge).
There are two crucial settings that enabled great performance benefits during our migration.
Use parallel table loads during full load to load the table concurrently. I tuned this concurrency depending on the number of schemas and tables in scope, the size of the tables, and the instance class chosen (dms.r6i.4xlarge).  During the full load, DMS created multiple memory buffers to store the source table data and cached changes. Loading data in parallel with a large enough instance increases the migration throughput and is a must for large migrations. Few points for consideration:
During the full load, DMS created multiple memory buffers to store the source table data and cached changes. Loading data in parallel with a large enough instance increases the migration throughput and is a must for large migrations. Few points for consideration:
- Increasing the parallelism beyond a point results in memory pressure and latency in the target load, so it needs to be optimized based on the database.
- The parallel load will load the data in unpredictable order, so any referential integrity cannot be guaranteed. All referential integrity constraints must be disabled.
Use batch optimized apply during CDC to address source load latency when the workload in the source database is high during CDC. We had kept the CDC phase for 7 days, and at peak, the source database resulted in high event traffic to DMS, and since, by default, DMS uses single-threaded replication to process CDC changes, this resulted in high target latency. By default, DMS applies every change to the target. In a batch apply mode, the DMS creates a time-ordered buffer of changes and commits the same in a single transaction to DB.  A few points for consideration:
A few points for consideration:
- The batch apply mode assumes that there is no need to keep referential integrity on target since the batch doesn’t transactionally isolate the writes to the source database.
- Should be used in cases where the source database is expected to be under load during migration, and the target database faced latency issues due to this. Otherwise, using a per-event commit to the target database is simpler.
8. Use DMS Rules and Filters to Make Migration Predictable
DMS task includes an option to map tables from one or more schemas for migration. Since the source endpoint has access to all the schemas in the Oracle instance, the use of a wild card to include all schemas is usually not a good idea.  To make the migration measurable and to track it meaningfully, the table mapping selection rules and the filters should define the precise scope of DMS migration in terms of the schemas and the tables within those schemas. Also, using a wildcard name for table selection within a schema makes DMS creates unnecessary system tables or oracle generated tables or temporary and redundant tables in AWS RDS PostgreSQL. If there is a clean table inventory within the Oracle schema, then maybe a table wildcard might be okay.
To make the migration measurable and to track it meaningfully, the table mapping selection rules and the filters should define the precise scope of DMS migration in terms of the schemas and the tables within those schemas. Also, using a wildcard name for table selection within a schema makes DMS creates unnecessary system tables or oracle generated tables or temporary and redundant tables in AWS RDS PostgreSQL. If there is a clean table inventory within the Oracle schema, then maybe a table wildcard might be okay.
Creating rules for multiple schemas and tables is a bit more work but provides rich dividends later.
- Prior to the migration, the pre-migration assessment reports are based on the precise table and schema mappings.
- The Table statistics during full and CDC shows organized table statistics for precise scope.
- The migration process itself is optimized for resource utilization for the precise scope of migration.
9. Automate With Schema Conversion Tool
The choice of target database involves a few considerations during migration or modernization. Cost, projected performance, and the nature of the data model are core considerations. As a result, the target database may be a different product, a different version, or even a different category, i.e., for example, the target database can be a different RDBMS OLTP or a no-SQL like DynamoDB, which results in a heterogenous data migrations. AWS DMS supports heterogeneous data migration. But the first problem to address is that of data model conversion, i.e., conversion of source schema to a compatible target schema for the scope of data migration.
Use of AWS Schema Conversion Tool that supports a diverse set of source and target databases and specifically supports the Oracle to PostgreSQL to enable automation of the schema conversion. We had tried to build the target database entities in PostgreSQL, but with complex entities, Stored Procedures, and unpredictable code usage of database queries (dynamic queries, ORMs, JDBC Proxy Beans), the use of Schema Conversion Tool solves much of the heavy lifting of adapting to target schema and analyze the application code changes needed to work with target. The latter is crucial for RDBMS to RDMS migration, where the application code may not be exposed to the underlying database directly and works on high-level framework-provided abstractions.
Schema Conversion Tool:
- Supports generation of target schema with indicators of unsupported objects or operations that need to be handled manually.
- Supports generation of target code in all supported languages and indicators where automatic conversion is not possible.
- Supports the generation of target code for stored procedures, functions, and triggers.
- The web version of the tool is also supported in the AWS DMS console.
Please note that the SCT is a pre-data migration activity. During data migration, the DMS service maintains its own data types to map for source and target data types. A premigration assessment to check on the compatibility of data types is available.
10. Critical Metrics to Track
During the full load and replication phases, the target database writes, and source database read throughput depends on the concurrent threads configured and the DMS instance type chosen in the DMS settings. Critical metrics to track are throughput, IOPS, and latency. While the usual metric related to CPU, memory and disk should be naturally tracked, some migration-specific metrics are there, ones we tracked:
METRICS |
SOURCE |
DETAILS (from AWD docs) |
NetworkTransmitThroughput |
DMS Instance |
The outgoing (Transmit) network traffic on the replication instance, including both customer database traffic and AWS DMS traffic used for monitoring and replication. |
NetworkReceiveThroughput |
DMS Instance |
The incoming (Receive) network traffic on the replication instance, including both customer database traffic and AWS DMS traffic used for monitoring and replication. |
CDCIncomingChanges |
Replication Task |
The total number of change events at a point-in-time that are waiting to be applied to the target. A large number for this metric usually indicates AWS DMS is unable to apply captured changes in a timely manner, thus causing high target latency. |
CDCLatencySource |
Replication Task |
CDCLatencySource represents the latency between source and replication instance. High CDCLatencySource means the process of capturing changes from source is delayed. |
CDCLatencyTarget |
Replication Task |
Target latency is the timestamp difference between the replication instance and the oldest event applied but unconfirmed by TRG endpoint (99%). When CDCLatencyTarget is high, it indicates the process of applying change events to the target is delayed. |
Write IOPS |
RDS PostgreSQL |
Write IOPS – should be tracked during the full load. High write IOPS with low CDCLatencyTarget means write are efficiently happening. |
11. DMS Migration Task — Validation and Pre-Migration Assessment
Before beginning the migration, running a pre-migration assessment that validates the rules of migration allows migration with more confidence.  If pre-migration assessments fail, then it allows addressing issues before migration so that the vent of migration itself is relatively smooth; especially useful to check the data type incompatibilities between Oracle to DMS and DMS to PostgreSQL.
If pre-migration assessments fail, then it allows addressing issues before migration so that the vent of migration itself is relatively smooth; especially useful to check the data type incompatibilities between Oracle to DMS and DMS to PostgreSQL.
In the task definition, turn on the ability for the SMS task to validate the data after it has been migrated. This ensures that the data integrity is maintained and that the data loss is assessed immediately after the full load.  The validation phase takes time since the comparison takes place between the source and target, but it is crucial to assert the quality of migration.
The validation phase takes time since the comparison takes place between the source and target, but it is crucial to assert the quality of migration.
12. Unavoidable Maintenance Windows
Usually, maintenance windows in cloud migrations are seen as an anti-pattern. But for data migrations between on-premises and AWS (which is also accompanied by application migration), the maintenance window allows the source and target databases to reach a steady state of migration, especially if there is a phase of CDC that is run for some time.
When a chronology of phases of migration is created, usually the writes can keep flowing to the source database all the time, but to allow the target database to reach equilibrium before the cutover, after which the AWS RDS PostgreSQL is the only authoritative write endpoint, a maintenance window is unavoidable and must be planned for.
Thank You!
Opinions expressed by DZone contributors are their own.
Comments