Using AWS Step Functions For Offloading Exponential Backoffs
This tutorial demonstrates how you can apply AWS Step Functions to offload exponential backoffs as well as the technical challenges that entails.
Join the DZone community and get the full member experience.
Join For FreeRetries are an essential part of distributed and cloud-native architectures. In a distributed, micro-services environment, it is common to see components (services) talking to each other to fulfill a user request.
Although retry mechanisms are essential, unfortunately, it is one of the less implemented features in the real-world implementations. There are several reasons for this.
First is the additional code the developer has to write, and the integration test cases testers should create. This driver can be mitigated easily by introducing related tasks at the Scrum planning phase. However, it is often overlooked and rushed at the very end of the sprint if it is ever considered at all.
The second reason is technical. Although we can do on-the-spot retries within the lifecycle of a single synchronous transaction, we should also cover exponential continuous long running retries. (These long term retries cannot be applied to synchronous user transactions as they will lead to a connection timeout issues at the client-side and bring negative user experience. For asynchronous processes, backend communication between services, and workflow-based use-cases, though, they have to be in place.)
You may also enjoy: How to Use Spring Retry
On-the-spot retries solve problems like network glitches, short JVM stop-the-world collections. Still, if the remote server is restarting, or having some severe issues like memory leaks, we cannot do on-the-spot retries, as it’s not feasible to hold the request thread open for long periods. Some serverless components like Lambda functions also have a maximum execution time limitation we need to consider.
As a consumer of the problematic service, the best strategy we can apply in these scenarios is exponential backoffs. In this strategy, we try once. If it fails, we wait for an X amount of configurable time, we try again, and if it is still down, we try after 2X, 3X amount of time, and so on.
Exponential backoff’s problem is you need to maintain a process/a thread for doing these retries. This new process may not be desirable for a microservice as it will bring additional complexity and hardware requirements to the micro-service on hand. In a microservices environment, we are not bound to specific languages. The capabilities of the selected language can also be a road blocker to maintain additional threads etc.
Because of these technical challenges, it is always a good idea to offload retries to another system for backend and asynchronous service-to-service communications. One of the ways of offloading is using a queue.
In one of my previous articles, Asynchronous Retries With SQS, I explained how a queue (specifically AWS SQS, but it applies to other queues as well) can be used to offload retries. Container-based environments can make use of service meshes and offload the non-functional communication requirements to their sidecars.
In this article, I will be offloading the exponential backoff retries to a serverless workflow engine: AWS Step Functions.
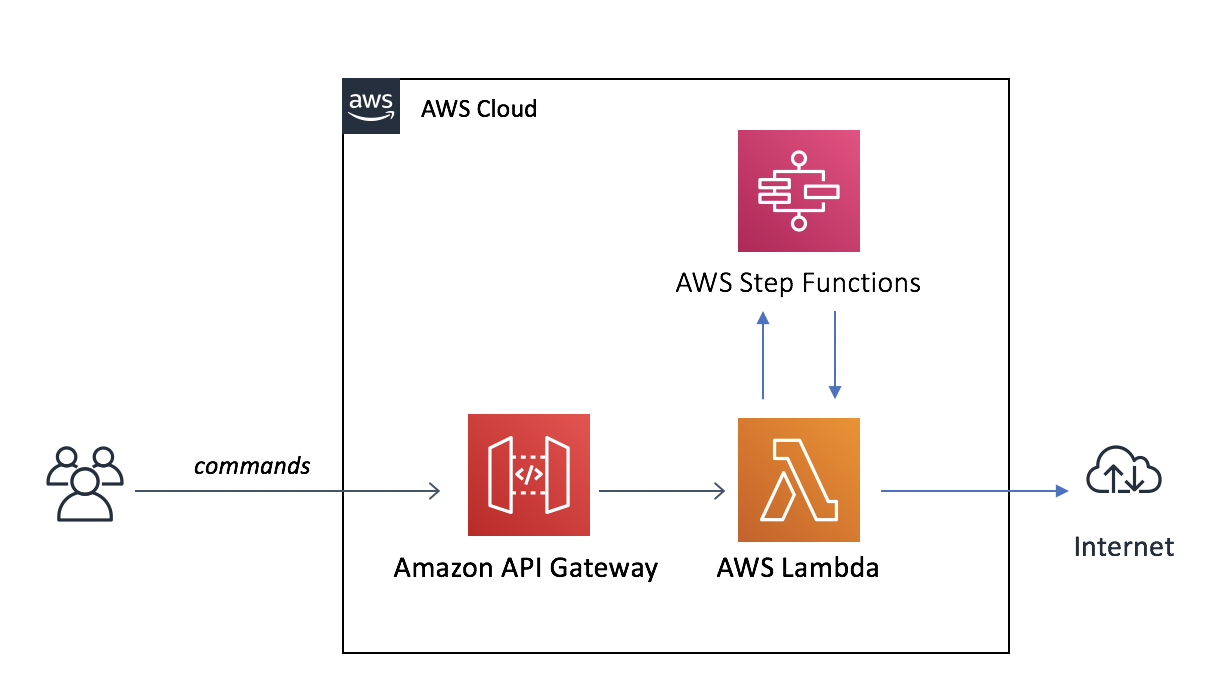
Before explaining more about the AWS Step Functions, let's consider a sample serverless architecture. In this architecture, we receive a command from a user from a REST API exposed from Amazon API Gateway and backed by an AWS Lambda function. This is an asynchronous command for the user, so the user is not waiting for an immediate response. An example could be a captured order that is sent for fulfillment. The lambda function then passes this command to a backend process or service. (In the serverless world, everything can go wrong, including services, so we need to design for failure for every component). In our sample architecture, the backend process is an external SaaS application's web service, living on the Internet. Because it is living on the Internet, it is not reliable all the time, which makes it a perfect candidate for retries. If the AWS Lambda fails to call the external service, it takes the original request payload (context) and triggers a retry AWS Step Functions workflow with it. The workflow re-uses the very same lambda function in it; the business logic is not duplicated. This time though, the AWS Lambda execution is scheduled by the workflow engine.

AWS Step Functions workflows are composed of one or more states. If you want to do a particular work, set the state's type to Task. Each Task can do work mostly an integration against another service or an AWS Lambda function. When the workflow orchestrator attempts to schedule and run a Task and the Task fails, you have an option to ask the orchestrator to retry it a specified number of times, while backing off between the attempts. A sample Task that is calling Lambda Function is below.
xxxxxxxxxx
"ExternalWebhookState": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:...:function:ExternalServiceLambda",
"Retry": [ {
"ErrorEquals": ["MyCustomError"],
"IntervalSeconds": 1,
"MaxAttempts": 10,
"BackoffRate": 2.0
} ],
"End": true
}
Here, it is saying that it needs to try a maximum ten times, first retry after 1 second with a backoff rate of 2X. That means the first re-try will be executed after 1 second, the second 2 seconds later than that, the third 4 seconds, and so on. As long as the underlying Lambda returns a functional error to Step Functions (Lambda function should throw MyCustomError in the above example), this loop will continue.
If, after ten retries, the remote party does not respond, AWS Step Functions will mark the Task and the workflow execution as unsuccessful. At this moment, we can log it or take action by listening to a CloudWatch Event rule against Step Function Execution Status Changed events. This rule can point to another lambda function for actions like opening trouble tickets or sending a notification to the operations teams via SNS. Please note that every state change and retry is costing you. Therefore we need to put some thought on the maximum retries we want from the service. On the other hand, serverless is cheap, and retries will rarely happen in a healthy operation.
For more information about asynchronous communication mechanisms, please take a look at my other article here.
Further Reading
Understanding Retry Pattern With Exponential Back-off and Circuit Breaker Pattern
Asynchronous Retries With AWS SQS
Opinions expressed by DZone contributors are their own.
Comments