Using Redis to Deal With Inter-Service Communications
Learn how to deal with one of the biggest microservices pain points, inter-service communication, using Redis.
Join the DZone community and get the full member experience.
Join For FreeMicroservices are great, until they're not.
I feel like that should be stated in all textbooks and blog posts and Twitter comments you read about this architectural pattern, because there is not enough time in your life to read about how great microservices are, how awesome and flexible they've made your platform, but somehow, for some strange reason, people forget to mention how damn difficult it is to handle a real-world microservices architecture when it's grown to a point where orchestrating them stops being a trivial task.
In this post, I'm going to cover one specific pain point I've had to deal with in the past: inter-service communication.
So, What's the Problem?
Your classic microservice-based architecture probably looks like the image below: a few services, some of them yours, others made by a third-party (like your database, your external API, and what-not) and they all talk to each other like there is nothing wrong with that.
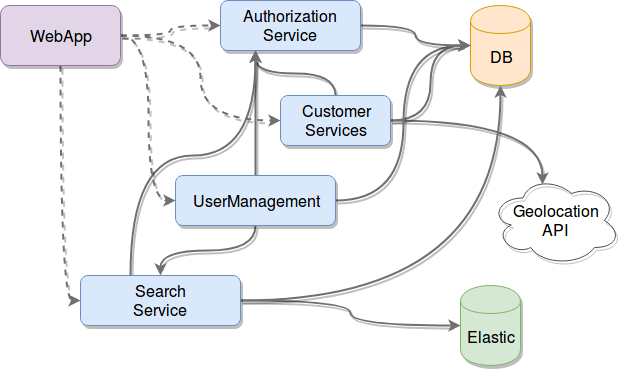
That's all nice and pretty, until, of course, real life hits and you're in production, where your fancy architecture should not be crashing because of the increasing amount of traffic you're getting. Or where you should not be losing data due to a crashed service, but did you remember to add retry logic to your comms layer? What happens if there is nothing to send your messages to?
These are all real-life scenarios that architects and developers tend to forget about, especially when they're not that used to getting their stuff out into the wild (also known as Production Land). Let me expand a bit further on these points.
More Traffic Doesn't Always Mean More Money
...sometimes, it just means more headaches. If your application is handling web traffic (something that is very common these days), the first easy fix to handle this is to "scale" your services and add a load balancer in front of them.
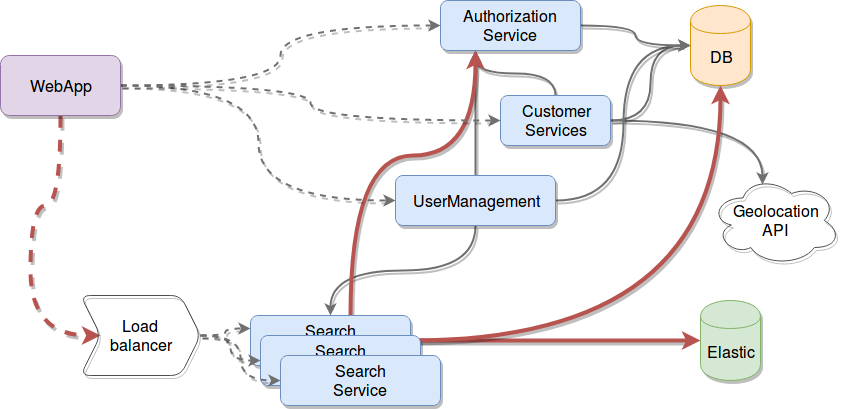
As the image shows, this is fine in principle, but you suddenly moved your bottleneck away from your service into the others it is contacting. In the example above, your SearchService is now fine, but your Authorization service is now going to be hit 3 times harder (I'm leaving out the database and Elastic because I'm assuming those third-party services you're using actually thought about this and are ready for it).
Handling Crashed Services
I'm not talking about how to restart your crashed service, because that's a topic for another time. I'm talking about the perspective of the consumers of that service. What happens if your Authentication service dies?
Let's look at an even simpler example: what if you had something like the image below, where your MainAPI redirects incoming traffic into the Processing Service, which does some data mangling and turns it into the Storage Service, which handles saving that data into a SQL database.
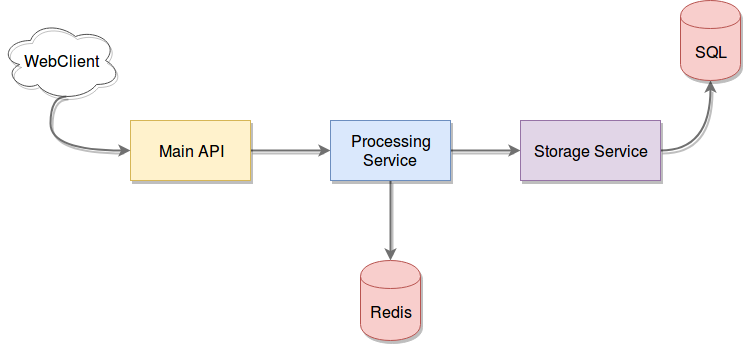
What if suddenly your Processing Service dies, no matter the reason it's dead, what happens to your Main API? Does it handle the incoming requests? Is it crashing again? Be honest here, how many times did you just add a log line to your else clause when writing the connection code to the database? Yeah, I thought so. I don't even want to know what the code handling inter-service communication looks like.
The Main API needs to know how to handle cases when there is nothing to send that data to. You could say you need a buffer.
Redis to the Rescue!
These are two (or three, depending on how you counted them) of the most common problems I've run into in the past when dealing with these types of architectures. Here is how I've used Redis to solve them.
Avoid Service-to-Service Communication When Possible
If you can, I would strongly suggest you turn some of your services into message consumers instead. That way, you remove the problem of overflowing them with requests by letting them decide how many messages they can process at any given time.
To do this, you push a message queue between your services and essentially switch into a pub/sub approach. You still keep the microservices' benefits:
- Small, very focused processes that run independently from each other and are easy to maintain,
- Easy communication with each other,
- Simple horizontal scaling,
- Ability to work and change individual services without affecting the rest of the platform,
- And the list goes on and on.
But, you also gain a buffer between your most sensible processes. In practice, this means you've solved the overloading problem you had before, because now, whenever your client-facing services get overrun by requests, they are thrown into a bucket and processed at the pace your consumers can handle, instead of doing it the other way around.
How Does Redis Help Here?
Simple: Redis provides two ways of doing a buffer type of approach. You can directly use its pub/sub capabilities. Essentially, you publish your messages to the queue and your consumers get notified. Now, this is great if you can afford to lose messages, since Redis' pub/sub won't care if there are no consumers listening.
On the other hand, if you need something you can rely on, then you can use a reliable queue pattern, which uses a List in Redis and, by activating keyspace notifications, you can notify your consumers automatically. This pattern requires a bit of extra work on the side of the consumers (like locking the queue to avoid concurrency issues), but they're easily handled.
The example from above now looks like this:
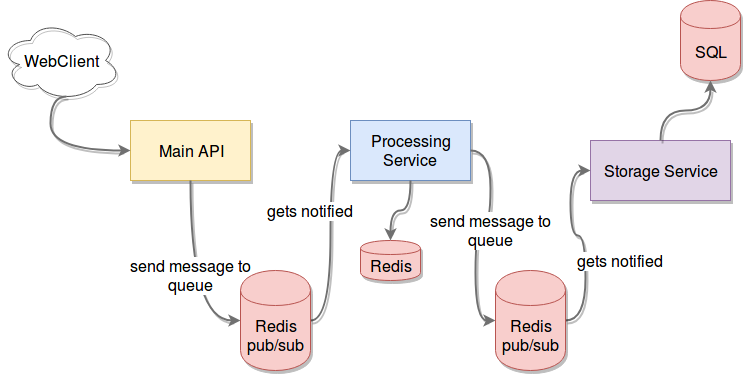
Your consumer processes will still be notified whenever new messages arrive in the queue, but they can decide to work on it or ignore it. If you happen to have multiple workers, they can decide who works on it by using an atomic lock on Redis (simply setting a key if it doesn't already exist in Redis as an atomic function, so you can be sure whichever process does it first, will not conflict with any other). If none can work on it at the moment, they can get back to polling the message from the list once they're done, so it becomes a more secure way of creating a buffer.
Here is a pseudo-code example:
subscribeToQueue('new-data')
onNewMessage('new-data', function(newMsg) {
result = SETNX(newMsg.id+"_processed", 1);
if(result) {
//start processing the data
} else {
//ignore this one, someone else is working on it
}
})It's not exactly JS, but you get the point. SETNX stands for SET if Not eXists, which is what you want.
The other key aspect of the code from above is the choice of the key's name. Notice how I created a unique key using the message ID attribute and the string "_processed." This is a common practice when using Redis for something other than adding a simple key-value pair. People tend to forget the power of a well-defined key name and miss a lot of opportunities.
Let Others Know When You're Not Around
How can you tell your processes when one of them fails so they can act accordingly? When you have to deal with inter-communicated services and you can't go with the above solution (avoiding direct service-to-service comms), you might at least be interested in telling your services how to realize one of them died.
This way, your services can decide to buffer their communication data until the receiving end comes back online, or just redirect their output to some other place. This is definitely a better approach than just trying to reach something that's no longer there and failing because of it.
How Does Redis Help Here?
Building on the keyspace notification feature (which, if you know me, you probably know I love), you can have your services updating a service-specific key with a pre-defined TTL. You could say that whatever service does not provide a status update about their health for more than 5 minutes is considered dead. You could get your services to update a with a 5 minute TTL every time they can (or once every 4 minutes, or something like that).
If you make sure that inter-communicated services subscribe to the corresponding "heartbeat keys" of their "chatting partners," they'll be immediately notified when something happens to one of the services they interact with.
That "heartbeat key" could simply be a 1, stating they're alive, or it could be a full hashmap with status information; that's up to you and your needs.
Well, that's it for today! I hope these two "tricks" for using Redis to solve inter-service communication will be helpful to you. If they are (or even if they aren't), please let me know in the comments!
As always, if you want more content like this or are looking for Node.js related books, please visit my site at www.fernandodoglio.com.
Opinions expressed by DZone contributors are their own.
Comments