What Is SQL Vector Database?
SQL vector databases blend the strengths of SQL and vector databases, providing a streamlined approach to storing and querying high-dimensional vectors through SQL.
Join the DZone community and get the full member experience.
Join For FreeLarge Language Models (LLMs) have made many tasks easier, like making chatbots, language translation, text summarization, and many more. In the past, we used to write models for different tasks, and then there was always the issue of their performance. Now, we can do most of the tasks easily with the help of LLMs. However, LLMs do have some limitations when they are applied to real-world use cases. They lack specific or up-to-date information leading to a phenomenon called hallucination (opens new windwhere the model generates incorrect or un-predictable results.
Vector databases (opens new window)proved to be very helpful in mitigating the hallucination issue in LLMs by providing a database of domain-specific data that the models can reference. This reduces the instances of inaccurate or nonsensical responses.
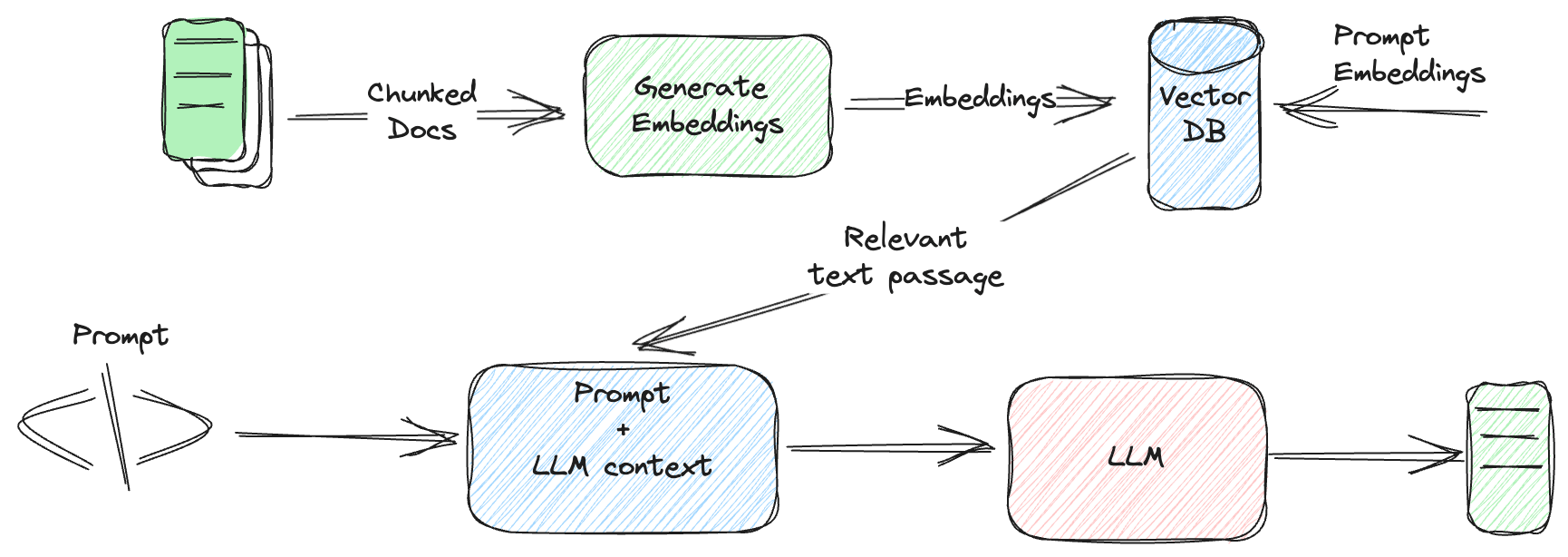
In this article, we are going to see how the integration of vector databases with SQL has made life easier for businesses. We will discuss some of the limitations of traditional databases and what led to this new integration, SQL vector database. In the end, we will see how these databases work.
What Is SQL Vector Databases?
An SQL vector database is a specialized type of database that combines the capabilities of traditional SQL databases with the abilities of a vector database. Providing you the ability to efficiently store and query high-dimensional vectors with the help of SQL.
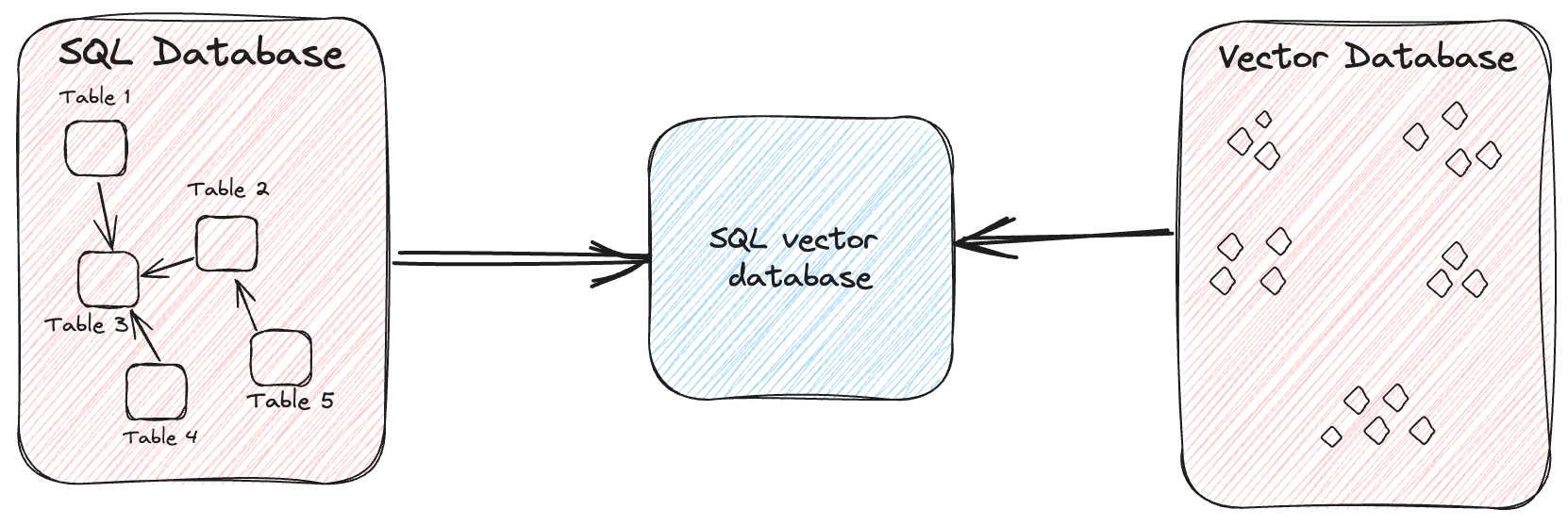
In simple terms, it's like a regular database that you can use to store both structured data and unstructured data, but with an added capability to perform rapid queries across various data types, including images, video, audio, and text. The mechanism behind this efficiency lies in the creation of vectors for the data, facilitating the swift identification of similar entries.
Now, let's try to understand the core concepts of SQL vector databases that would help to get the reason why we need SQL vector databases.
Key Concepts in SQL Vector Databases
SQL vector databases introduced some innovative concepts that significantly enhance data retrieval and analysis, especially in the context of unstructured and high-dimensional data. Let’s explore a few of them:
- Handling the unstructured data: Vector representations of data give you the ability to perform ANN search on unstructured data. When you find the embeddings of unstructured data like text, images, or audio. You capture semantic meaning, which allows you to perform similarity comparisons by measuring the distance between vectors to find nearest neighbors, regardless of the original data format.
- ANN search: SQL vector databases store data as vectors and perform a type of search known as similarity search, which doesn't operate against a single row but rather conducts an Approximate Nearest Neighbor (ANN) search. This process involves identifying the vectors that are closest to a given query vector, meaning those whose properties most closely align with the properties of the query vector.
- Vector indexing: Vector indexing refers to specialized data structures and algorithms used to efficiently organize and query large amount of vector data. Vector databases use various vector indexing strategies to optimize data retrieval and management. Some vector database uses hierarchical graph algorithm to accelerate search performance. Some vendors may develop their own indexing algorithm; for example, MyScale has developed a novel technique called Multi-Scale Tree Graph (MSTG), which significantly outperforms existing approaches (opens new window).
Note: The goal of the vector indexing is to optimize search speed and accuracy when performing operations like similarity search for approximate nearest neighbors across high-dimensional vectors.
Why We Need SQL Vector Databases
So, here comes a question into mind: Why do we need SQL vector databases? Traditional databases like MySQL, PostgreSQL, and Oracle have been working well for ages and have all the necessary features to keep the data organized. They have quick indexing methods, make sure you get the exact data you need without any trouble. Why do we need a SQL vector database?
No doubt, traditional databases are great, but they do have some limitations when the data becomes huge and unstructured. Let's take a look:
- Lack of speed and semantic understanding: Traditional databases rely on exact keyword matching and indexing to retrieve data. But with the exponential growth of unstructured data from social media, sensors, etc., traditional databases don’t understand the semantics of the data. There is a need of databases that can not only fetch data rapidly but also understand the context and semantics of queries. For example, when dealing with natural language queries or complex data relationships, traditional methods struggle to provide quick and relevant results.
- Issues with high-dimensional data: Relational databases store data in the form of rows and columns. As the number of columns or dimensions increases, the query performance decreases and led to a phenomena called the “curse of dimensionality”. So, we need a database that can eradicate the issue of dimensionality without losing the query performance.
- Unstructured data: Relational databases require structured data to be transformed and flattened into rows and columns in tables. But an increasing amount of valuable data today is unstructured - images, video, audio, text documents, etc. which is very difficult to store in the relational databases.
- Scalability concerns: Scalability is challenging for traditional databases, especially when you're dealing with massive volumes of data. This becomes an issue for organizations dealing with large datasets, creating issues for them to process and analyze data effectively. So, we need a database that can handle large amounts of data while maintaining the same speed and efficiency.
To address these challenges, the development of SQL vector databases emerged, presenting a superior alternative to traditional databases.
How SQL Vector Databases Outperform Traditional Databases
Combining SQL with Vectors brings a lot of benefits, among which several advantages stand out for their significant impact:
- Faster performance and semantic search: The vector representation allows the database to extract the semantic meanings from the stored data. Also, the process becomes even faster because we find the vector similarity here. This is helpful for many applications like recommendation systems where the semantic relationship between the data is more important.
- Efficient data retrieval: SQL vector databases use the Approximate Nearest Neighbor(ANN) technique to find the matching records. By calculating the cosine similarity between your query and the dataset, it efficiently gives the most relevant top 'K' results.
- Support for both structured and unstructured data: The introduction of SQL in the vector database gives the ability to represent the unstructured data in vectors and store the semantic meanings. This way, you can easily query any structure or unstructured data.
- Familiar SQL interface: One of the biggest advantages of SQL vector databases is that they provide a familiar SQL interface for querying data. It allows you to use your SQL skills and minimize the learning curve when adopting vector capabilities. Queries can be written using standard SQL syntax.
How SQL Vector Databases Work
The integration of SQL and vector databases involves storing and indexing high-dimensional vectors in a way that can be efficiently queried using SQL. This process involves certain steps.
Note: In this project, we employ MyScale, a SQL-based vector database, for the initial implementation. However, different SQL vector databases may work in different ways.
Step 1: Setting Up the Database
Firstly, you need to set up a database that supports both SQL and vector operations. Some modern databases have built-in support for vectors, while others can be extended with custom data types and functions.
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100),
description TEXT,
vector Array(Float32),
CONSTRAINT check_length CHECK length(vector) = 1536,
);In this example, we create a products table with a 1536D vector column that stores the high-dimensional vectors.
Step 2: Inserting Data
When inserting data, you would store both the structured attributes and the vector representations of the unstructured data.
INSERT INTO products (id, name, description, vector)
VALUES (1, 'Smartphone', 'A high-end smartphone with a great camera.', ARRAY[0.13, 0.67, 0.29, ...]);In this SQL statement, we insert a new product record along with its vector.
Note: To get the vector representation of the unstructured data, you can use models like GPT-4, and BERT.
Step 3: Indexing Vectors
The next step is to create vector indexes. It's the technique that defines how fast the database applies the similarity search. Many vector databases use specialized indexing techniques such as KD-trees, R-trees, or inverted index structures to optimize these operations.
ALTER TABLE products ADD VECTOR INDEX idx vector TYPE MSTGHere, we create a MSTG index, which is suitable for indexing multidimensional data.
Note: The MSTG algorithm is created by MyScale team, which has surpassed all the mainstream vector search indexes (in terms of performance and cost-efficiency) used by many vector databases(opens new window).
Step 4: Querying Data
To query the data, you just combine traditional SQL queries with vector operations. For instance, if you want to find products similar to a query vector, you can use the vector distance function.
SELECT name, description, distance(vector, query_vector) as dist
FROM products
ORDER BY dist LIMIT 5;This query finds the distance between the vector representations of the vector column and the query_vector . Then, it orders the results in ascending order with respect to distance.
Published at DZone with permission of Usama Jamil. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments