What Should You Know About Graph Database’s Scalability?
Graph database scalability how-to, designing a distributed database system, graph database query optimization.
Join the DZone community and get the full member experience.
Join For FreeHaving a distributed and scalable graph database system is highly sought after in many enterprise scenarios. This, on the one hand, is heavily influenced by the sustained rising and popularity of big-data processing frameworks, including but not limited to Hadoop, Spark, and NoSQL databases; on the other hand, as more and more data are to be analyzed in a correlated and multi-dimensional fashion, it's getting difficult to pack all data into one graph on one instance, having a truly distributed and horizontally scalable graph database is a must-have.
Do Not Be Misled
Designing and implementing a scalable graph database system has never been a trivial task. There is a countless number of enterprises, particularly Internet giants, that have explored ways to make graph data processing scalable. Nevertheless, most solutions are either limited to their private and narrow use cases or offer scalability in a vertical fashion with hardware acceleration which only proves, again, that the reason why mainframe architecture computer was deterministically replaced by PC-architecture computer in the 90s was mainly that vertical scalability is generally considered inferior and less-capable-n-scalable than horizontal scalability, period. It has been a norm to perceive that distributed databases use the method of adding cheap PC(s) to achieve scalability (storage and computing) and attempt to store data once and for all on demand. However, doing the same cannot achieve equivalent scalability without massively sacrificing query performance on graph systems.
Why scalability in a graph (database) system is so difficult (to get)? The primary reason is that graph system is high-dimensional; this is in deep contrast to traditional SQL or NoSQL systems, which are predominantly table-centric, essentially columnar and row stores (and KV stores in a more simplistic way) and have been proved to be relatively easy to implement with a horizontally scalable design.
A seemingly simple and intuitive graph query may lead to deep traversal and penetration of a large amount of graph data, which tends to otherwise cause a typical BSP (Bulky Synchronous Processing) system to exchange heavily amongst its many distributed instances, therefore causing significant (and unbearable) latencies.
On the other hand, most existing graph systems prefer to sacrifice performance (computation) while offering scalability (storage). This would render such systems impractical and useless in handling many real-world business scenarios. A more accurate way to describe such systems is that they probably can store a large amount of data (across many instances) but cannot offer adequate graph-computing power — to put it another way, these systems fail to return with results when being queried beyond meta-data (nodes and edges).
This article aims to demystify the scalability challenge(s) of graph databases, meanwhile putting a lot of focus on performance issues. Simply put, you will have a better and unobstructed understanding of scalability and performance in any graph database system and gain more confidence in choosing your future graph system.
There is quite a bit of noise in the market about graph database scalability; some vendors claim they have unlimited scalability, while others claim to be the first enterprise-grade scalable graph databases. Who should you believe or follow? The only way out is to equip yourself with adequate knowledge about scalability in graph database systems so that you can validate it by yourself and don't have to be misled by all those marketing hypes.
Admittedly, there are many terms for graph database scalability; some can be dearly confusing, to name a few: HA, RAFT or Distributed Consensus, HTAP, Federation, Fabric, Sharding, Partitioning, etc.
Can you really tell the difference, sometimes minute and often with overlapping features, of all these terms? We'll unravel them all.
3 Schools of Distributed Graph System Architecture Designs
First, make sure you understand the evolution pathway from a standalone (graph database) instance to a fully distributed and horizontally scalable cluster of graph database instances.
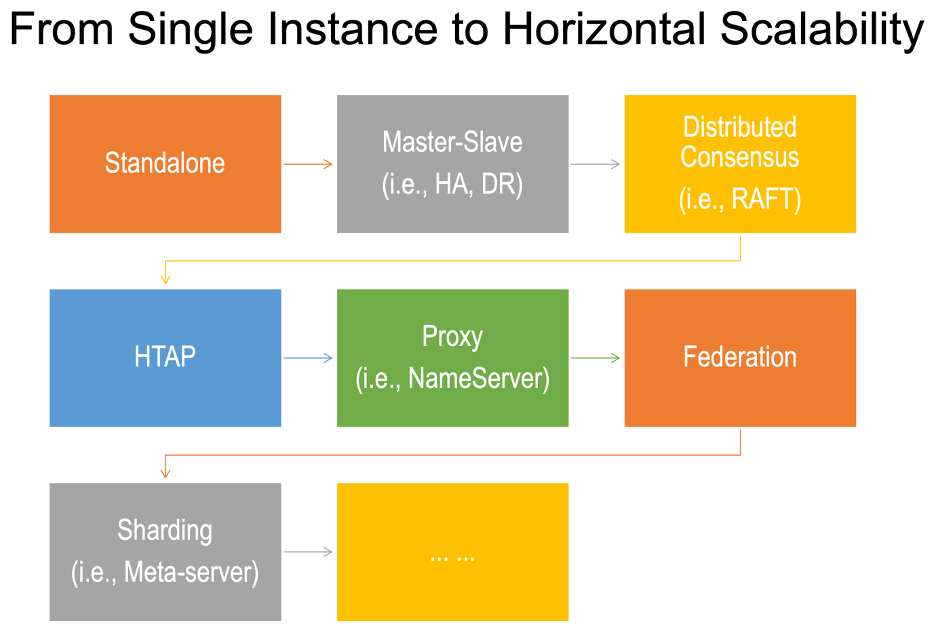
A distributed system may take many forms, and this rich diversification may lead to confusion. Some vendors misleadingly (and ironically) claim their database systems to be distributed evenly on a single piece of underpinning hardware instance, while other vendors claim their sharded graph database cluster can handle zillion-scale graph datasets while, in reality, the cluster can't even handle a typical multi-hop graph query or graph algorithm that reiteratively traverse the entire dataset.
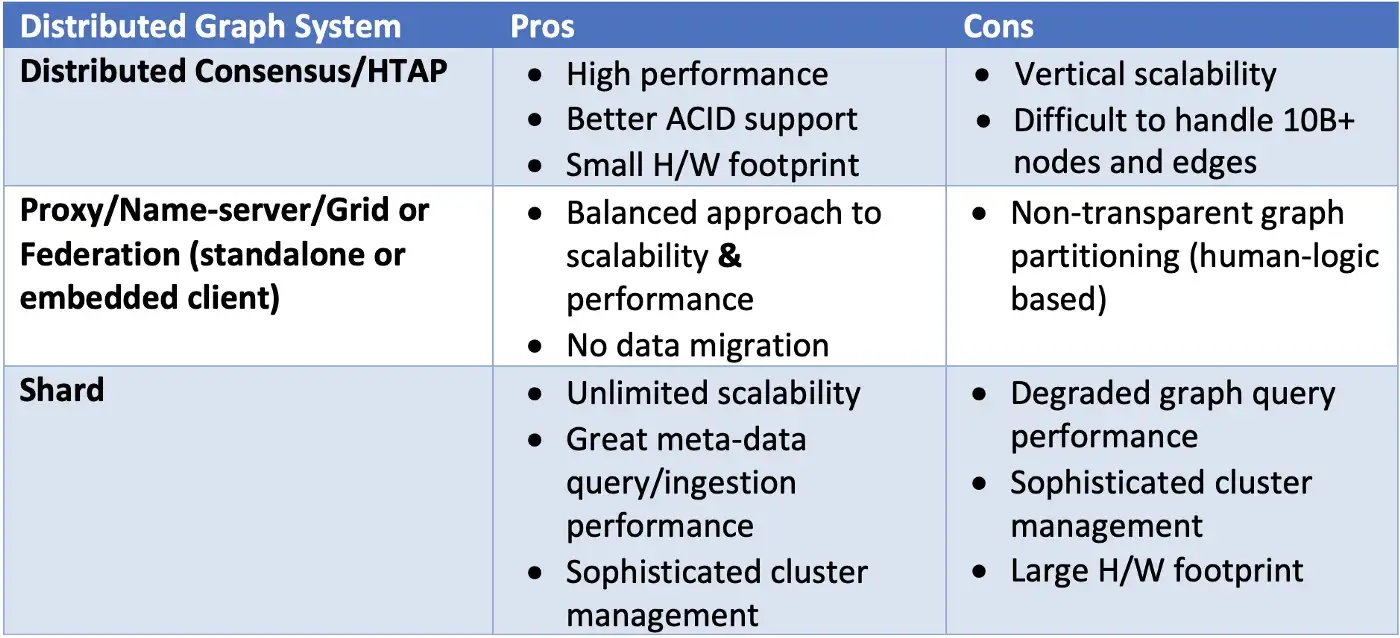
Simply put, there are ONLY three schools of scalable graph database architecture designs, as captured in the table:
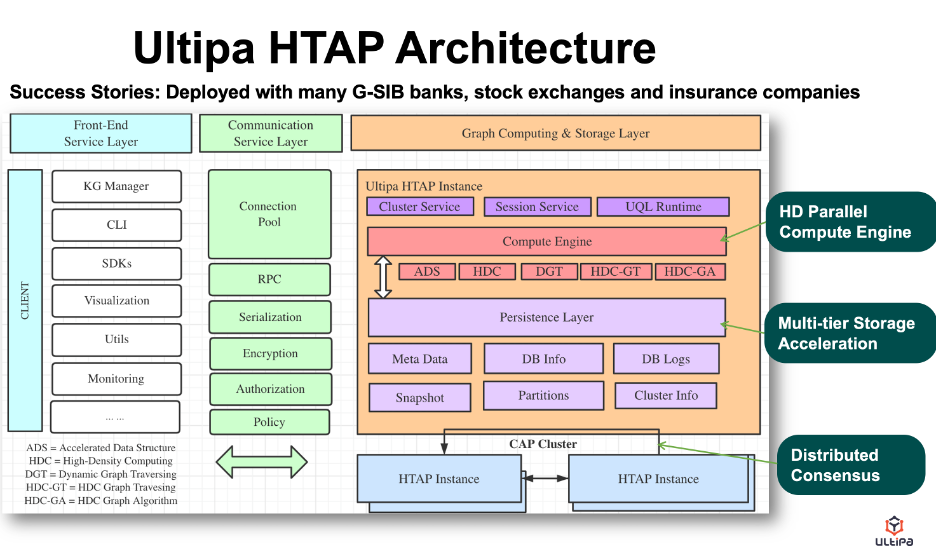
HTAP Architecture
The first school is considered a natural extension to the master-slave model, and we are calling it distributed consensus cluster where typically three instances form a graph database cluster. The only reason to have three or an odd number of instances in the same cluster is that it's easier to vote for a leader of the cluster.
As you can see, this model of cluster design may have many variations; for instance, Neo4j's Enterprise Edition v4.x supports the original RAFT protocol, and only one instance handles workload, while the other two instances passively synchronize data from the primary instance — this, of course, is a naïve way of putting RAFT protocol to work. A more practical way to handle workload is to augment the RAFT protocol to allow all instances to work in a load-balanced way. For instance, having the leader instance handle read-and-write operations, while the other instances can at least handle read type of queries to ensure data consistencies across the entire cluster.
A more sophisticated way in this type of distributed graph system design is to allow for HTAP (Hybrid Transactional and Analytical Processing), meaning there will be varied roles assigned amongst the cluster instances; the leader will handle TP operations, while the followers will handle AP operations, which can be further broken down into roles for graph algorithms, etc.
The pros and cons of graph system leveraging distributed consensus include:
- Small hardware footprint (cheaper).
- Great data consistency (easier to implement).
- Best performance on sophisticated and deep queries.
- Limited scalability (relying on vertical scalability).
- Difficult to handle a single graph that's over ten billion-plus nodes and edges.
What's illustrated below is a novel HTAP architecture from Ultipa with key features like:
- High-Density Parallel Graph Computing.
- Multi-Layer Storage Acceleration (Storage is in close proximity to compute).
- Dynamic Pruning (Expedited graph traversal via dynamic trimming mechanism).
- Super-Linear Performance (i.e., when computing resource such as the number of CPU cores is doubled, the performance gain can be more than doubled).
Note that such HTAP architecture works wonderfully on graph data size that's below 10B nodes + edges. Because lots of computing acceleration are done via in-memory computing, and if every billion nodes and edges consume about 100GB of DRAM, it may take 1TB of DRAM on a single instance to handle a graph of ten billion nodes and edges.
The upside of such design is that the architecture is satisfactory for most real-world scenarios. Even for G-SIBs (Globally Systemically Important Banks), a typical fraud detection, asset-liability management, or liquidity risk management use case would consume around one billion data; a reasonably sized virtual machine or PC server can decently accommodate such data scale and be very productive with an HTAP setup.
The downside of such a design is the lack of horizontal (and unlimited) scalability. And this challenge is addressed in the second and third schools of distributed graph system designs (see Table 1).
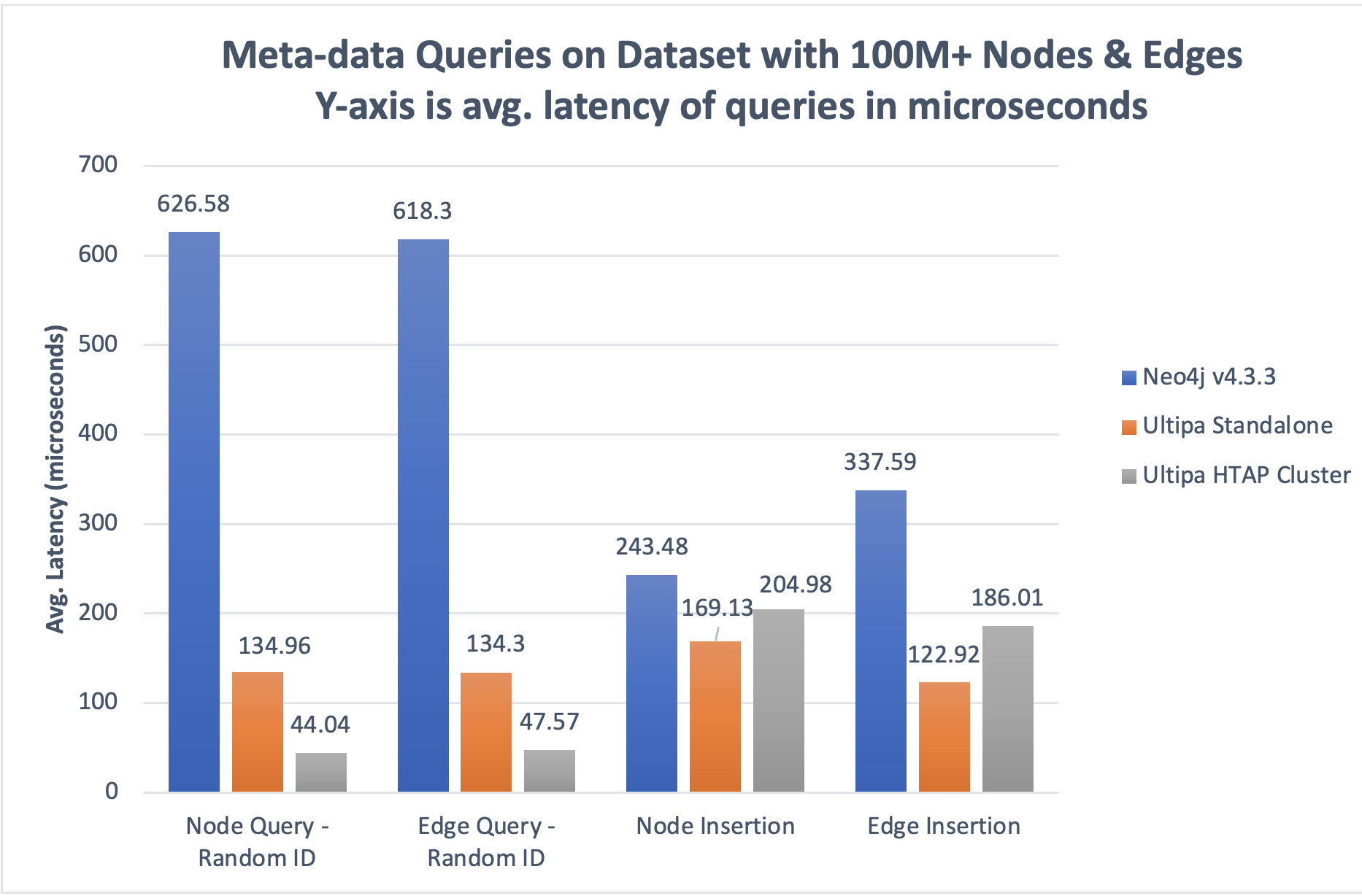
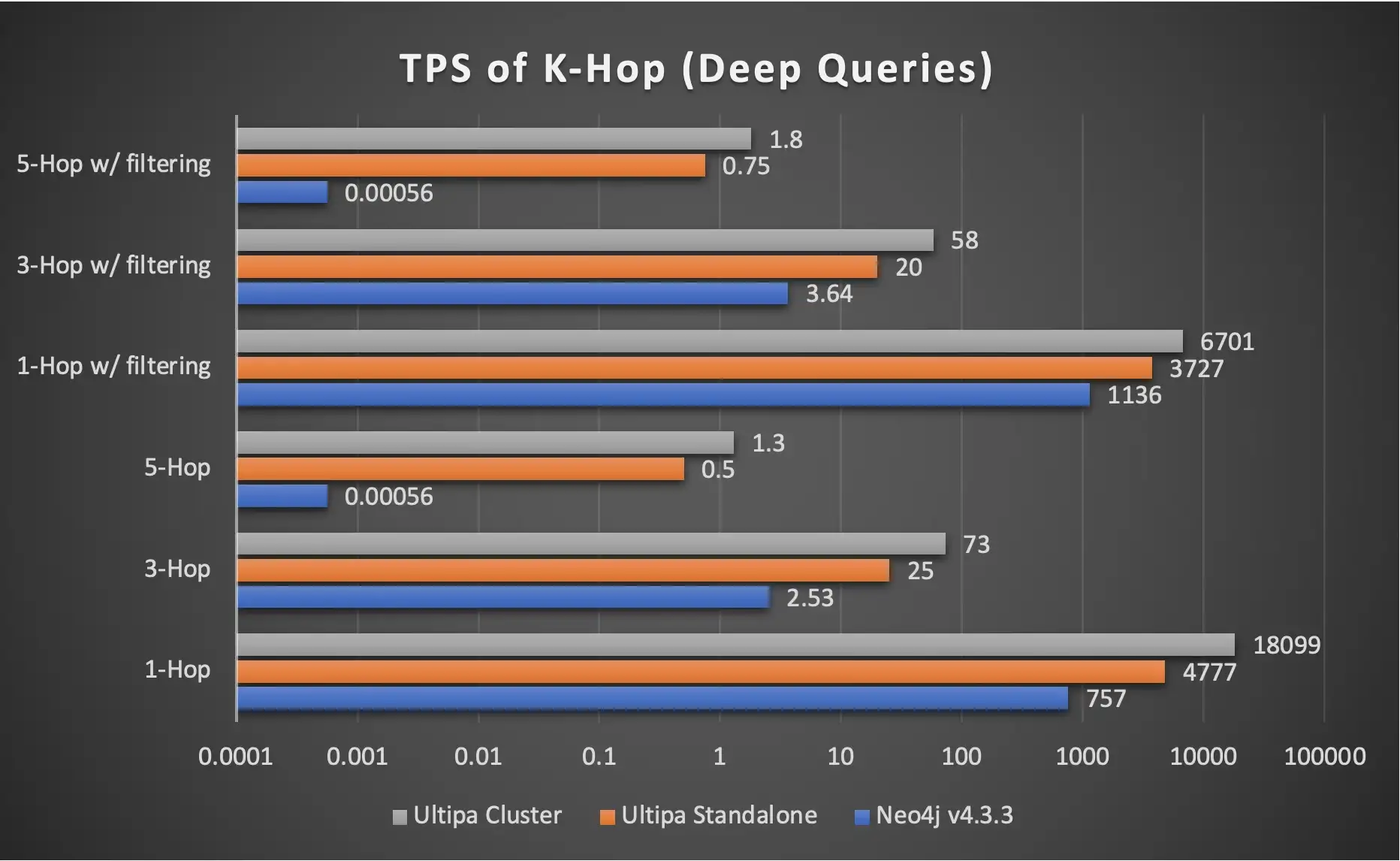
The two graphs below show the performance advantages of HTAP architecture. There are two points to watch out for:
- Linear Performance Gain: A 3-instance Ultipa HTAP cluster's throughput can reach ~300% of a standalone instance. The gain is reflected primarily in AP type of operations such as meta-data queries, path/k-hop queries, and graph algorithms, but not in TP operations such as insertions or deletions of meta-data because these operations are done primarily on the main instance before synchronized with secondary instances.
- Better performance = Lower Latency and Higher Throughput (TPS or QPS).
Grid Architecture
In the second school, there are also quite a few naming variations for such types of distributed and scalable graph system designs (some are misleading). To name a few: Proxy, Name server, MapReduce, Grid, or Federation. Ignore the naming differences; the key difference between the secondary school and the first school lies with the name server(s) functioning as a proxy between the client side and server side.
When functioning as a proxy server, the name server is only for routing queries and forwarding data. On top of this, except for the running graph algorithm, the name server has the capacity to aggregate data from the underpinning instances. Furthermore, in federation mode, queries can be run against multiple underpinning instances (query-federation); for graph algorithms, however, the federation's performance is poor (due to data migration, just like how map-reduce works). Note that the second school is different from the third school in one area: data is functionally partitioned but not sharded in this school of design.
For graph datasets, functional partitioning is the logical division of graph data, such as per time series (horizontal partitioning) or per business logic (vertical partitioning).
Sharding, on the other hand, aims to be automated, business logic or time series ignorant. Sharding normally considers the location of network storage-based partitioning of data; it uses various redundant data and special data distribution to improve performance, such as making cuttings against nodes and edges on the one hand and replicating some of the cut data for better access performance on the other hand. In fact, sharding is very complex and difficult to understand. Automated sharding, by definition, is designed to treat unpredictable data distribution with minimal-to-zero human intervention and business-logic ignorant, but this ignorance can be very problematic when facing business challenges entangled with specific data distribution.
Let's use concrete examples to illustrate this. Assuming you have 12 months' worth of credit card transaction data. In artificial partition mode, you naturally divide the network of data into 12 graph sets, one graph set with one-month transactions on each cluster of three instances, and this logic is predefined by the database admin. It emphasizes dividing the data via the metadata of the database and ignoring the connectivity between the different graph sets. It's business-friendly, it won't slow down data migration, and has good query performance. On the other hand, in auto-sharding mode, it's up to the graph system to determine how to divide (cut) the dataset, and the sharding logic is transparent to the database admin. But it's hard for developers to immediately figure out where the data is stored, therefore leading to potential slow data migration problems.
It would be imprudent to claim that auto-sharding is more intelligent than functional partitioning simply because auto-sharding involves less human intervention.
Do you feel something is wrong here? It's exactly what we are experiencing with the ongoing rising of artificial intelligence, we are allowing machines to make decisions on our behalf, and it's not always intelligent! (In a separate essay, we will cover the topic of the global transition from artificial intelligence to augmented intelligence and why graph technology is strategically positioned to empower this transition.)
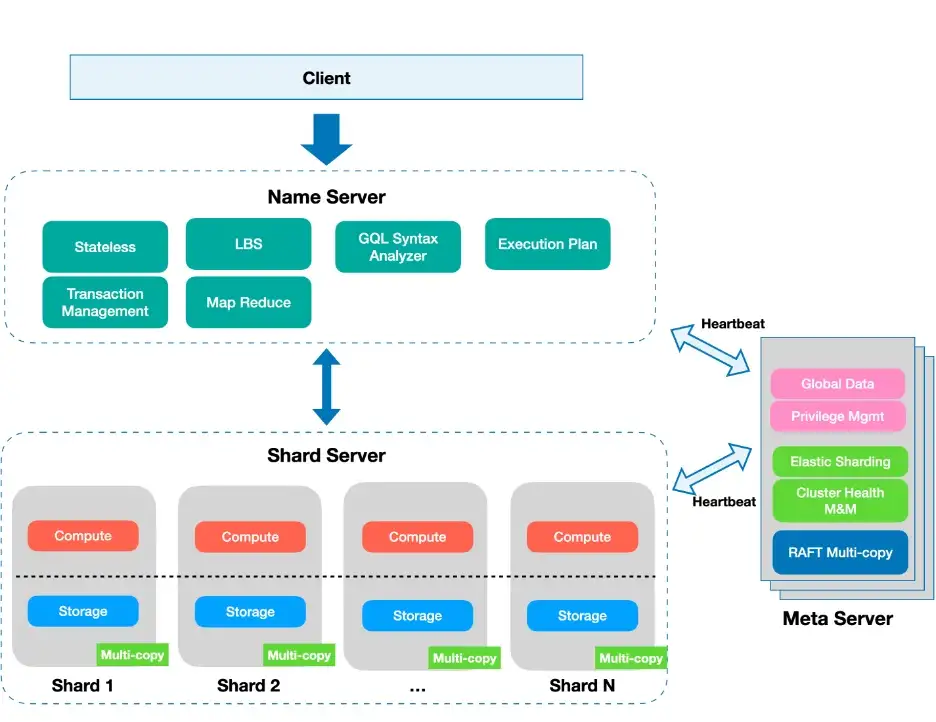
In Graph-5, a grid architecture pertaining to the second school of design is illustrated; the two extra components added on top of Graph-2's HTAP architecture are name server(s) and meta server(s). Essentially all queries are proxied through the name-server, and the name-sever works jointly with the meta-server to ensure the elasticity of the grid; the server cluster instances are largely the same as the original HTAP instance (as illustrated in Graph 2).

Referring to Table 1, the pros and cons of the grid architecture design can be summarized as follows:
- All the pros/benefits of a typical HTAP architecture are retained.
- Scalability is achieved with performance intact (compared to HTAP architecture).
- Restricted scalability — server clusters are partitioned with DBA/admin intervention.
- Introduction of name-server/meta-server, making cluster management sophisticated.
- The name-server is critical and complex in ensuring business logic is performed distributively on the server clusters and with simple merge and aggregation functionalities on it before returning to the clients.
- Business logic may be required to cooperate with partitioning and querying.
Shard Architecture
Now, we can usher in the third school of distributed graph system design with unlimited scalability — the shard (see Table 1).
On the surface, the horizontal scalability of a sharding system also leverages name server and meta server as in the second school of design, but the main differences lie with the:
- Shard servers are genuinely shared.
- Name servers do NOT have knowledge about business logic (as in the second school) directly. Indirectly, it can roughly judge the category of business logic via automatic statistics collection. This decoupling is important, and it couldn't be achieved elegantly in the second school.
The sharded architecture has some variations; some vendor calls it fabrics (it's actually more like grid architecture in the secondary school), and others call it map-reduce, but we should deep dive into the core data processing logic to unravel the mystery.
There are only two types of data processing logic in shard architecture:
- Type 1: Data is processed mainly on name servers (or proxy servers)
- Type 2: Data is processed on sharded or partitioned servers as well as name servers.
Type 1 is typical, as you see in most map-reduce systems such as Hadoop; data are scattered across the highly distributed instances. However, they need to be lifted and shifted over to the name servers before they are processed there.
Type 2 is different in that the shard servers have the capacity to locally process the data (this is called: compute near or collocated with storage or data-centric computing) before they are aggregated and secondarily processed on the name servers.
As you would imagine, type 1 is easier to implement as it's a mature design scheme by many big-data frameworks; however, type 2 offers better performance with more sophisticated cluster design and query optimization. Shard servers in type-2 offer computing power, while type-1 has no such capability.
The graph below shows a type-2 shard design:
Sharding is nothing new from a traditional SQL or NoSQL big-data framework design perspective. However, sharding on graph data can be Pandora's box, and here is why:
- Multiple shards will increase I/O performance, particularly data ingestion speed.
- But multiple shards will significantly increase the turnaround time of any graph query that spans across multiple shards, such as path queries, k-hop queries, and most graph algorithms (the latency increase can be exponential!).
- Graph query planning and optimization can be extremely sophisticated, most vendors today have done very shallowly on this front, and there are tons of opportunities in deepening query optimization on-the-fly:
- Cascades (Heuristic vs. Cost)
- Partition-pruning (shard-pruning, actually)
- Index-choosing
- Statistics (Smart Estimation)
- Pushdown (making computing as close to the storage as possible) and more.
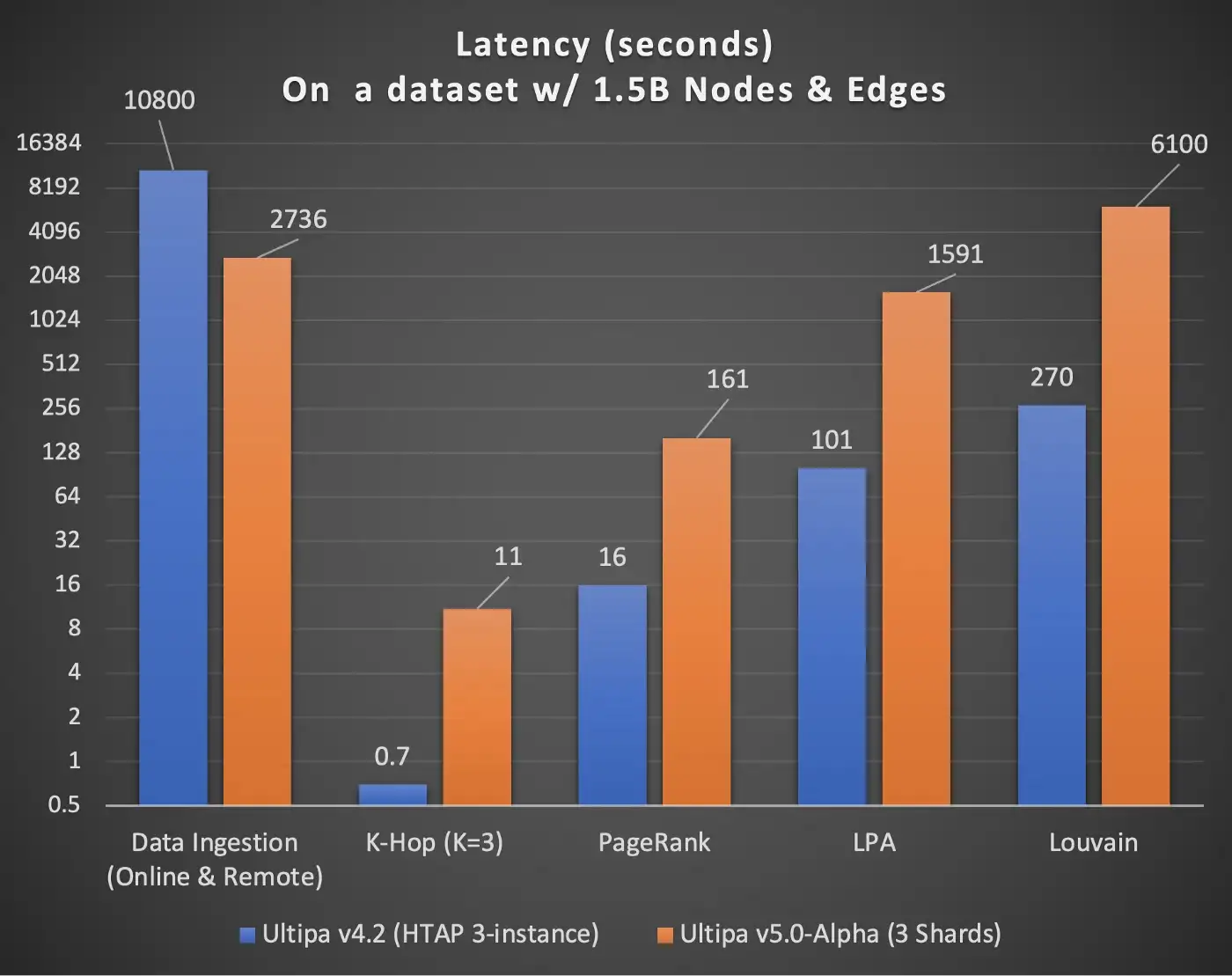
In Graph-7, we captured some preliminary findings on the Ultipa HTAP cluster and Ultipa Shard cluster; as you can see, data ingestion speed improves by four times (super-linear), but everything else tends to be slower by five times or more (PageRank slower by 10x, LPA by 16X, etc.)
Stay Tuned
There are tons of opportunities to continuously improve the performance of the sharding architecture. The team at Ultipa has realized that having a truly advanced cluster management mechanism and deeper query optimization on a horizontally scalable system are the keys to achieving endless scalability and satisfactory performance.
Lastly, the third schools of distributed graph system architectures illustrate the diversity and complexity involved when designing a sophisticated and competent graph system. Its course, it’s hard to say one architecture is absolutely superior to another, given cost, subjective preference, design philosophy, business logic, complexity-tolerance, serviceability, and many other factors — it would be prudent to conclude that the direction of architecture evolution for the long term clearly is to go from the first school to the second school and eventually to the third school. However, most customer scenarios can be satisfied with the first two schools, and human intelligence (DBA intervention) still makes pivotal sense in helping to achieve an equilibrium of performance and scalability, particularly in the second and third schools of designs.
Long live the formula:
Graph Augmented Intelligence = Human-intelligence + Machine’s-graph-computing-power
Published at DZone with permission of Ricky Sun. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments