What You Must Know About Rate Limiting
In this article, learn the basics of rate limiting, its advantages, how a rate-limiting system is designed, and the most popular rate-limiting algorithms.
Join the DZone community and get the full member experience.
Join For FreeRate limiting is the concept of controlling the amount of traffic being sent to a resource. How can you achieve this control? By means of a rate limiter – a component that lets you control the rate of network traffic to an API server or any other application that you want to protect.
Here’s a big-picture view of how a rate limiter sits in the context of a system.

For example, if a client sends 3 requests to a server but the server can only handle 2 requests, you can use a rate limiter to restrict the extra request from reaching the server.
The Need for Rate Limiting
Some of the strong reasons to have rate limiting in your system are as follows:
- Prevent system abuse by malicious actors trying to overwhelm your servers with an unusually large number of requests.
- To only allow traffic that your servers can actually handle at any given point in time.
- To limit the consumption of some costly resources from an external system.
- Prevent cascading failures in downstream systems when the top-level system gets disrupted by a large number of requests.
Key Concepts of Rate Limiting
There are 3 key concepts shared by every rate-limiting setup. No matter what type of rate-limiting algorithm you adopt, these 3 concepts come into play.
Here’s a quick look at each of them.

- Limit — It defines the maximum number of requests allowed by the system in a given time span. For example, Twitter (now X) recently rate limited unverified users to only view 600 tweets per day.
- Window — This is the time period for the limit. It can be anything from seconds to minutes to even days.
- Identifier — It’s a unique attribute that lets you distinguish between individual request owners. For example, things like a user ID or IP address can play the role of an identifier.
Designing a System With Rate Limiting
The basic premise of a rate limiter is quite simple. At a high level, you count the number of requests sent by a particular user or IP address or from a geographic location. If the count exceeds the allowable limit, you disallow the request.
However, behind the scenes, there are several considerations to be made while designing a rate limiter. For example:
- Where should you store the counters?
- What about the rules of rate limiting?
- How to respond to disallowed requests
- How to ensure that changes in rules are applied
- How to make sure that rate limiting doesn’t degrade the overall performance of the application
To balance all of these considerations, you need several pieces that work in combination with each other. Here’s an illustration that depicts such a system.
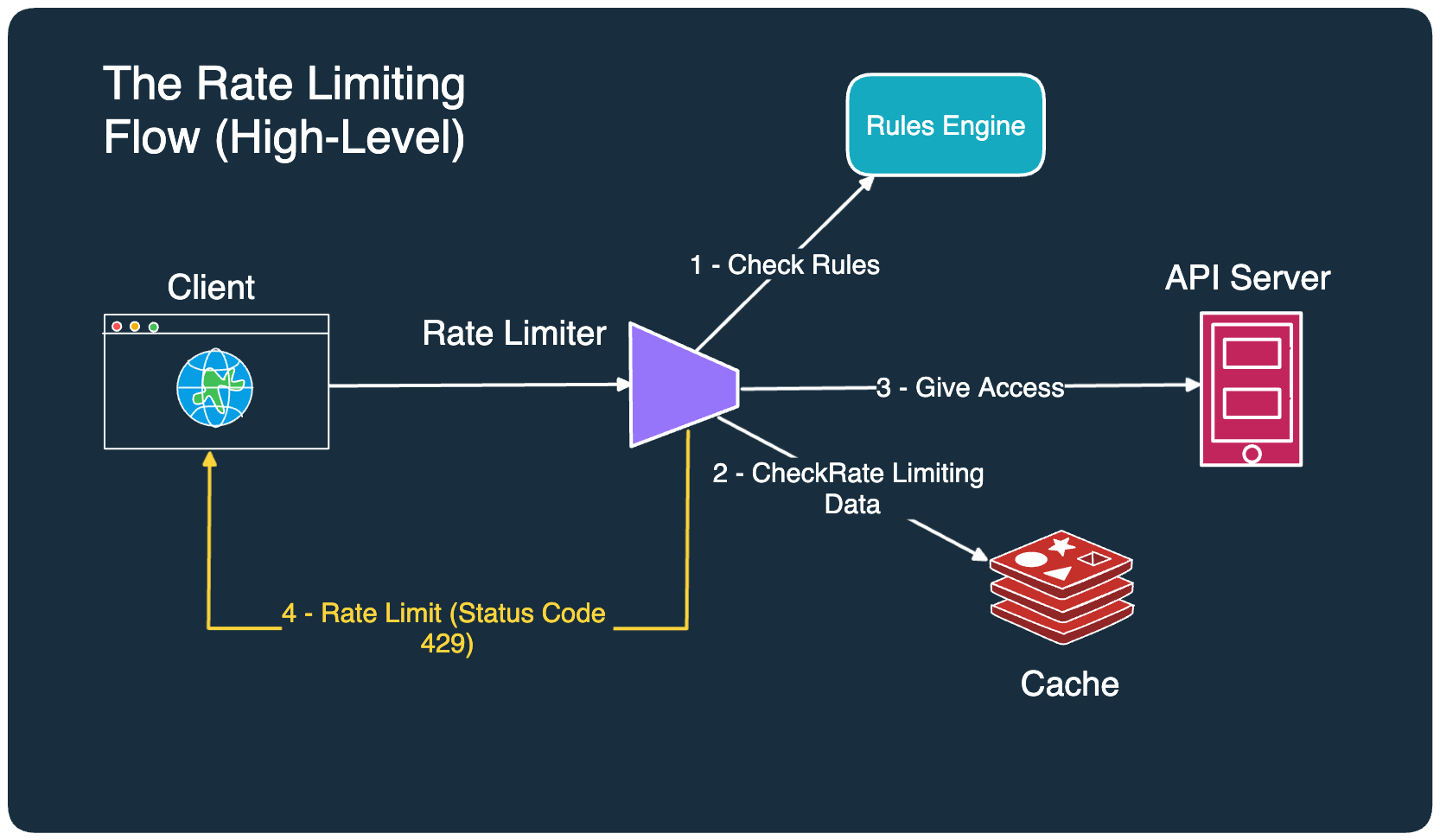
Let’s understand what’s going on over here:
- When a request comes to the API server, it first goes to the rate limiter component. The rate limiter checks the rules in the rules engine.
- The rate limiter proceeds to check the rate-limiting data stored in the cache. This data basically tells how many requests have already been served for a particular user or IP address. The reason for using a cache is to achieve high throughput.
- If the request falls within the acceptable threshold, the rate limiter allows it to go to the API server.
- If the request exceeds the limit, the rate limiter disallows the request and informs the client or the user that they have been rate-limited. A common way is to return HTTP status code 429 (too many requests).
Possible Improvements
Now, there are a couple of improvements you can have here:
- First, instead of returning HTTP status code 429, you can also simply drop a request silently. This is a useful trick to fool an attacker into thinking that the request has been accepted even when the rate limiter has actually dropped the request completely.
- Second, you could also have a cache in front of the rules engine to increase the performance. In case of updates to the rules, you could have a background worker process updating the cache with the latest set of rules.
Rate Limiting Algorithms
Though each algorithm requires a detailed discussion, here we will look at the most popular ones in brief.

Fixed Window Counter
This is probably the simplest rate-limiting algorithm out there. In this algorithm, we divide the time into fixed time windows. For each window, we maintain a counter. Every incoming request increments the counter by one and when the counter reaches the maximum limit, the subsequent requests are dropped until a new time window starts.
Though this algorithm is simple and easy to understand, it has a big problem. A spike in traffic at the edges of the time window can cause a huge number of requests to pass through in a short amount of time and overwhelm the server.
If interested, check out my post on the basic implementation of the fixed window rate limiting algorithm.
Sliding Window Log
The sliding window log solves the problem with the fixed window algorithm. Instead of having a fixed time window, it keeps a sliding time window.
For each request, the algorithm keeps track of the request timestamp within a cache. When a new request comes in, it removes all the outdated timestamps that are older than the start of the current time window. If the size of the log is within the allowed limit, a request is accepted. Otherwise, it is rejected.
Of course, this algorithm suffers from the problem of consuming a lot of memory because you’ve got to keep track of all timestamps.
Sliding Window Counter
The sliding window counter combines the best of the fixed window and sliding window.
Instead of storing timestamps, this algorithm maintains a counter for a sliding window. To determine whether to accept or drop a new request, it basically calculates the sum of requests in the current window and adds it to the approximation of requests in the previous window. The approximation of requests in the previous window is calculated by multiplying the total number of requests in the previous window by the overlap percentage of the sliding window.
The advantage of this algorithm is that it smooths out traffic spikes and is memory efficient. However, it does not calculate an exact number of requests but deals with an approximation.
Token Bucket
The token bucket algorithm is a pretty popular algorithm for rate limiting.
In this algorithm, we create a bucket of tokens with a pre-defined capacity. Tokens are placed into the bucket at a preset rate. Once the bucket is full, no more tokens are added. Whenever a new request comes, it consumes a token. If there are no tokens available in the bucket, the rate limiter drops the request.
The benefit of this approach is that it allows a burst of traffic to go through for short periods of time.
The main challenge is tuning the combination of bucket size and token refill rate.
Leaking Bucket
The leaking bucket algorithm is quite similar to the token bucket. The only difference is that the requests are processed at a fixed rate.
It is implemented with a FIFO approach. When a request arrives, the system checks if the queue is full. If not, the request is added to the queue otherwise it’s dropped.
Requests in the queue are processed at a fixed rate to avoid overwhelming the server.
Use Cases of a Rate Limiter
While it might be easy to think of a rate limiter as protecting your system from external requests, it can also help you internally.
Before we end this introduction post, let’s look at some of the prominent use cases of a rate limiter including both external and internal use cases.
- Prevent catastrophic DDoS attacks — This is done by identifying malicious IP addresses, users, or request tokens that are trying to overwhelm the system. Requests are dropped depending on the algorithm.
- Gracefully handle a surge of users — Not all traffic is malicious and sometimes your website may attract a surge of legitimate traffic. However, if you don’t have the capacity to handle the increase in traffic, it’s better to handle things gracefully rather than presenting users with a failure screen.
- Multi-tiered pricing — This is an internal use case where you may want to offer different usage levels to users belonging to different tiers. This is a typical requirement for a lot of on-demand SaaS services.
- Not overusing a third-party system — This is another internal use case where you might want to keep a lid on the number of API calls you are making to an expensive 3rd party API (such as a deep learning model). You can use rate limiting to restrict the number of calls.
- Protect an unprotected system — Sometimes, we may want to deal with an unprotected system with caution. For example, if you are looking to hard delete a million records from a database, you run the risk of bringing the DB down if you perform the operation at once. You can leverage a rate-limiting algorithm to distribute the deletes uniformly.
Conclusion
Rate limiting is an important tool to build systems with a strong level of availability. In this post, we have only covered the top-level view of the rate-limiting landscape and why we need it in the first place. Each of the algorithms mentioned in this post has its own theoretical foundation and practical considerations.
If you have any queries or comments, please feel free to mention them in the comments section below.
Published at DZone with permission of Saurabh Dashora. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments