When Doris Meets Iceberg: A Data Engineer's Redemption
Apache Doris and Iceberg are redefining the way data lakes work. It's not just a simple 1+1=2; it brings a qualitative leap!
Join the DZone community and get the full member experience.
Join For FreeWaking up in the middle of the night due to a data bug again, have you ever dreamed of an ideal data world where queries return in seconds, data is never lost, and costs are so low that your boss is smiling? Sounds like a dream? No! This is becoming a reality.
Remember that night you were crushed by data partitioning issues, with the product manager frantically pushing for progress while you struggled with scattered data? Cross-source queries were as slow as a snail climbing a mountain, and schema changes required coordination across seven departments.
But now, these pain points are being rewritten.
The combination of Apache Doris and Iceberg is redefining the way data lakes work. It's not just a simple 1+1=2; it brings a qualitative leap: second-level queries, seamless schema evolution, and true data consistency guarantees.
The Perfect Symphony of Doris and Iceberg
In the field of data engineering, we often encounter such problems:
Xiao Zhang is working on a data analysis requirement, needing to analyze user behavior data from the past three months. The data is scattered across Hive data warehouses, business databases, and object storage. Cross-source Join performance is poor, with queries taking over 40 minutes, and data inconsistency often occurs.
Moreover, Xiao Zhang also has to deal with data governance work, and each table structure change gives him a headache. Multiple downstream applications depend on these tables, and schema changes require coordination across multiple teams, possibly taking a week to complete a single change.
These issues have become more prominent with the explosive growth of data. The traditional separation of data warehouses and data lakes can no longer meet the needs.
Fortunately, in version 2.1, Apache Doris' lakehouse architecture has been significantly enhanced. It not only improves the reading and writing capabilities of mainstream data lake formats (Hudi, Iceberg, Paimon, etc.) but also introduces multi-SQL dialect compatibility, allowing seamless switching from existing systems to Apache Doris. In data science and large-scale data reading scenarios, Doris integrates the Arrow Flight high-speed reading interface, achieving a 100x improvement in data transfer efficiency.
Thus, Xiao Zhang decided to use Doris + Iceberg for his redemption.
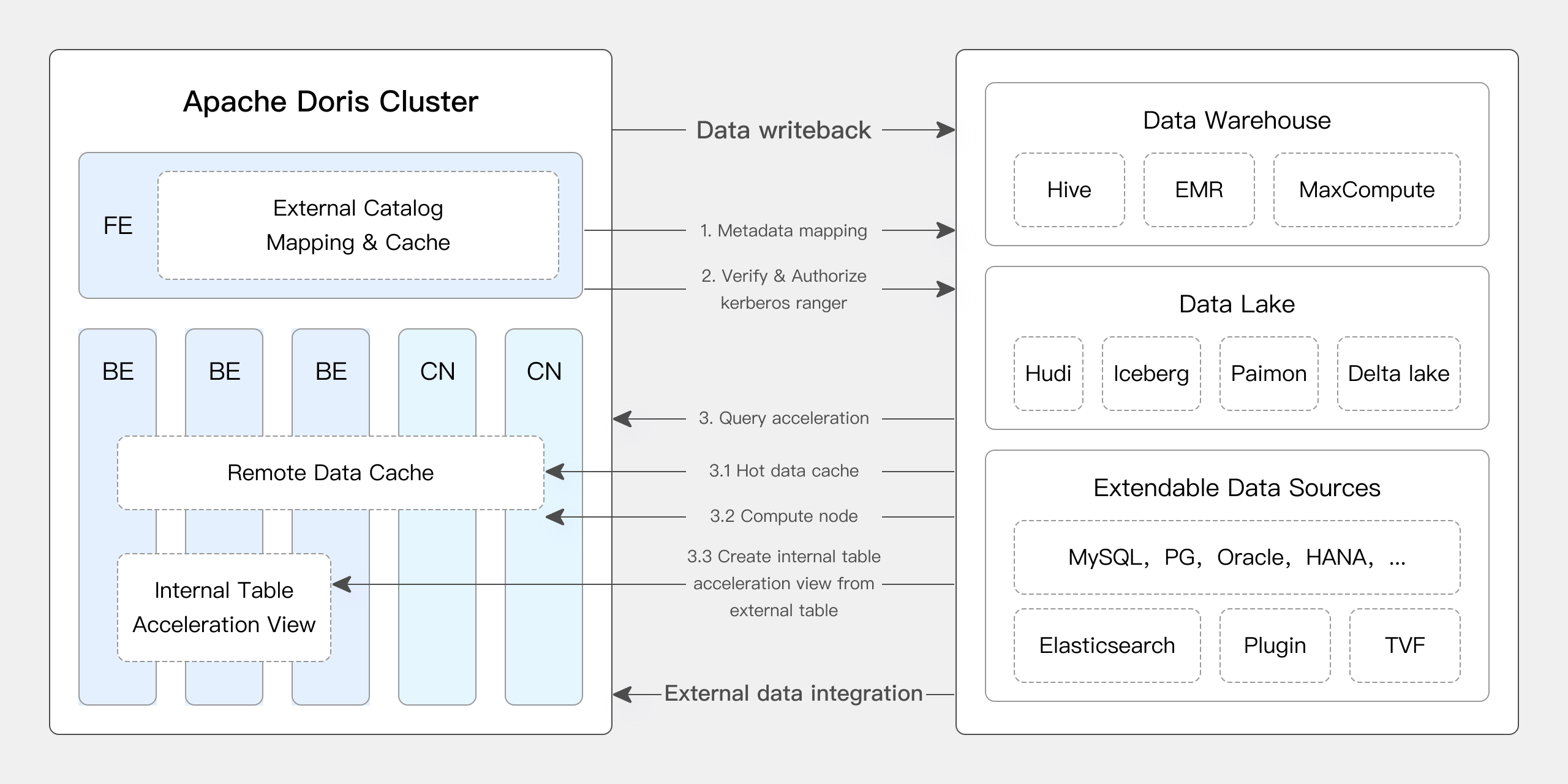
Apache Doris provides native support for many core features of Iceberg:
- Supports various Iceberg Catalog types such as Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore, and DLF.
- Natively supports Iceberg V1/V2 table formats, as well as reading Position Delete and Equality Delete files.
- Supports querying Iceberg table snapshot history through table functions.
- Supports time travel functionality.
- Natively supports the Iceberg table engine. Apache Doris can directly create, manage, and write data into Iceberg tables. It supports a complete set of partition transform functions, providing capabilities such as hidden partitions and partition layout evolution.
Additionally, version 2.1.6 of Doris brought significant upgrades to Doris + Iceberg:
Apache Doris supports DDL and DML operations on Iceberg. Users can directly create databases and tables in Iceberg through Apache Doris and write data into Iceberg tables.
Through this feature, users can perform complete data queries and write operations on Iceberg using Apache Doris, further simplifying the lakehouse architecture.
Therefore, Xiao Zhang can quickly build an efficient lakehouse solution based on Apache Doris + Apache Iceberg to flexibly meet various needs for real-time data analysis and processing:
- Use Doris' high-performance query engine to join and analyze data from Iceberg tables and other data sources, building a unified federated data analysis platform.
- Directly manage and build Iceberg tables in Doris, clean and process data, and write it into Iceberg tables, building a unified lakehouse data processing platform.
- Share Doris data with other upstream and downstream systems for further processing through the Iceberg table engine, building a unified open data storage platform.
This is no longer a simple surface integration but a deep fusion of lakehouse architectures!
Practical Summary of Doris and Iceberg
After a series of ups and downs in exploration and practice, Xiao Zhang has summarized some practical experiences with Doris + Iceberg:
Intelligent Metadata Management
In traditional solutions, metadata management has always been a thorny issue. Table partition information, file locations, and schema change histories are scattered everywhere, leading to poor query performance and complex operations and maintenance.
Doris + Iceberg provides a unified metadata management layer:
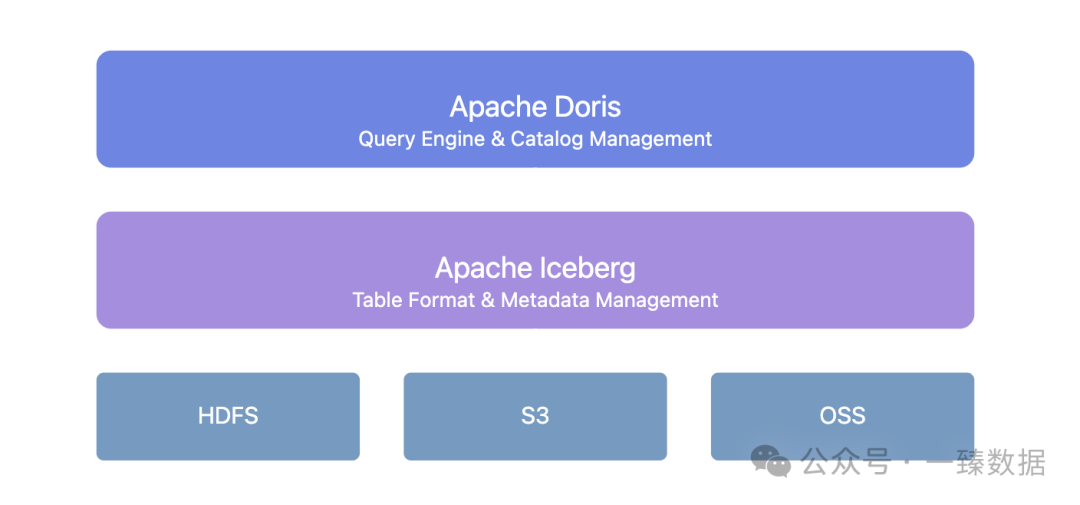
This architecture brings several key values:
- Seamless schema evolution: Table structure changes no longer require downtime. Doris + Iceberg supports adding, deleting, and modifying fields, as well as adjusting partitioning methods.
- Data version management: Through Iceberg's snapshot mechanism, you can revert to the data state at any point in time.
- Unified catalog service: Supports various Iceberg Catalog types such as Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore, and DLF, seamlessly integrating with existing infrastructure.
Xiao Zhang can now complete schema changes with a single ALTER TABLE statement. The system automatically handles compatibility, and downstream applications remain unaware of the changes.
Efficient Data Organization
Doris innovatively combines the MPP engine with Iceberg's data organization methods:
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);This SQL statement hides powerful technical mechanisms:
- File organization: Supports common storage media such as HDFS and object storage.
- Smart partitioning: Supports partition transform functions to enable Iceberg's implicit partitioning and partition evolution features.
- Storage optimization: Supports columnar storage formats like Parquet and ORC, combined with various compression methods to enhance performance.
With Doris' support for DDL and DML operations on Iceberg, data consistency issues are also completely resolved.
Operations and Maintenance Management
To ensure the stability of the data platform, Xiao Zhang uses the following methods to monitor and manage Iceberg tables:
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...This toolchain provides:
- Metric monitoring: Real-time control of table status and snapshot metrics.
- Snapshot management: Clean up expired snapshots to release storage space.
- Fault recovery: Supports rolling back to any historical version (reading historical version data based on snapshot ID or snapshot creation time).
Through these practices, Xiao Zhang's data platform based on Doris + Iceberg has reached new heights:
- Query performance improved by 300%.
- Storage costs reduced by 40%.
- Operations and maintenance efficiency increased by 200%.
The exciting journey of Doris' lakehouse is never-ending.
Stay tuned for more interesting, useful, and valuable content in the next issue!
Opinions expressed by DZone contributors are their own.
Comments