When Kubernetes Breaks Session Consistency: Using Cosmos DB and Redis Together
Cosmos DB stores durable state; Redis acts as a coordination layer, enabling predictable, stateless scaling without sticky sessions, strong consistency, or high costs.
Join the DZone community and get the full member experience.
Join For FreeDistributed systems rarely struggle because of storage engines. They struggle because of coordination.
We were operating a high-throughput microservice on Kubernetes backed by Azure Cosmos DB. The service required durability, global availability, and predictable read behavior under horizontal scaling. Cosmos DB was configured with SESSION consistency because it offers a practical balance between correctness and performance. It guarantees read-your-own-writes without incurring the latency and throughput penalties associated with strong consistency.
Architecturally, everything appeared sound.
Yet under real production traffic, an intermittent pattern began emerging. Occasionally, a read request issued immediately after a write would return slightly stale data. There was no corruption and no failure — just subtle inconsistencies that were difficult to reproduce but impossible to ignore.
The issue was not rooted in Cosmos DB alone, nor in Kubernetes alone. It lived in the interaction between the two.
The Assumption Behind Session Consistency
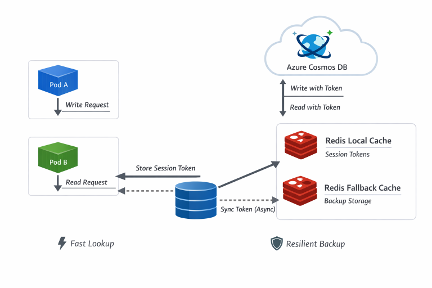
Cosmos DB’s session consistency model relies on a session token. Every write operation returns a token representing the latest version of the document within that session. If that token is passed back during a subsequent read, Cosmos guarantees that the client will see its own write.
In a single-instance application, this is straightforward. The same process that performs the write retains the session token in memory and uses it for subsequent reads.
Kubernetes changes that assumption entirely.
In a horizontally scaled deployment, a write request may land on Pod A. Cosmos returns a session token to Pod A. The next read request for the same document may land on Pod B. Pod B has no awareness of Pod A’s session token. Without that token, Cosmos may return a slightly older replica version consistent with session guarantees — but not necessarily reflecting the most recent write handled by another pod.
The database is honoring its consistency contract. The application simply is not sharing the required metadata across instances.
This is a classic distributed systems nuance: guarantees often depend on contextual state that stateless infrastructure does not preserve.
Why Strong Consistency Was Not the Right Fix
Switching Cosmos DB to strong consistency would have eliminated the problem entirely. However, that solution carried significant tradeoffs.
Strong consistency increases latency because replicas must coordinate synchronously. It reduces overall throughput and increases RU consumption. It also introduces constraints in multi-region deployments where low-latency global reads are required.
The problem was not that the database guarantees were insufficient. The problem was that session context was not shared across pods.
Rather than strengthening storage semantics, we focused on improving coordination.
Introducing Redis as a Coordination Layer
The solution was conceptually simple. After every write to Cosmos DB, we extracted the returned session token and stored it in Redis, keyed by the document ID. Before every read from Cosmos, we retrieved the session token from Redis and supplied it with the read request.
Redis became a lightweight session token broker between Kubernetes pods.
It is important to emphasize what Redis was not used for. It did not store business data. It did not act as a second database. It did not cache full documents. It stored only the small piece of metadata required to preserve cross-pod session guarantees.
Cosmos remained the durable system of record. Redis handled coordination.
By limiting Redis to this narrow responsibility, the architecture avoided unnecessary complexity and eliminated the risk of data divergence between systems.
Designing for Failure, Not Just Success
Adding Redis introduced a new dependency, which required careful design consideration. We made a deliberate decision that Redis would never become mandatory for availability.
In the read path, the service first attempts to retrieve the session token from Redis. If a token exists, it is passed to Cosmos, ensuring read-your-own-writes. If Redis is unavailable or the token is missing, the system proceeds with a standard Cosmos read without the token.
The result is a graceful degradation model. Redis enhances consistency but does not control system availability. If Redis fails completely, the application continues operating with normal session semantics, potentially returning slightly stale reads but never failing outright.
On the write path, the order of operations is equally important. The document is first persisted to Cosmos. Only after a successful write is the session token stored in Redis. This ensures that durability is never dependent on coordination infrastructure.
To further strengthen resilience, Redis was deployed in a dual configuration consisting of a primary and fallback instance. Writes are performed against both, with the fallback update executed asynchronously to avoid increasing request latency. If Redis writes fail, the errors are logged, but the core transaction succeeds.
This ordering ensures the system bends under failure rather than breaks.
Cost and Throughput Optimization
While addressing consistency, we also examined write efficiency. In high-throughput systems, replacing entire documents for minor state changes can significantly increase RU consumption.
Instead of issuing full document replacements, we adopted Cosmos PATCH operations for partial updates. Only modified attributes were updated, reducing request charge and improving overall efficiency.
This adjustment produced measurable cost savings and reinforced a broader lesson: architectural improvements often reveal opportunities for operational optimization.
Evaluating Alternative Approaches
Before settling on Redis-backed session sharing, several alternatives were considered.
Sticky sessions at the load balancer layer could have preserved session affinity, ensuring that reads followed writes to the same pod. However, this approach reduces horizontal scaling flexibility and can create uneven traffic distribution.
In-memory distributed caching strategies were also evaluated but introduce replication complexity and failure coordination challenges.
Enabling strong consistency at the database layer, while technically simpler, imposed unacceptable performance and cost penalties.
Redis provided the right balance. It is fast, operationally mature, and purpose-built for ephemeral coordination data. Most importantly, it allowed us to solve a coordination problem without modifying database guarantees.
Extending Redis Carefully
Once Redis became part of the architecture, it was tempting to broaden its use. Discipline was critical.
Redis was later used to cache selected reference metadata retrieved from downstream services. Instead of invoking dependent systems on every request, a scheduled refresher populated Redis entries with defined TTLs. This reduced latency and protected downstream systems during peak load.
Redis was also used to maintain shared operational counters across pods. In a horizontally scaled environment, in-memory metrics fragment across instances. Storing certain counters in Redis provided consistent observability across all running pods.
In both cases, Redis remained coordination infrastructure rather than primary storage.
The Architectural Pattern
Cosmos DB and Redis are often described simply as database and cache. In this design, Redis is not a cache of business objects. It is a coordination layer that enables predictable behavior in a stateless, horizontally scaled environment.
By separating durable state from coordination state, the system maintains scalability, controls cost, and preserves session guarantees without relying on strong consistency or sticky sessions.
Kubernetes encourages statelessness. Databases provide consistency guarantees within defined boundaries. Bridging the two requires explicit coordination.
Distributed systems are rarely about choosing the strongest guarantee available. They are about understanding the guarantees you already have and ensuring they are applied correctly across infrastructure boundaries.
Sometimes the most effective solution is not increasing consistency but ensuring that the consistency you already depend on is shared intelligently.
Architecture Diagram
Opinions expressed by DZone contributors are their own.
Comments