When Similarity Isn’t Accuracy in GenAI: Vector RAG vs GraphRAG
Vector RAG is good for semantically similar retrieval, but GraphRAG adds missing entity relationships and reasoning required for deterministic entity grounding.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-augmented generation (RAG) based applications are being developed in high numbers with the advent of large language models (LLM) models. We are observing numerous use cases evolving around RAG and similar mechanisms, where we provide the enterprise context to LLMs to answer enterprise-specific questions.
Today, most enterprises have developed, or are in the process of developing, a knowledge base based on the plethora of documents and content they have accumulated over the years. Billions of documents are going through parsing, chunking, and tokenization, and finally, vector embeddings are getting generated and stored in vector stores.
Enterprises are trying to start with internal chat applications for employees or internal customers, providing natural language chat interfaces to query their enterprise knowledge, with a disclaimer that it’s AI-generated content and may not be 100% accurate. This knowledge base is generated using vector RAG from various technical documents, compliance, and regulatory documents, policies documents. Enterprises are even trying to take it to external customers as well.
However, these customer-facing use cases are quality-sensitive; generated responses can’t go wrong, as correctness and completeness are most important. This is where most use cases don’t pass the production-grade eval, and they get stuck in a continuous loop of accuracy improvements through more chunks, better embeddings, reranking, and improved prompt engineering. None of these fully resolves a certain level of incorrect answers.
This is the point when you realise that semantic similarity is not always accurate.
In this article, I've explained "when similarity-based retrieval breaks," which also leads to the failure of the architectural assumption. This leads to the incorporation of graph-enhanced retrieval.
Notes
I’ve attached snapshots of my proof-of-concept for this analysis, which include the tools referenced, but this is not intended to promote any specific tool or framework. The sole purpose of this article is to clarify the architectural trade-offs while making your decision for the RAG system.
For this analysis, I’ve used a document with entries of 100 students, and their details about where they have graduated from (25 unique universities) and where they work now (25 unique organisations). For example:
Student1 graduated from University11. Student1 now works at Company19.
Student2 graduated from University16. Student2 now works at Company15.
.
.
Student28 graduated from University10. Student28 now works at Company19.
Student29 graduated from University9. Student29 now works at Company22.The scope of this analysis includes two variations of RAG:
- 1st uses standard vector embedding-based RAG.
- 2nd one uses a Hybrid RAG, which combines both vector RAG and GraphRAG.
Let’s Understand Vector RAG and Its Limitations
Vector RAG works by:
- Chunking documents
- Generating embeddings and storing those in vector databases
- Retrieving the most semantically similar chunks by using nearest neighbours search in the vector store
- Passing them to an LLM to generate the answer in the context of the semantically similar content
The following snapshot is the vector embeddings created for the above data. This is reduced to two dimensions for visualization and used for similarity search using the nearest-neighbour algorithm.
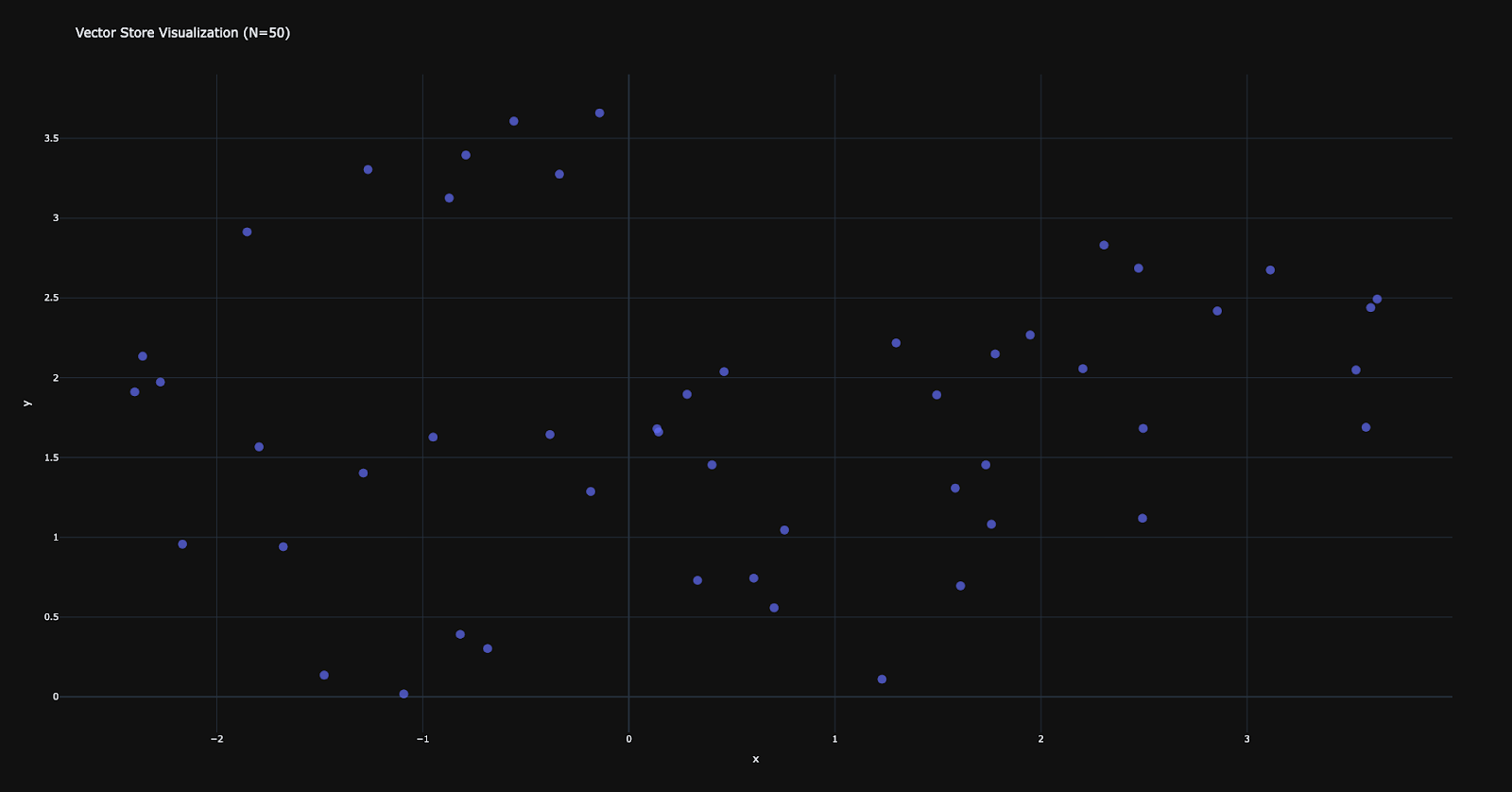
Snapshot 1: Vector embeddings reduced to two dimensions
This captures semantic similarity but does not model structured logic. As the above snapshot gives us a sense, Nearest-neighbour search retrieves what is close, not what is logically related and required for answering the question accurately.
It is quite clear that we assume that semantically similar content means it's factually complete. This assumption fails as soon as a question requires reasoning across multiple entities present in multiple documents, and which are not semantically similar but have an entity relationship. For example, suppose in a simple text document, we have multiple lines spread across multiple sections/pages like the following.
Alice graduated from MIT.
.
.
.
Bob graduated from Stanford.
.
.
.
Alice works at OpenAI.
.
.
.
Bob works at Google.
.
.
.If I ask the question "Where do both Alice and Bob work?" It may retrieve the following:
Alice works at OpenAI.
Bob works at Google.
Or
Alice works at OpenAI.
Or
Bob works at Google.The retrieve has no notion that two entities of type Person are involved, and two entities of type Organisation are also involved, and there is a relationship comparison required to answer the question.
Hence, partial context is common, and accuracy becomes probabilistic rather than deterministic.
I developed the following FAISS vector-store-based retriever and set the retrieval config to return the two most relevant chunks.
def get_vector_retriever():
if not os.path.exists(VECTOR_FOLDER):
raise ValueError("Vector index not found. Run ingestion first.")
embeddings = GoogleGenerativeAIEmbeddings(model="text-embedding-004")
vector_store = FAISS.load_local(VECTOR_FOLDER, embeddings, allow_dangerous_deserialization=True)
return vector_store.as_retriever(search_kwargs={"k": 2})Using this retriever, I developed the following vector chain method to answer the question based on the context retrieved. I used a simple prompt to request the LLM to generate the answer.
def get_vector_chain():
retriever = get_vector_retriever()
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0)
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return chainI exposed this as a simple FastAPI and conducted a couple of evaluations.
@app.post("/query/vector")
async def query_vector(request: QueryRequest):
try:
chain = get_vector_chain()
response = chain.invoke(request.question)
return {"answer": response}
except ValueError as e:
raise HTTPException(status_code=500, detail=str(e))
except Exception as e:
raise HTTPException(status_code=500, detail=f"Internal Server Error: {str(e)}")
I conducted my first test in which details of two different Students were asked. I wanted to validate that when two entities are being questioned, does my VectorStoreRetriever retrieve both entities or not? You can see the same in the following LangSmith tracing snapshots, where the user's query is "Where do both Student1 and Student35 work?"
Observation: You can see the VectorStoreRetriever fetches the content that is nearer to Student35, and it completely misses Student1.
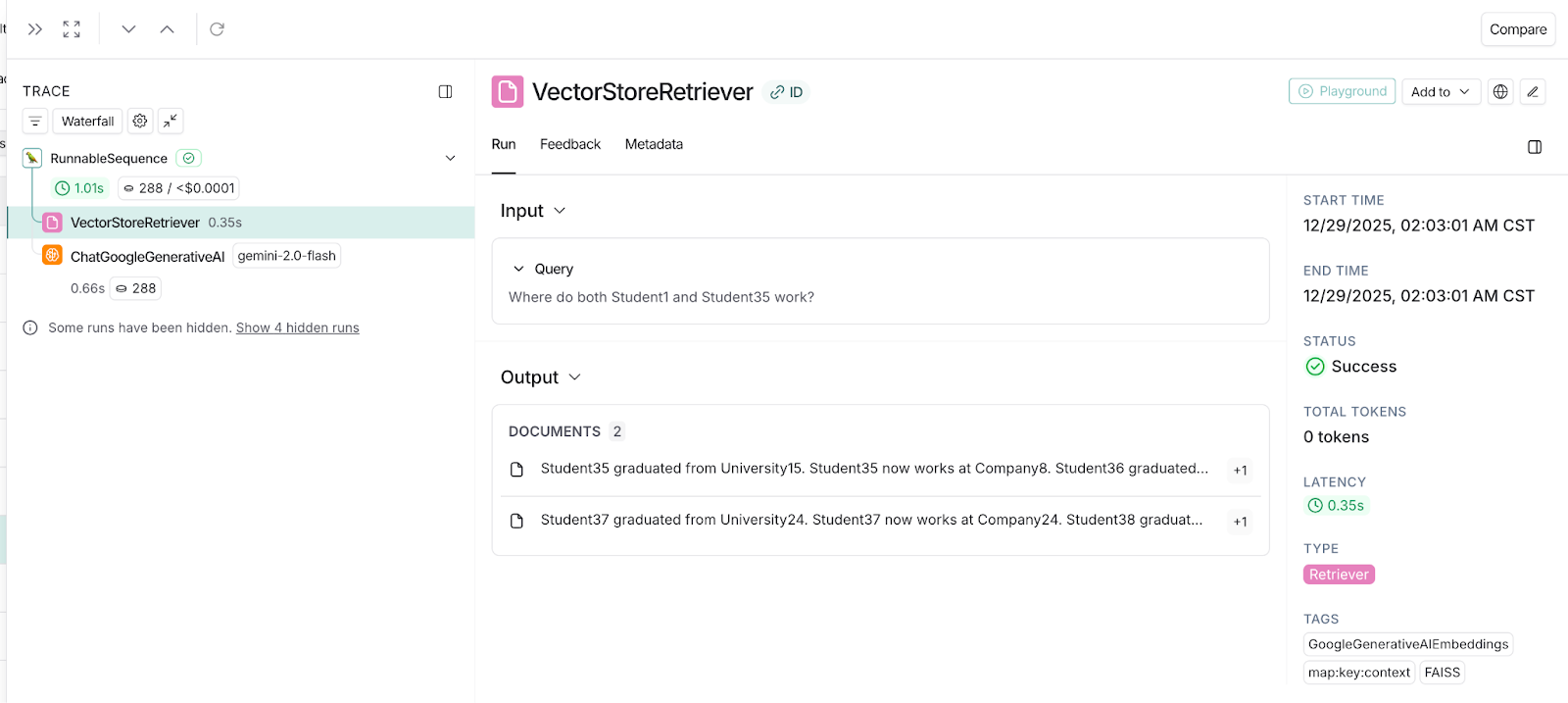
Snapshot 2: LangSmith traces showing partial context fetched from VectorStore (Student1 details are missing)
Based on this context, Vector Chain invokes the LLM.
Observation: You can see the answer generated by LLM is neither complete nor completely accurate. It answers correctly for Student35, but not for Student1.
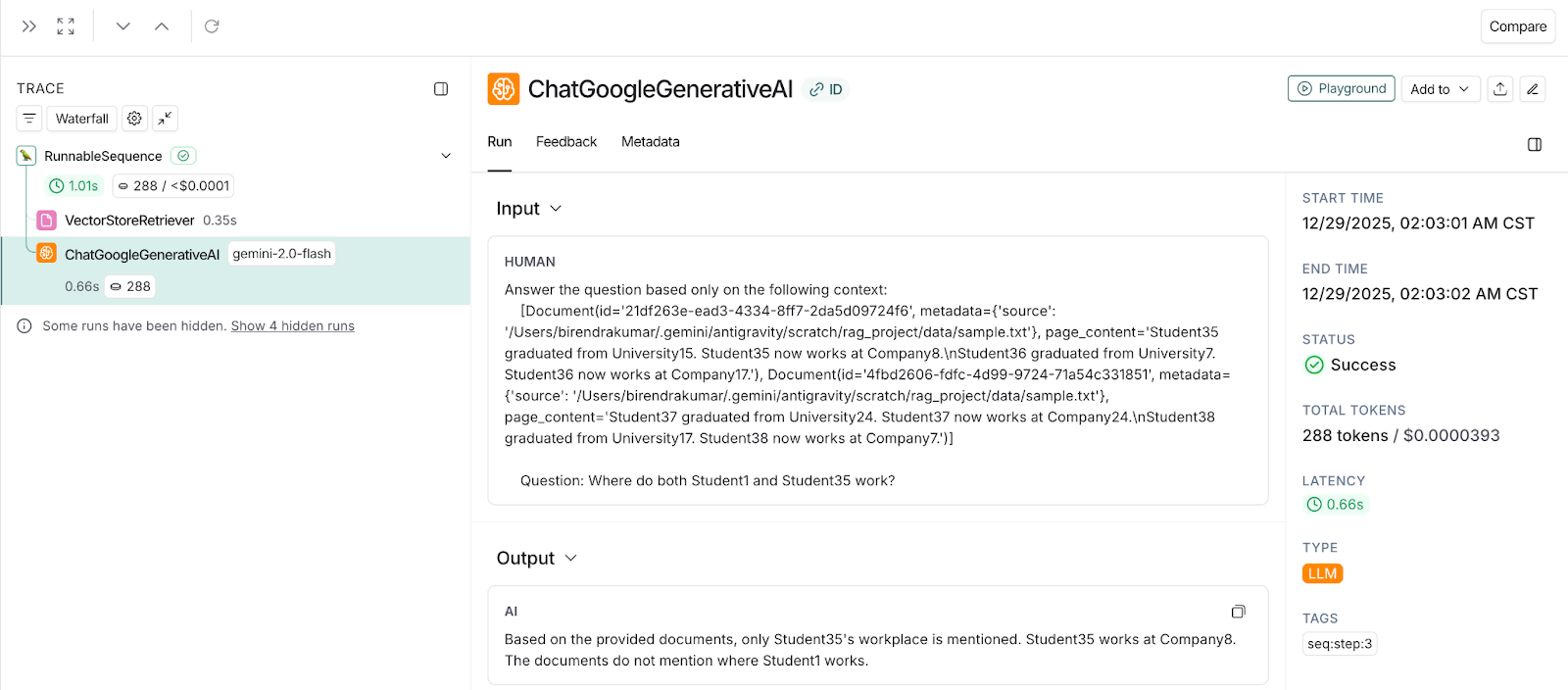
Snapshot 3: LangSmith traces showing a partial answer generated based on a partial context
I conducted another test where multiple entities are involved, which need to fetch these entities based on the relationship. In this test, the question is, "Who all Persons have graduated from the same university from which Student1 has graduated?" As you can see, first the university of Student1 has to be fetched, then all Students who have graduated from the same university. This test will not work using semantic similar content alone. However, let’s observe the behaviour.
Observation: VectorStoreRetriever has not been able to fetch all the correct associated entities; the same can be seen in the following snapshot. It couldn’t establish the relationship between the entities.
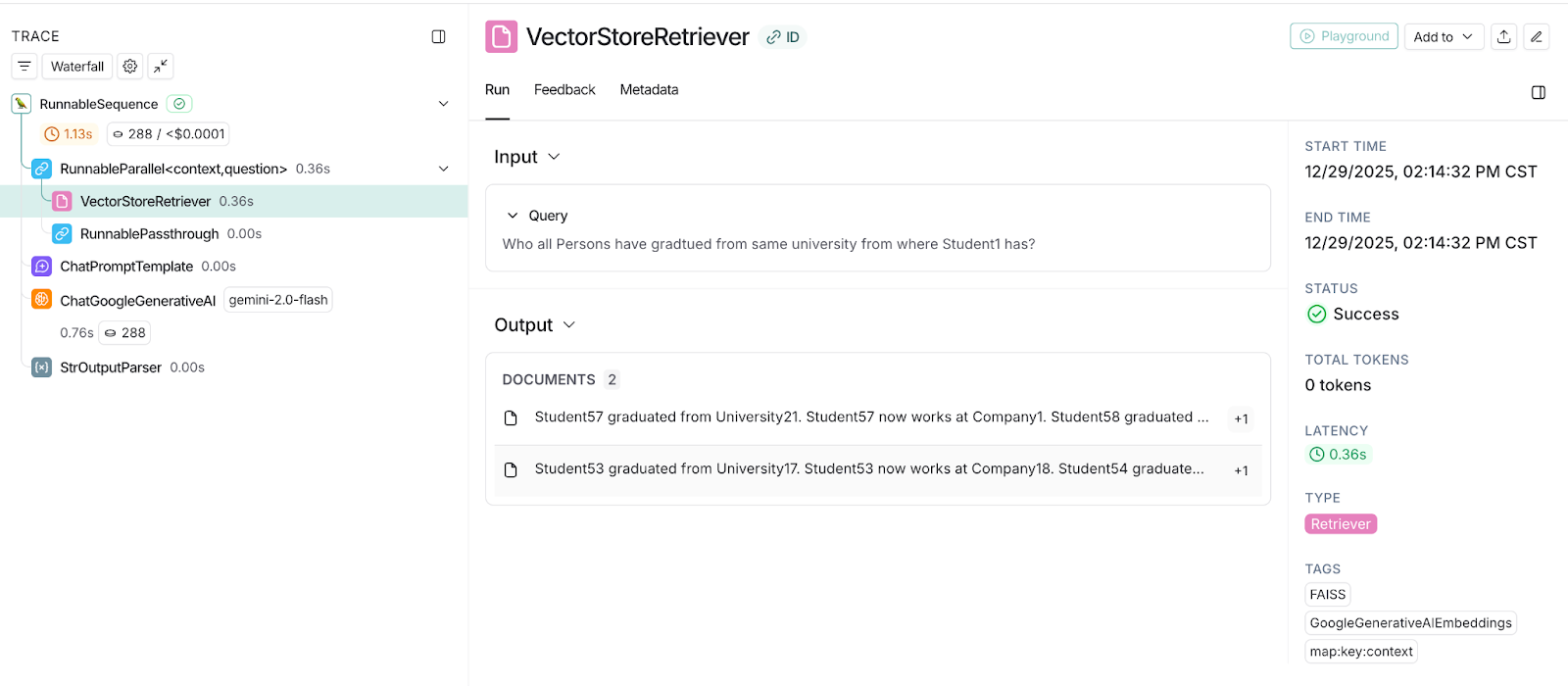
Now, Vector Chain executes LLM with this context, LLM says it does not have information about Student1 university, hence it can’t determine who graduated from the same university. You can see the same in the output section of the following snapshot.
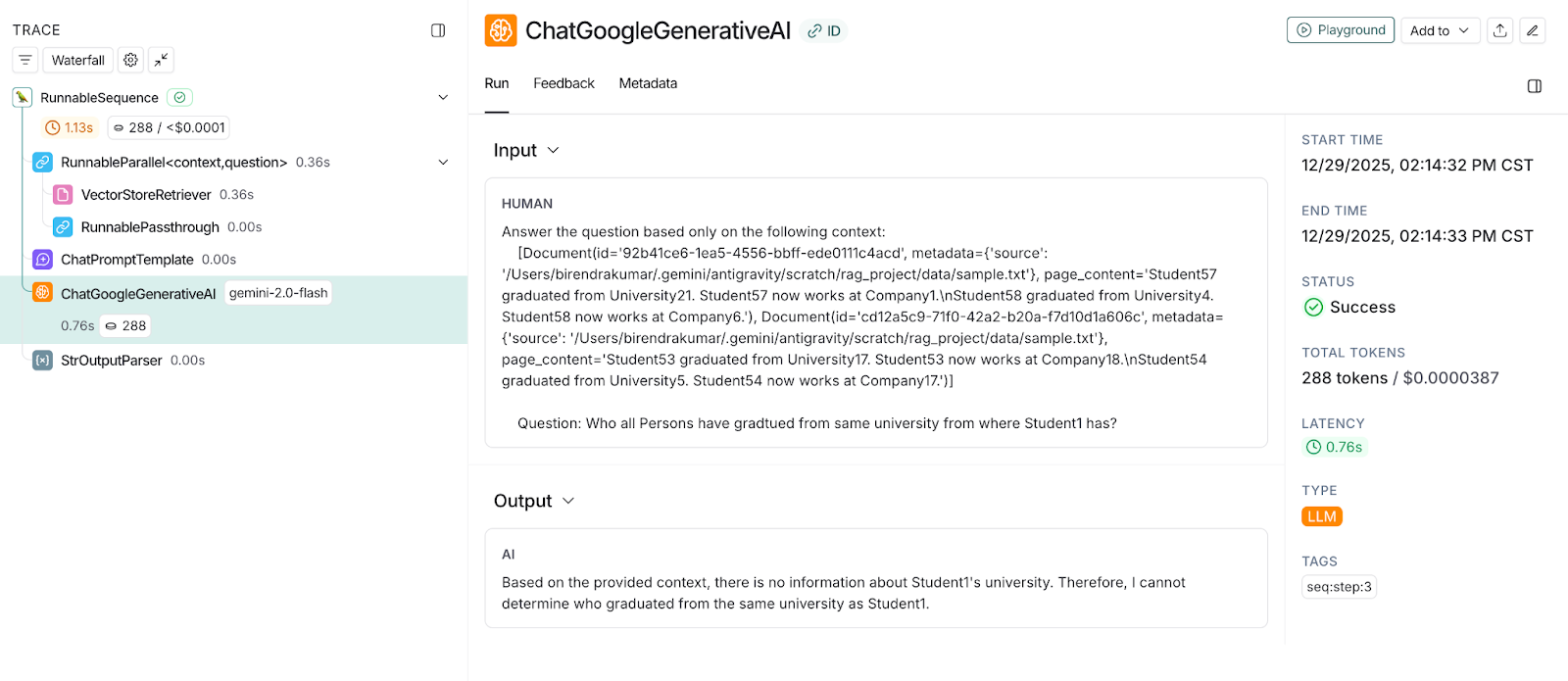
This is where GraphRAG (graph-enhanced RAG or knowledge graph RAG) becomes valuable to enhance the accuracy of a knowledge graph built from the same content. This provides relational reasoning and fact consistency, especially for queries that involve relationship or multi-step reasoning.
Why Semantic Similarity Is Not Enough
Vector embeddings manage the nearness or proximity of meaning. As you can understand from the Snapshot1. This vector space does not manage factual relationships between entities.
Nearest-neighbour searches vector embeddings that are nearer to the vector embeddings of the question, but it can not search for the facts that are required to answer the question completely.
Later on, it is quite important when a question arises for multi-entities, comparison queries, joins (both, same and different), and enterprise data with structure.
What GraphRAG Does Differently Than Vector RAG
GraphRAG enhances RAG with a knowledge graph that has entities and relationships.
Like in the above example, I’ve modelled the entities and relationship like following:
Entities (Person, Organization, University)
Relationships (WORKS_AT, GRADUATED_FROM)
The following Neo4j snapshot shows these entities and relationships:
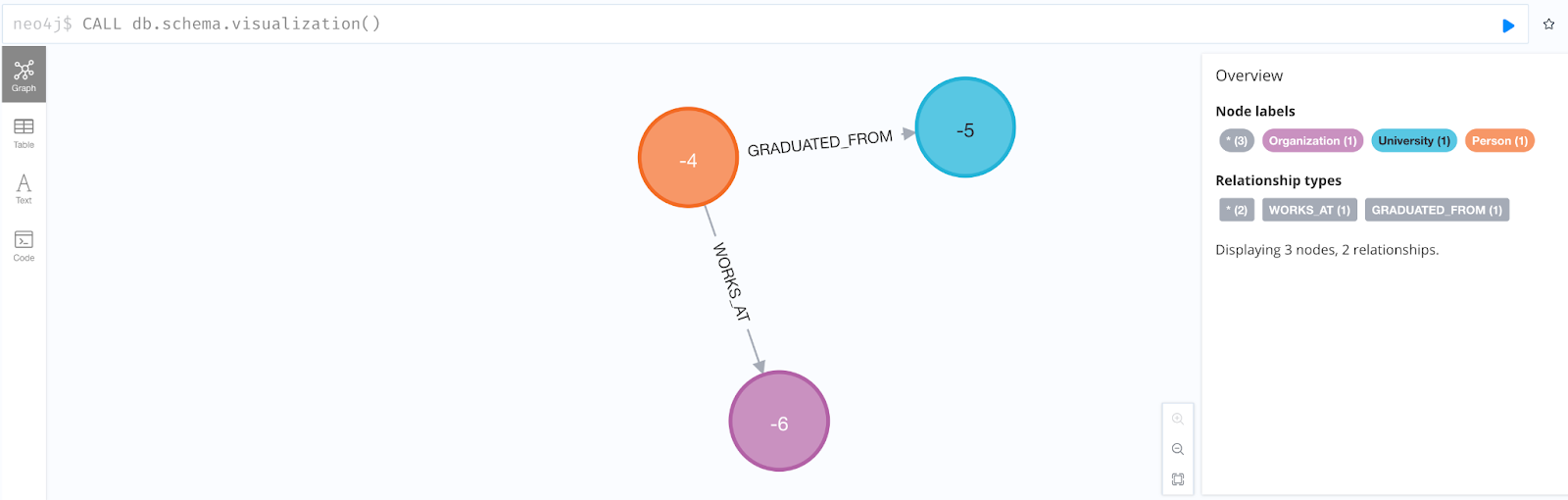
You can see the following relationships above:
(Person)-[:WORKS_AT]->(Organization)
(Person)-[:GRADUATED_FROM]->(University)
Based on these entities and relationships, the following knowledge graph is created from the same text document.
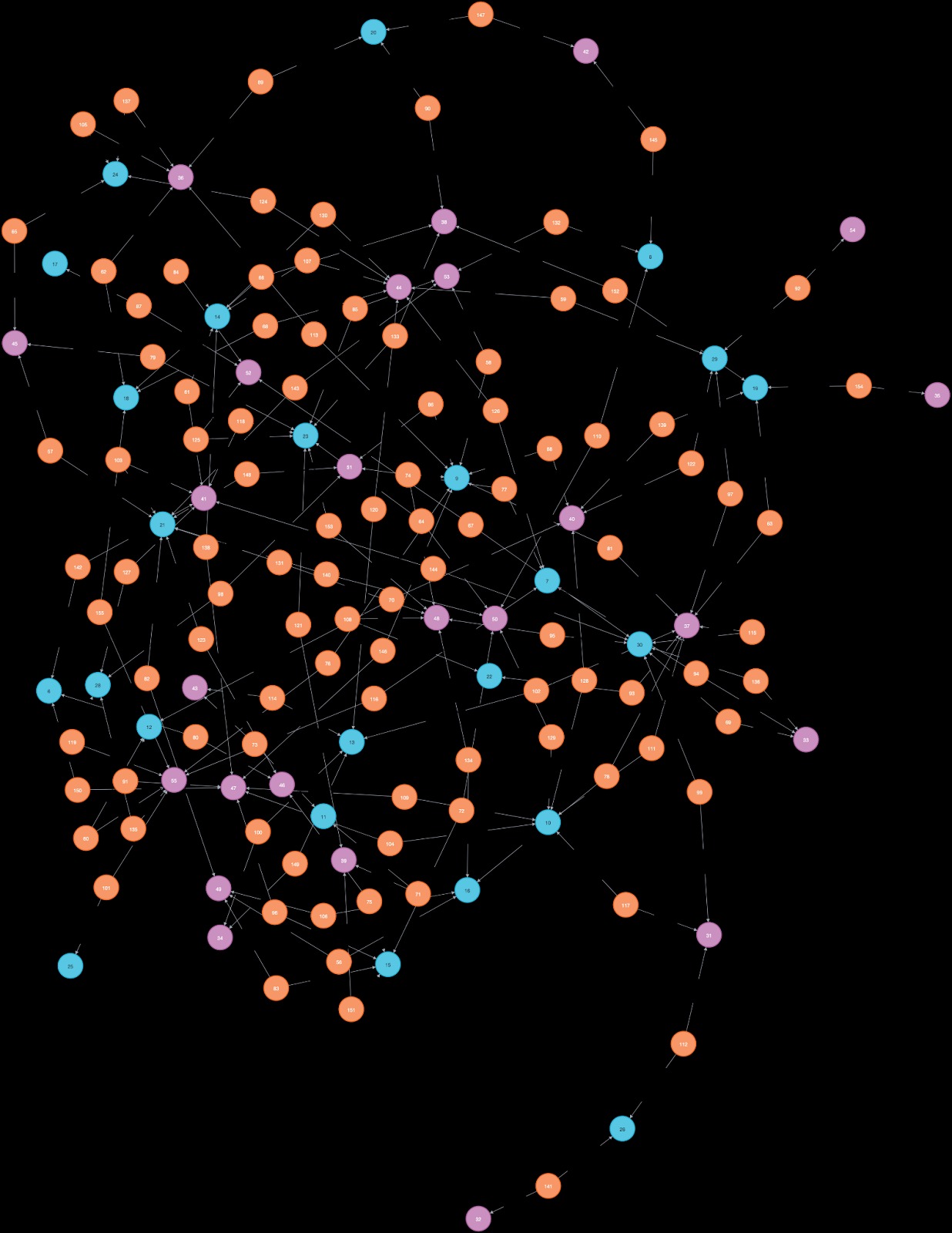
Snapshot 7: Neo4j entities and relationships knowledge graph (data used for this use case)
Using these entities and relationships, we can now answer questions with factual proof using entity-grounded queries instead of relying completely on semantically similar context.
In order to implement this, I first created a method that produces the correct Cypher query using the provided graph schema. The following snippet shows this method.
def get_graph_chain_base():
graph = get_neo4j_graph()
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0)
schema_text = """
Graph Schema:
- (Person)-[:WORKS_AT]->(Organization)
- (Person)-[:GRADUATED_FROM]->(University)
"""
cypher_prompt = PromptTemplate(
input_variables=["question"],
template="""
You are an expert Neo4j Cypher developer.
Translate the question into a Cypher query using the provided graph schema.
Rules:
- Always return both the person name and the company name.
- If multiple people are mentioned, use a WHERE ... IN [...] clause.
- Do NOT collapse or aggregate results.
- The output must preserve which Organization or University belongs to which person.
Graph Schema:
- (Person)-[:WORKS_AT]->(Organization)
- (Person)-[:GRADUATED_FROM]->(University)
Example:
Question: Where does Alice work?
Cypher:
MATCH (p:Person)-[:WORKS_AT]->(c:Organization)
WHERE p.name = "Alice"
RETURN p.name AS person, c.name AS company
Question: {question}
Cypher:
"""
)
# GraphCypherQAChain is usually used for Natural Language -> Cypher -> Result -> Answer
# We can use it as a component.
chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
cypher_prompt=cypher_prompt,
verbose=True,
allow_dangerous_requests=True
)
return chainAs you can see, in this method, I’ve provided a prompt specific to Neo4j Cypher query generation with the graph schema created above, along with an example. There is a rule in the prompt to generate the Cypher query, which is specific to the current use case.
Finally, I created a HybridRAG using this Graph chain and the earlier Vector Retriever.
def get_hybrid_chain():
# Hybrid Strategy:
# 1. Retrieve docs from Vector Store
# 2. Retrieve info from Graph (GraphCypherQAChain)
# 3. Combine contexts
# 4. Apply guarded final answer prompt
vector_retriever = get_vector_retriever()
graph_chain = get_graph_chain_base()
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0)
def retrieve_hybrid(question):
# 1 Vector Retrieval
vector_docs = vector_retriever.invoke(question)
vector_context = "\n".join(
d.page_content for d in vector_docs
) if vector_docs else "No relevant information from vector database."
# 2 Graph Retrieval
try:
graph_response = graph_chain.invoke({"query": question})
graph_context = graph_response.get("result", "")
if not graph_context:
graph_context = "No relevant information from knowledge graph."
except Exception as e:
print(f"Graph Chain Error: {e}")
graph_context = "No relevant information from knowledge graph."
return {
"vector_context": vector_context,
"graph_context": graph_context,
"question": question
}
# Guarded Final Answer Prompt
final_prompt = ChatPromptTemplate.from_template(
"""
You are answering a factual question using the provided context.
Use ONLY the information explicitly present in the context.
Guardrails:
- If the question involves multiple entities, verify that information for ALL entities is present.
- If any entity is missing required information, explicitly state what is missing.
- Do NOT guess, infer, or assume facts not stated.
- If the answer cannot be determined, say so clearly.
Vector Database Context:
{vector_context}
Knowledge Graph Context:
{graph_context}
Question:
{question}
Answer:
"""
)
chain = (
retrieve_hybrid
| final_prompt
| llm
| StrOutputParser()
)
return chainIn this Hybrid chain method, I have a Hybrid Retriever, which retrieves docs from Vector Retriever and entities and relationships using Graph Chain. Once the combined context is generated, it creates the final prompt with this combined context and the user’s question.
I’ve added the following guardrails:
- To validate if all entities are present in the context.
- To state what is missing, if there is any entity missing.
- To not guess, infer, or assume facts if they are not stated.
- To ensure that if the answer can’t be determined from the context, it can say so.
I wrapped around his HybridRAG chain in another simple FastAPI as shown in the following snippet.
@app.post("/query/hybrid")
async def query_hybrid(request: QueryRequest):
try:
chain = get_hybrid_chain()
response = chain.invoke(request.question)
return {"answer": response}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Internal Server Error: {str(e)}")
Using this API, I conducted the same set of tests. First, with the user's query "Where do both Student1 and Student35 work?" I performed a manual query in Neo4J, including both Student entities. The following snapshot shows the filtered entities and their relationship from the knowledge graph.
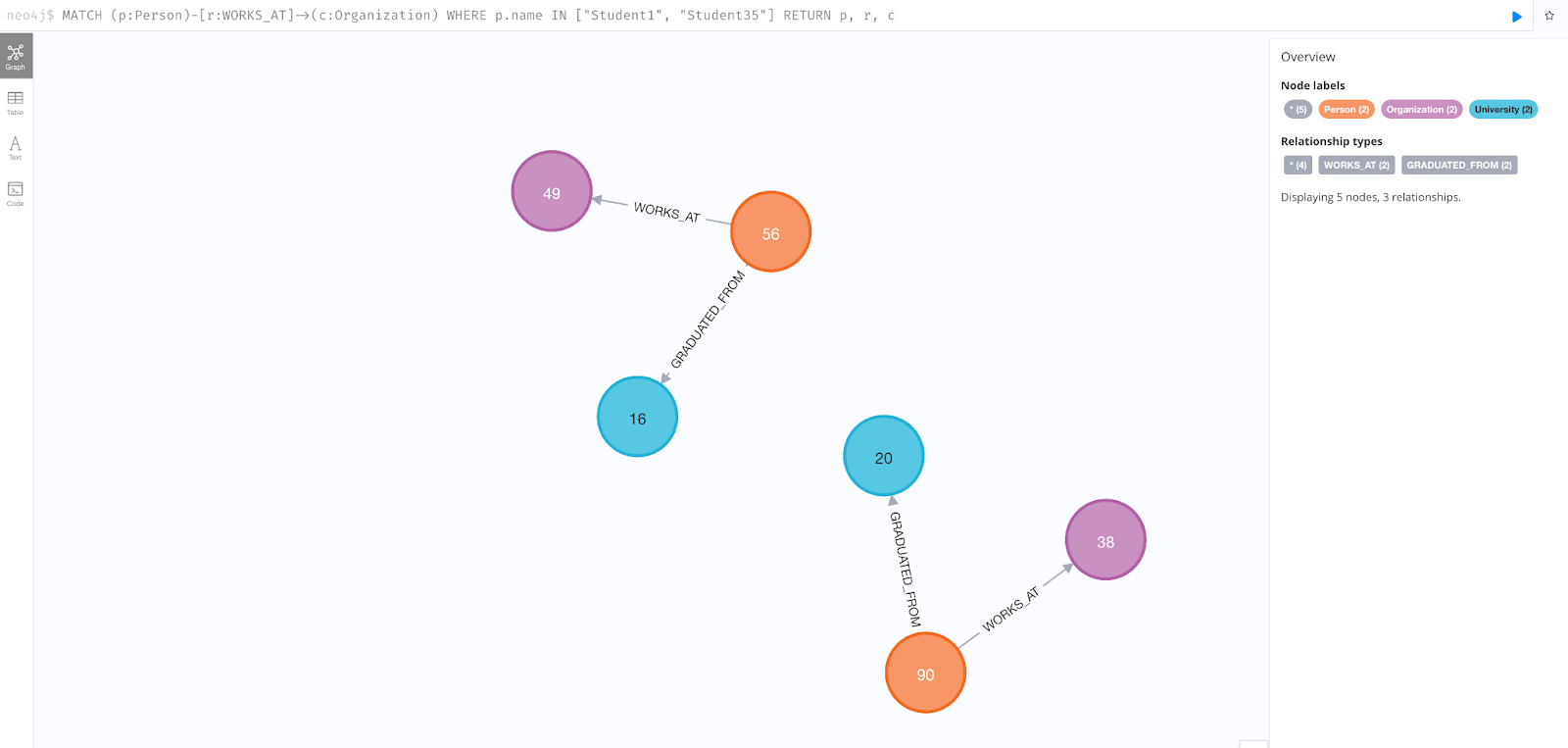
Snapshot 8: Neo4j entities and relationships for Student1 and Student35
Now, my expectation is that GraphRAG understands both Student entities and pulls the required entities with relationships. My assumption is validated with the trace in the following snapshots. This snapshot shows traces of how this user query has been used to form the Cypher query with all entities involved.
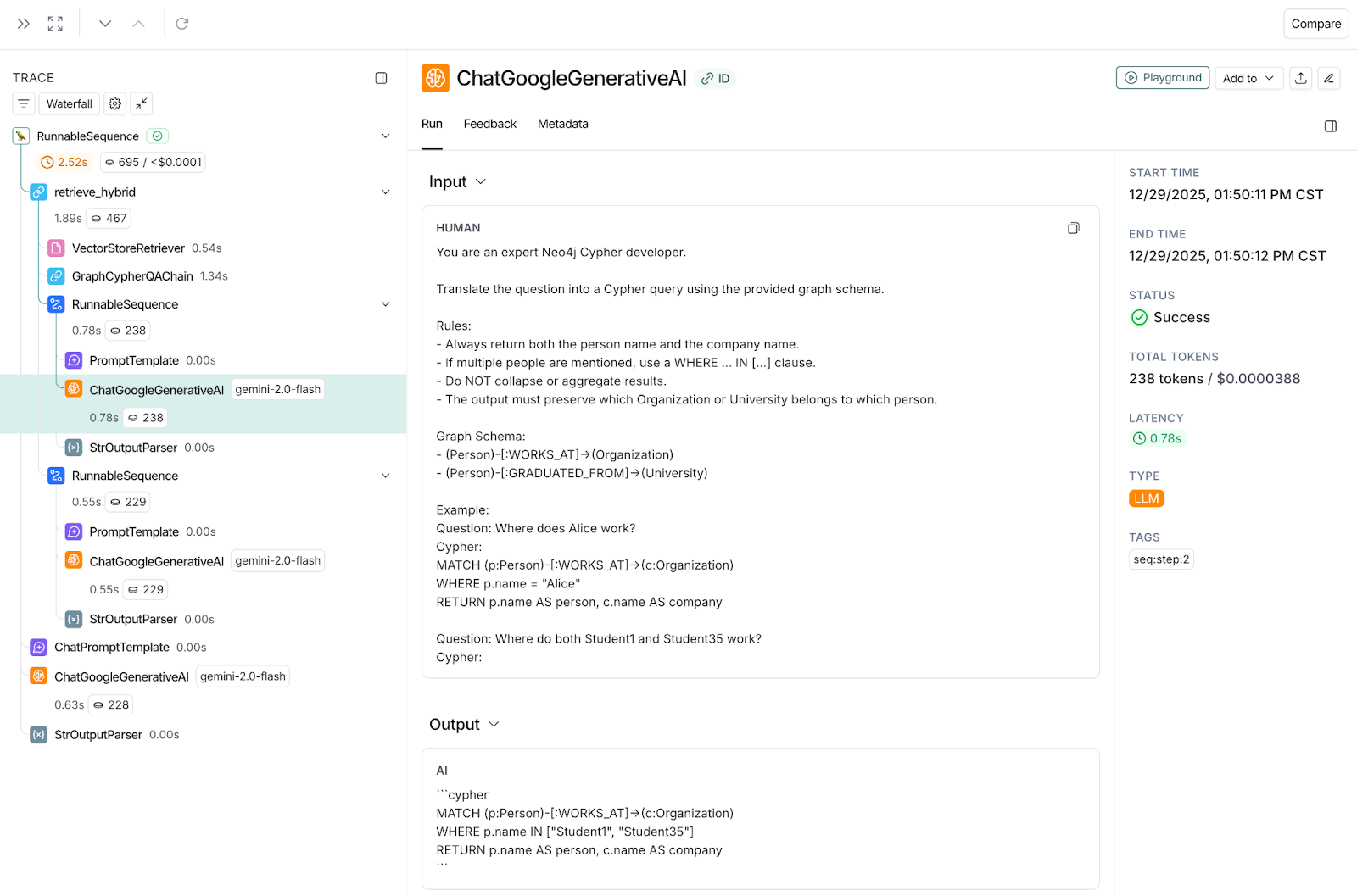
We can see in the output section of the above trace that it creates an IN clause with both entities, Student1 and Student35.
As part of the HybridRAG chain, LLM gets invoked using the final prompt, and the answer generated is complete and accurate, which is "Student35 works at Company8, and Student1 works at Company19." You can see the same in the following trace snapshot in the output section.
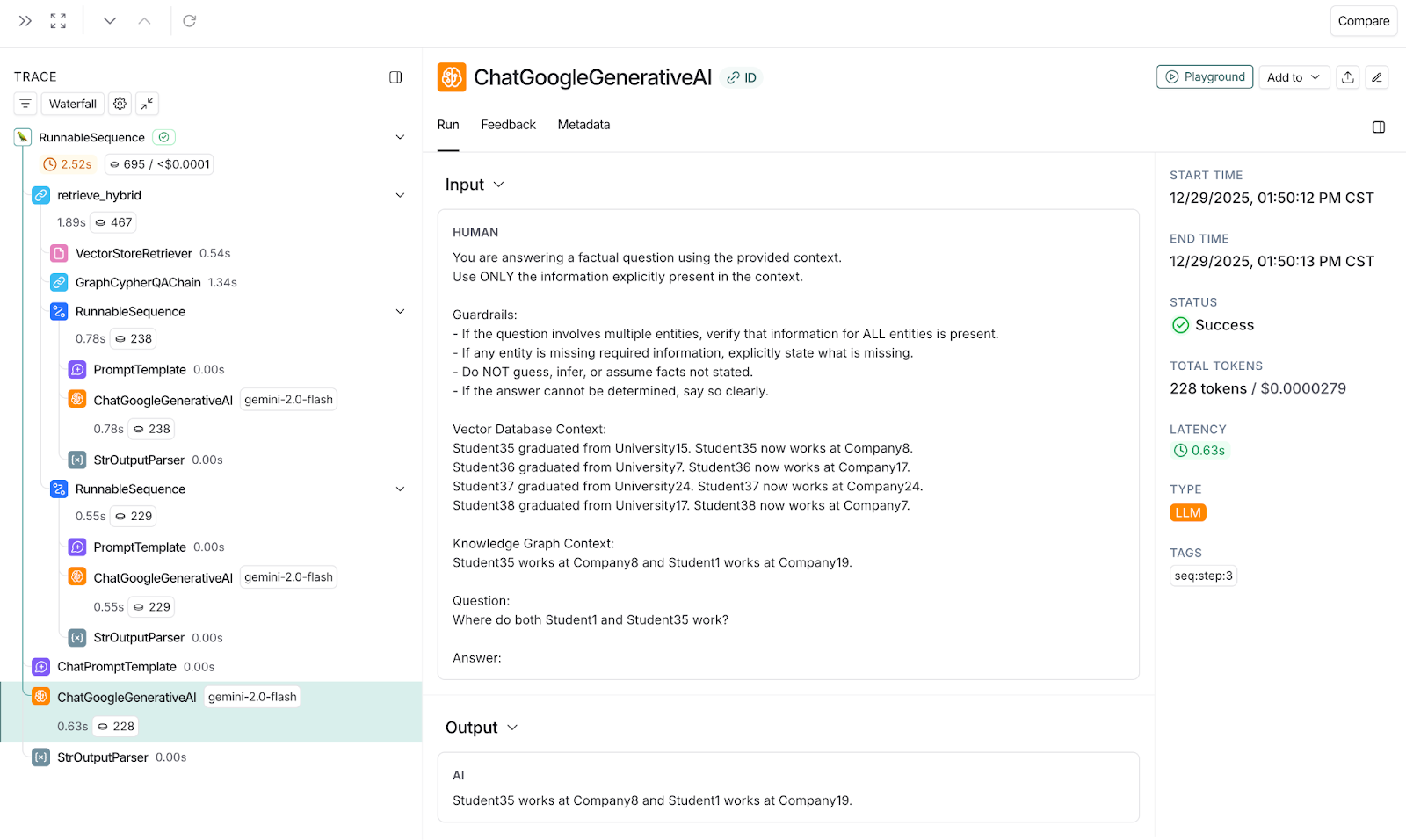 Snapshot 10: LangSmith snapshot showing traces of HybridRAG with partial Vector context and complete Knowledge Graph context, and correct output
Snapshot 10: LangSmith snapshot showing traces of HybridRAG with partial Vector context and complete Knowledge Graph context, and correct output
Let’s review how the HybridRAG performed with the second test. The user's query is "Who all Persons have graduated from the same university from where Student1 has?" Now, in order to correctly answer this, the Cypher query generated by GraphChain should find the university of Student1 using the "GRADUTED_FROM" relationship and use this university entity to find all Student entities who have the same relationship. This is possible using a join query on this Graph Schema.
Observation: The output section of the following LangSmith trace snapshot shows the generation of join Cypher query.
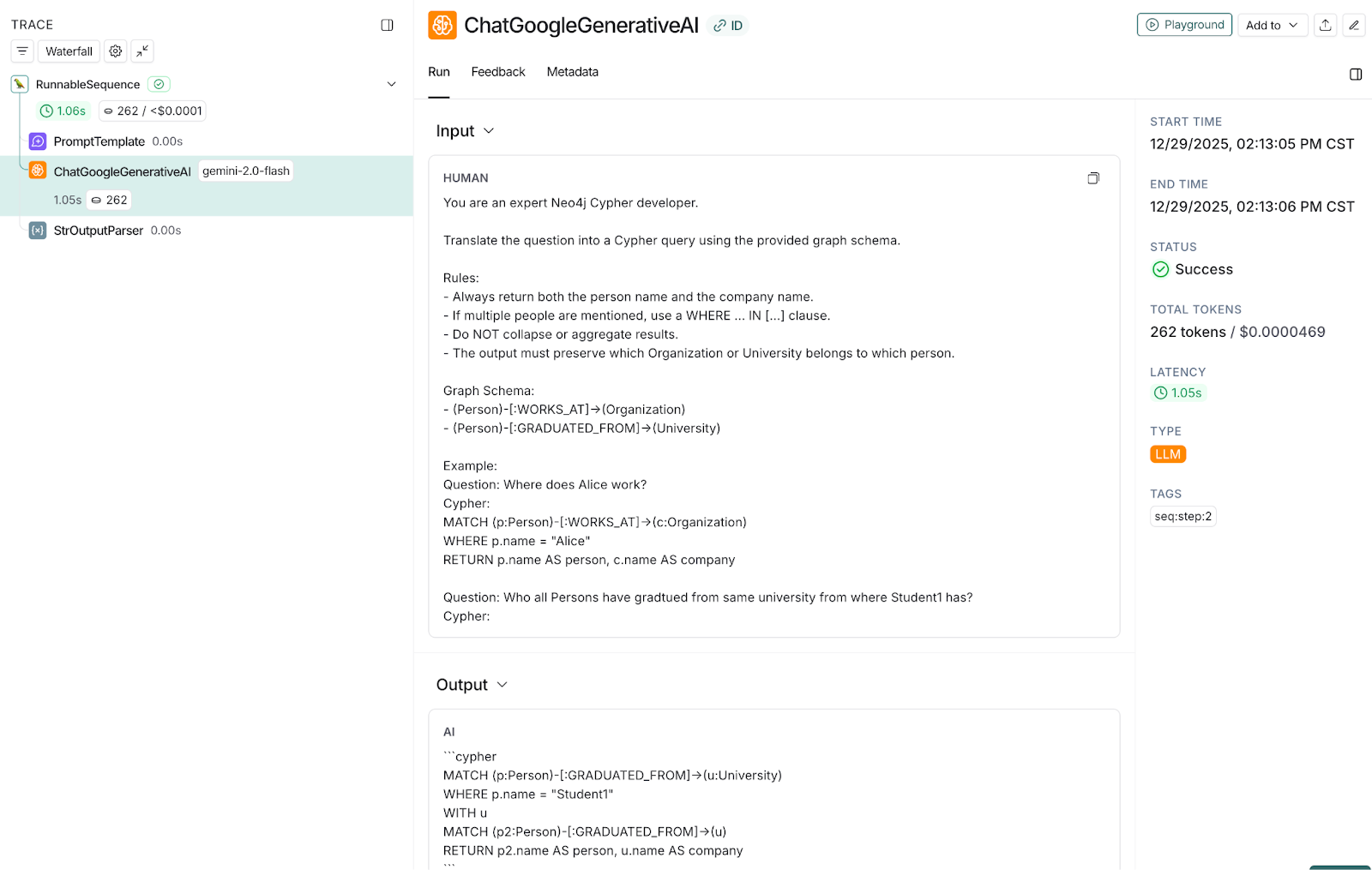
Snapshot 11: LangSmith snapshot showing traces of join Cypher query generation with correct entities and relationships
GraphCypherQAChain executes this query on the graph database and gets the result set. It further invokes the LLM to generate the answer using this result. The generated answer is: "Student51, Student79, and Student23 have graduated from the same university as Student1." The same can be seen in the following trace snapshot.
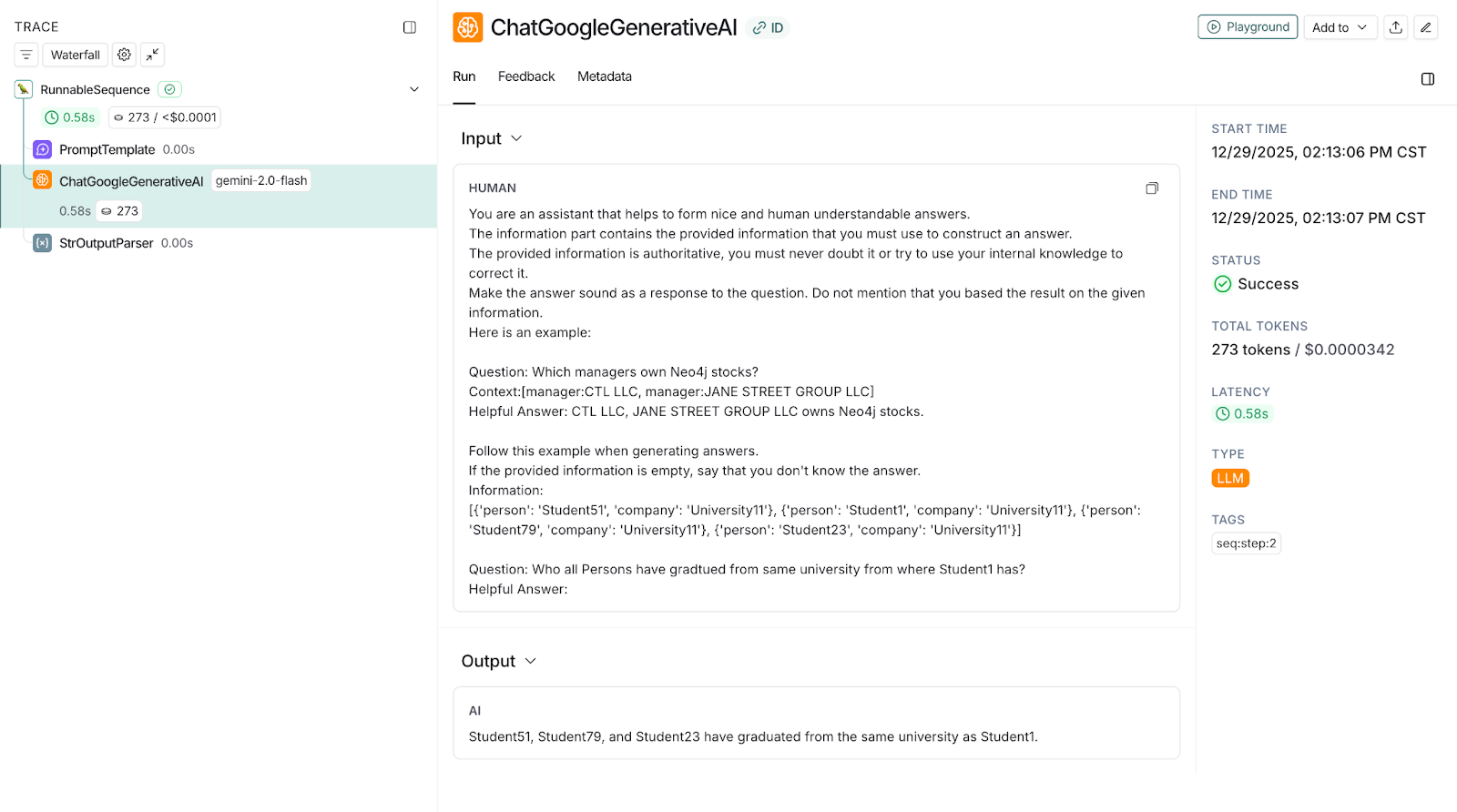 Snapshot 12: LangSmith snapshot showing traces of correct output based on the correct Graph Context fetched from the above Cypher query
Snapshot 12: LangSmith snapshot showing traces of correct output based on the correct Graph Context fetched from the above Cypher query
Observation: We can see that now the question becomes an entity-grounded query. It identifies all entities, traverses the relationships, and returns results when all entities and their relationships are resolved. The retrieval step enforces completeness before the next generation step is invoked in the chain. Guardrail restricts LLM from guessing; instead, it explains the complete context. This shift is not focused on better answer generation by LLM; instead, it's about changing the retrieval to guarantee the complete and accurate context.
Challenges With the GraphRAG
A HybridRAG, which combines vector RAG and GraphRAG, does not automatically improve accuracy. The LLM models can still hallucinate and produce incomplete answers. This happens when the Graph context is also not entity-bounded. In this case, LLM still has partial information, and it's forced to guess. This means, GraphRAG can improve accuracy only and only when entity bindings are preserved end-to-end.
The real fix is to do Entity Grounding and application of the Guardrails. To make GraphRAG reliable, the following two things are required.
- Preserve entity bindings in graph queries, and don't collapse results; always return the explicit mappings.
- Add reasoning guardrails at answer generation, which must explicitly enforce completeness of all entities in questions (as shown in Snapshot 10).
This will make the system a "trustworthy reasoning system," which is better than a "best guess generator." However, GraphRAG is not a universal fix. There are many tradeoffs that must be evaluated before applying this to your solution.
- Graph construction cost: It adds an additional ingestion activity, along with building graphs and maintaining them, which adds extra expense. Cypher query generation is an LLM call, which adds extra token consumption and cost to the overall system.
- Latency: You must evaluate the latency caused by extra steps in Cypher query generation and execution of relationship queries. This can add measurable latency, which can cause experience issues for chat or voice-based interactive systems.
- Entity extraction from a large set of unstructured content is a big challenge. This complexity becomes bigger in order to establish the right relationships between all entities. This becomes more challenging when a single relationship involves more than two entities, e.g., if a Person worked for Company1 from 2001 to 2005, and then for another company from 2005 to 2020, and so on. On top of this, the schema for classic domains is stable, but evolving domains need a change in schema quite often, which is another level of difficulty and maintenance overhead. This poses another big challenge for provenance, as the meaning of the context keeps evolving over time.
- Operational overhead: Graph database management, monitoring, quality, and observability are additional operational overheads.
These trade-offs must be weighed while making architectural decisions for your RAG system.
A Simple Capability Analysis
The following table shows the capability comparison of vector RAG and GraphRAG. We can refer to this while making the decision for a RAG system.
|
Capability
|
vector rag
|
graph rag
|
|---|---|---|
|
Single-fact retrieval |
Yes |
Yes |
|
Multi-entity recall |
No |
Yes |
|
Relationship reasoning |
No |
Yes |
|
joins |
No |
Yes |
|
Explainability |
Low |
High |
|
Hallucination resistance |
Low |
High |
Conclusion
Based on my POC, I conclude that we use vector RAG when use cases include "unstructured text," "semantic search," "fuzzy recall." This approach is effective for "synonyms and paraphrases" and "variations in natural language." It is resilient to "misspellings or noisy text" and "exploratory questions" in unstructured documents like PDFs, emails, or notes.
However, the shift towards GraphRAG or HybridRAG (combining vector RAG and GraphRAG) is quite important for trust, completeness, and accuracy. When we implement HybridRAG, with GraphRAG serving as the source of truth, system performance improves.
Opinions expressed by DZone contributors are their own.
Comments