Why AI-Generated Code Breaks Your Testing Assumptions
AI generates code faster than tests can cover. Coverage stays green while gaps grow. Treat AI code as untested by default and scale testing to match generation speed.
Join the DZone community and get the full member experience.
Join For FreeYou have an AI coding assistant open. You describe a function, it produces 40 lines of clean, well-structured code in under ten seconds, you review it briefly. It looks right, and you ship it.
That workflow is now routine for millions of developers. The speed is real. The problem is that looking right and being right are not the same thing.
AI-generated code is syntactically confident, stylistically consistent, and structurally plausible. What it lacks is the contextual judgment that comes from understanding why the code exists, not just what it should do. That gap, between code that runs and code that behaves correctly under real conditions, real data, and real dependencies, is what most development teams are not accounting for in their test strategy.
The Assumption AI Coding Breaks
Most testing workflows rest on one quiet assumption: a developer wrote the code, understands what it does, and has some mental model of where it might break. Tests are built on top of that understanding. The developer knows which edge cases to cover because they made the decisions that created those edge cases.
AI-generated code breaks that assumption entirely. The code appears without a decision-maker behind it. No one chose the edge cases. No one decided what to leave out. And yet the output looks complete, so it tends to be treated as complete — reviewed with the same confidence as hand-written code a senior developer spent hours on.
GitClear's 2025 analysis of over 150 million lines of code found that code churn (code written then reverted or replaced within two weeks) has risen sharply in AI-assisted codebases compared to pre-2021 baselines. That's a concrete proxy for low-confidence, unvalidated output reaching production. The pattern-matching risk compounds this: LLMs reproduce common code structures fluently. For standard CRUD operations and familiar API patterns, they perform well. For business-specific logic, unusual edge cases, or scenarios with no strong training equivalent, they can produce code that is subtly and silently wrong - code that passes basic review because it looks like correct code.
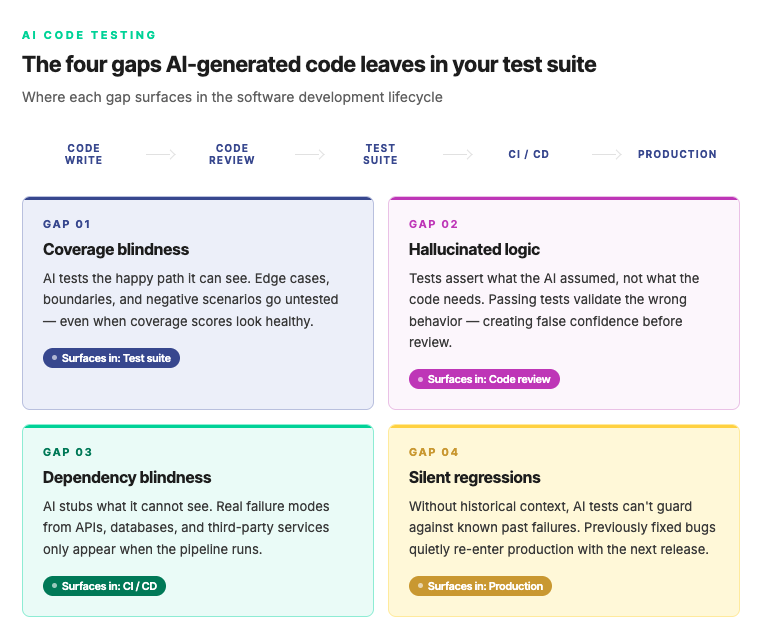
Four Gaps That Widen Simultaneously
Each of these issues exists in traditional software development. AI-generated code widens all four at the exact moment teams are moving fastest.
Coverage blindness: Your test suite reflects the code paths you anticipated when you wrote those tests. When AI generates a new function, branch, or error condition, your existing tests have no knowledge of it, and your coverage report will not tell you that, because coverage is measured against the tests you wrote, not against all possible behavior. The report stays green. The gap is invisible.
Hallucinated logic: LLMs occasionally generate plausible but incorrect logic, particularly for business-specific rules with no strong equivalent in publicly available training data. The code compiles, the syntax is clean, and a quick review does not surface the problem because the structure looks right. Only a test that directly exercises the actual business rule will catch it.
Dependency blindness: AI generates code based on your prompt, not your production environment. It has no awareness of the services, APIs, data contracts, or downstream consumers that generated code will interact with at runtime. Integration points are where this surfaces, and integration testing is consistently the layer teams under-invest in, especially when shipping fast.
Silent regressions: When AI tools modify existing functions, they can subtly alter behavior that other parts of the system depend on. Unit tests covering the function in isolation will still pass. The regression only surfaces at integration or end-to-end test level, often well after the change has been merged and the original context is gone.
The Validation Gap
There is a useful name for what is happening here: the validation gap. It is the space between code that passes existing automated tests and code that actually behaves correctly in production. It has always existed. AI-generated code makes it wider and harder to see.
Three dimensions make this concrete.
Coverage asymmetry is the most immediate. Your test suite reflects anticipated code paths. AI-generated code does not know what tests exist. It generates new paths, new branches, new conditions, and your coverage tooling has no knowledge of any of them.
Confidence miscalibration is subtler but equally important. Developers consistently report reviewing AI-generated code less rigorously than equivalent hand-written code. The fluency and formatting of LLM output creates an impression of completeness that hand-written code does not carry in the same way. This is a predictable response to a new kind of stimulus, but the consequence is that AI-generated code gets less scrutiny precisely because it looks more finished.
Brittleness under integration is where the practical damage tends to surface. AI-generated functions frequently work correctly in isolation and break at integration points. Unit tests do not catch this. End-to-end and integration test coverage is the most exposed layer, and also the most likely to be de-prioritized under shipping pressure.
Why Manual Testing Cannot Keep Pace
If AI is introducing new complexity into codebases faster than humans can manually design tests for it, then testing intelligence needs to operate at the same speed and scale as code generation. This is not a philosophical argument: it is a practical one. The math does not work otherwise.
Four capabilities define what AI-powered testing brings to close the gap:
AI-assisted test case generation analyzes newly generated code, infers intended behavior from context, and suggests test cases covering likely failure points, including edge cases a quick review would miss. Tests generated at the same pace as code.
Intelligent coverage analysis scans new functions, identifies untested code paths, and surfaces gaps before code reaches the CI pipeline. Tests are not just run against existing coverage: they are evaluated against what the new code actually does.
Self-healing test maintenance addresses the breakage that comes from rapid iteration. As AI-generated code evolves, locators and assertions break. Self-healing tests adapt automatically, keeping coverage viable at development pace rather than creating a maintenance bottleneck.
Behavioral validation is the most important distinction. AI-powered testing focuses on whether code behaves correctly under real conditions, not just whether it compiles or passes linting. Static tools catch structural problems. Behavioral testing catches logic problems. The validation gap lives in the logic layer.
What to Do Right Now
The most useful immediate step is a mindset shift before a tooling change. When using AI coding assistants, treat every generated function as untested by default, regardless of how confident or complete the output looks. The review step is not optional. It is part of the generation workflow, not a gate after it.
From there, the practical audit is straightforward: which parts of your current codebase are AI-generated, and what specific test coverage exists for those functions? Most teams that ask this question find they have no clear answer. AI-generated code tends to be assumed covered rather than verified covered.
The next question is whether test generation is keeping pace with code generation. If your team is using Copilot, Cursor, or similar tools daily and writing tests manually, the deficit compounds with every sprint. The velocity gap between code generation and test creation is where quality debt accumulates fastest.
For teams already using test automation platforms: ensure AI-generated functions are explicitly included in coverage reporting, not assumed to be covered by tests that predate them. For teams evaluating AI testing tools: the two questions that matter most are whether the tool analyzes new code specifically for coverage gaps, and whether it operates at the same speed as code generation. A testing tool that requires more time to configure than the code took to generate solves the wrong problem. Platforms like Katalon are building toward this, analyzing new code for coverage gaps as part of the standard workflow rather than as a separate audit step.
The Bigger Picture
The productivity gains from AI coding tools are real, measurable, and not going away. The validation gap they create is equally real, less visible, and growing with every sprint that ships AI-generated code without proportional testing underneath it.
Speed without validation is not a productivity gain. It is a deferred defect.
The answer is not to slow down. It is to match the intelligence of your testing to the intelligence of your code generation. Developers who close the validation gap early, treating AI-generated code as untested by default and building AI-aware testing into the same workflow, maintain the speed advantage without accumulating the quality debt that eventually catches up with teams that do not.
The gap does not disappear because the tests pass. It surfaces later, in production incidents, integration failures, and the slow erosion of confidence in a codebase that nobody fully understands anymore.
Published at DZone with permission of Oliver Howard. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments