Why Building an External Data Product Is So Hard
Developing an external data product is different and, let's face it, more complex than serving internal customers.
Join the DZone community and get the full member experience.
Join For FreeDeveloping internal data products–whether a high-powered executive dashboard, a machine learning-powered predictive buyer model for marketing, or a new customer model for the BI team–is still one of the most powerful ways data teams can add value to the organization.
But developing an external data product is a cut above: both in value-added and in the level of difficulty. It’s a different motion that requires your team to build new muscle memory.
It’s a new way of thinking and requires elevated levels of coordination, discipline, and rigor.
That isn’t to say it can’t be done by the same team, or that your internal data consumers can’t receive the same level of service as your external customers.
Noah Abramson, the data engineering manager at Toast, a point of sale provider for restaurants, recently talked about their experience doing just that.
One of our big value ads is giving business insights to our customers: restaurants. How did they do over time? How much were their sales yesterday? Who is their top customer?
It’s the data platform team’s job to engage with our restaurant customers…We say our customers are all Toast employees. We try to enable all of them with as much data as possible. Our team services all internal data requests from product to go-to-market to customer support to hardware operations.”
I’ve also been fortunate enough to have the opportunities to build internal data products in past roles in addition to external data products within our data observability platform at Monte Carlo.
In this post, we’ll reflect on those experiences and cover how data teams can successfully launch an external data product by understanding the 5 key dimensions that are different from building internal products, including:
- Architecture
- User expectations
- ROI
- Self-Service
- Iterations
But first, it’s important to understand exactly what an external data product or data application is, and how the type of application you develop will guide many of your decision points.
What Is an External Data Product? What Are Some Data Application Examples and How Do They Shape Your Decision-Making?
An external data product is any data asset that either faces or impacts a customer. That can range from a dataset that is used in the customer billing process to a completely separate data-intensive application with its own UI providing insights to a customer.
One of the hottest trends in data right now involves companies creating data applications or adding an additional layer within their SaaS product to help customers analyze their data, like the previously mentioned Toast example.
Snowflake has a helpful list of five common types of data applications (complete with reference architectures):
- Customer 360: Marketing or sales automation that requires a complete view of the customer relationship.
- IoT: Near real-time analysis of large volumes of time-series data from IoT devices and sensors.
- Application health and security analytics: Identification of potential security threats and monitoring of application health through analysis of large volumes of log data.
- Machine learning (ML) and data science: Training and deployment of machine learning models in order to build predictive applications, such as recommendation engines.
- Embedded analytics: Branded analysis and visualizations delivered within an app.
However, an external data product doesn’t necessarily need to be a fully built-out application or integrate within the main SaaS offering. For example, Monte Carlo crosses the spectrum.
We are a data-intensive SaaS application that monitors, alerts, and provides lineage within our own UI. We also provide insights reports back to customers within our UI as well as providing them the option to surface it within their own Snowflake environment using the Snowflake data share integration.
In this latter case, we’re just providing the building blocks for customers to be able to further customize how they’d like to visualize or combine it with other data.
It’s important to have an expansive view of what is a data application or external data product because this should trigger the team to ensure it’s given a heightened level of rigor and it’s better to err on the side of over vs under engineering.
It’s important to ask:
- What external data products do we have and what types are they?
- Who are they serving? What are the use cases?
- Are they meeting those expectations? How are we measuring that?
- Do we have the right tools and processes in place?
It’s also important to evaluate external data products across the following five dimensions. Starting with…
Architecture
External data products, like internal products, can leverage a wide variety of data cloud services to serve as the foundation of their platform including data lakes or warehouses.
Many however will leverage a solution like Snowflake for its ability to optimize how relational data can be stored and queried at scale. Nothing new there.
What is new is that this will likely be your team’s first discussion about multi-tenant architectures. That is a big change and decision point when serving external customers.
When leveraging a data warehouse as the product’s foundation, there are three multi-tenant design options that Snowflake describes as:
- Multi-tenant table: Centralizes tenants in single, shared objects to enable tenants to share compute and other resources efficiently.
- Object per tenant: Isolates tenants into separate tables, schemas, databases, and warehouses within the same account.
- Account per tenant: Isolates tenants into separate Snowflake accounts.
Each option has advantages and disadvantages, but in an oversimplified nutshell, it depends on what needs to scale more efficiently–the shared compute/storage or role-based access to data.

Most internal products are delivered within the same corporate umbrella with the same broad internal policies and regulations. The marketing team isn’t going to be upset if its data assets are in the same warehouse as the legal teams for instance. External customers may care quite a bit more.
Of course, you can make other architecture choices across your stack to mitigate these trade-offs.
For example, Monte Carlo leverages an MTT multi-tenant architecture in Snowflake that logically separates customer data using industry best practices such as tokenization. Additionally, we use a hybrid architecture with a data collector that is embedded within the customers’ environment (often but not always as its own virtual private cloud).
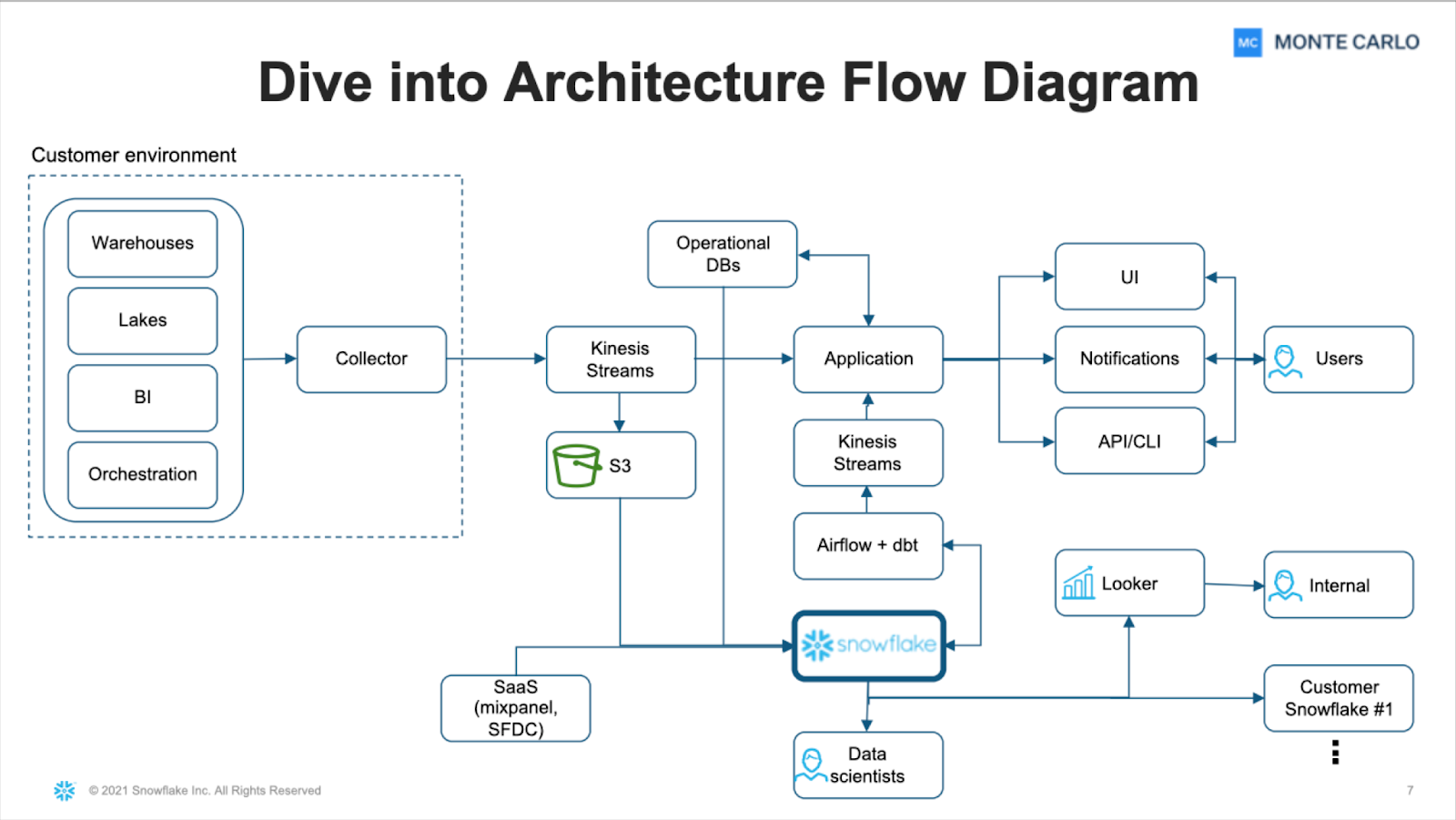
That means data never leaves its environment. PII and sensitive data are abstracted away and what we pull are the non-sensitive logs, and metric aggregations needed to assess their data systems’ health.
Another part of the architecture decision-making process, similar to internal data products, is understanding the use cases and workloads. What are the frequency, size, and required timelines? Will customers receive data at a set time, be able to query data on-demand, access it in real-time, or all three?
As we have mentioned previously, understanding workloads is very helpful for making cost-effective architectural choices. What is different with external products, however, is there may be a wider variety of use cases to support.
In architecting Monte Carlo, we didn’t just have to consider our mission-critical production workloads, but how our internal teams accessed this external-facing data as well. In this case, to conduct internal analytics and data science research as part of developing our machine learning-powered anomaly monitors.
User expectations
Let’s say you have a data product that your user can usually trust to help answer some of their questions. The data is refreshed every day and the dashboard has some clickable elements where they can drill in for a more granular examination of the details.
That might be enough for some internal users. They can get their job done and their performance has even improved from when they didn’t have access to your slick dashboards.
On the other hand, your external users are pissed. They want to trust your product implicitly and have it answer all of their questions, all of the time, and in real-time.
And why shouldn’t they be upset? After all, they are paying for your product and they could have gone with a competitor.
When data is the product, data quality is product quality.
This simple fact is why some of the most enthusiastic adopters of our data observability platform are leveraging it to support their data applications.
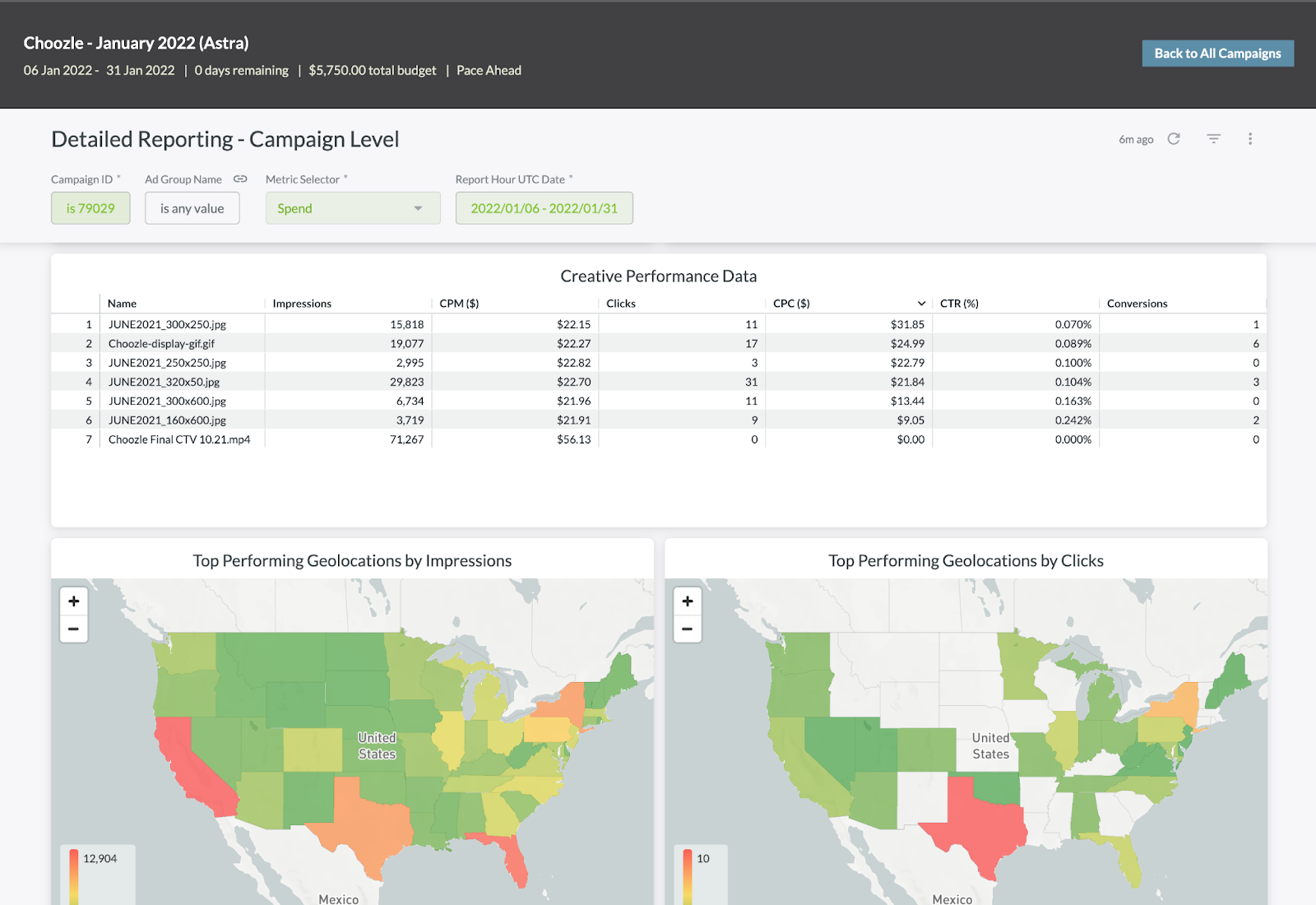
For example, multi-channel digital advertising provider Choozle, adopted data observability as it was launching a massive platform upgrade to best-in-class data reliability.
Without a tool like this, we might have monitoring coverage on final resulting tables, but that can hide a lot of issues,” said Adam Woods, chief technology officer, Choozle. “You might not see something pertaining to a small fraction of the tens of thousands of campaigns in that table, but the advertiser running that campaign is going to see it. With [data observability] we are at a level where we don’t have to compromise. We can have to alert on all of our 3,500 tables.
When data is customer-facing or powering customer-facing applications, poor quality can even break the product. For example, a data issue involving applications creating duplicate objects with the same primary key actually created an outage at Netflix.
In regards to scale and speed, external customers never want to wait on the data and they want more data dimensions so they can slice and splice to their heart’s content.
For example, one of our financial services customers has not just been focused on data freshness, but on data latency, or in other words the ability to load and update data in near real-time while also supporting queries.
Snowflake data sharing and Snowpipe can be helpful means to reduce data latency. Blackboard solved their latency challenges and enabled ETL workloads to run up to 400 times faster than before by loading data continuously with Snowpipe and bulk loading from S3.
Scaling data dimensions can also help differentiate. To use Choozle as an example once again, according to Adam for their upgraded platform:
Snowflake gave us the ability to have all of the information available to our users. For example, we could show campaign performance across the top 20 zip codes and now advertisers can access data across all 30,000 zip codes in the US if they want it.
ROI
The vast majority of data teams are not evaluated against a hard return on investment. In fact, ironically, metrics are often lacking when it comes to performance as was initially the case at Red Ventures according to Brandon Beidel, the director of product management, data platform.
The next layer is measuring performance. How well are the systems performing? If there are tons of issues, then maybe we aren’t building our system in an effective way. Or, it could tell us where to optimize our time and resources…Having a record also evolved the evaluations of our data team from a feeling, ‘I feel the team is/isn’t doing well,’ to something more evidence-based.
Internal data products are the same way. Oftentimes wins are captured ad-hoc, “Our return on ad spend has increased 3x as a result of our new customer data platform,” versus systematically measured against the cost of production or the cost per user.
That luxury disappears when you build an external data product. Product managers need to understand how to price it, and it must be profitable (at some point). They will need to know the start-up costs for building the product as well as how much each component costs in providing the service (cost of goods).
This can be challenging for data teams that haven’t had the pleasure of building internal chargeback models for their data products that can differentiate, track, and charge customers according to the scale of use.
Self-Service
“A-ha!” you say. “Our team already allows our internal consumers to self-service, this is nothing new.” That may be true, but the bar has been raised for self-service and usability too.
Your external customers can’t Slack you to ask questions about the data or how you derived this customer’s likelihood to churn was, “3.5 out of 5 frowny faces.” The data product can’t be a black box–you need to show your work.

The UI has to be intuitive, the relevancy has to be immediate, and the context has to be evident.
Iterations
When you build your internal data products, it’s often slow going at first as you gather requirements, build, and iterate with business stakeholders.
After that, teams are often off and running to the next project. There will be patches and fixes for data downtime or maybe to meet internal SLAs if you’re fancy, but on the whole, you aren’t refactoring those dashboards every quarter.
As previously mentioned, paying customers have higher expectations and they also have a lot more feedback. You need to know it’s coming and build for it, however.
For example, Toast is extremely focused on the efficiency of its processes.
Not only do we listen to the business needs and obviously support them, but we also look internally and address scalability,” said Toast data engineer Angie Delatorre. “If a job used to take one hour, and now it takes three hours, we always need to go back and look at those instances, so that shapes our OKRs as well.
When it comes to scaling operations, Snowflake director of product management Chris Child recommends,
First, get all of your data in one place with the highest fidelity. Just get the raw data in there. Second, come up with repeatable pipelines for getting data to your analysts. You don’t want to go back to the raw data every time you want to do something.
Former Uber data product manager Atul Gupte has discussed how critical it is when iterating data products to understand,
How to prioritize your product roadmap, as well as who you need to build for (often, the engineers) versus design for (the day-to-day platform users, including analysts).
Ship It
While this blog may have read like a list of reasons why you shouldn’t build an external data product, I hope it helps demystify the challenges associated with this daunting but worthwhile endeavor.
You will not build the perfect external data application on the first sprint (no one does), but I encourage you to build, ship, iterate, rinse, and repeat.
Published at DZone with permission of Lior Gavish. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments