Why DevOps Should Own Their Databases and How To Do It
It took us nearly 20 years to finally formulate the state of DevOps and bridge development and operations. However, we need to take another step to own the databases.
Join the DZone community and get the full member experience.
Join For FreeDevOps is not new. Ideas to combine deployment and operations began to appear in the late 80s. It took us nearly 20 years to finally formulate the state of DevOps and begin the move towards DevOps engineers. However, we can’t stop here. While it may sound surprising, there is much more to be done than what we already did. Bringing deployments and operations together is just the first step, and we need to bring other areas together even more. Let’s see what exactly.
What We Have and What We Lack
We went through a big transformation in recent decades. We moved from monolithic applications to microservices. We deploy changes many times a day, and we use multiple platforms together. The database complexity increased tremendously. We now have many databases, both SQL and NoSQL, and specific solutions for domains like machine learning. We can’t manage our databases the same way we did fifteen years ago. Even though we merged development and deployment, there are other aspects that we have disregarded until now. Some of them get bigger traction, such as DevSecOps (bringing security into the process) or ML Ops (bringing research and development together). However, we still lack good database ops solutions. Databases are still terra incognita for developers. They don’t manage them, they don’t optimize them, and they don’t know how to monitor and tune them efficiently. This is a gap that we need to address immediately. Read on to understand why.
Why DevOps in Databases Is Important
Many things can go wrong when working with databases. Let’s see some of the areas that can break and how our current industry deals with them.
Code Changes
Many database issues come from the code changes. Developers change their applications, bring in new data, or implement new quests, and this breaks databases. Some of these changes can be verified automatically with our existing CI/CD pipelines and automated tests. However, performance issues have not been verified in any way. Lack of indexes, suboptimal queries, weird ORM mappings — all these things result in slow performance that our tests won’t capture. Our tests focus on data correctness — they verify if entries are read and written properly. They don’t verify if we extracted them most optimally or if we used indexes.
Many things that may break. We may use N+1 queries due to ORM lazy loading. We may rewrite our query to use CTEs that are slower than regular queries. We may miss an index or not use it because of wrong filtering. The point is that these issues go unnoticed because developers don’t have good tools to identify them. Developers focus on correctness and disregard performance. The latter is checked only in production.
Schema Changes
There are many ways to modify the schema: we can add something (table, index, column, etc.), we can remove something (drop a table, etc.), and we can modify something (change column’s type or name, etc.). All these aspects are risky because they happen outside of developers’ workflow.
Typically, automated tests are run against the modified schema. They verify the correctness of the data only after the schema is modified. Specifically, they don’t try running against the broken schema (old version of schema) or against the database that is currently being modified. If there are issues with any of these, then the automated tests won’t capture them. This is a problem in heterogeneous environments because there are many different applications that talk to the same database and may break due to inconsistent expectations.
Yet another issue is the performance of schema migrations. Adding a column may take a long time if the database engine decides to rewrite the table. This means that the engine needs to copy the data on the side, drop and recreate the table, and then copy the data back. This may take minutes or even hours to complete. Some sophisticated schema migrations may even take months and need to be carefully planned in advance.
When issues like those mentioned above occur, developers are rarely involved in the troubleshooting. They are not exposed to these issues because they manifest themselves only in the production database. Operations teams and database administrators are the first to learn about the issues and they are the first to debug them.
Execution Changes
Yet another aspect of databases is that they live and evolve. They deal with bigger and bigger volumes of data whereas automated tests do not increase the data quantity. Our unit tests clear the database, preload some well-known objects, and then verify if queries work correctly. They don’t test with more and more data stored in the database. Instead, they always see the database in the same way.
However, the production database doesn’t work like that. We store more data over time than we need to handle. We need to maintain indexes, fragmentation, vacuuming, storage, partitioning, and sharding, just to name a few. The problem arises when the application sends the same query over and over again that, at some point, starts to execute differently. This may be caused by outdated statistics, changed configuration, or index being disregarded by the database engine. Again, developers won’t see the issue as they focus on the data correctness. However, the performance in production will plummet for seemingly no reason.
We can protect ourselves from these issues with load tests. However, load tests do not use the production database (so there may be differences in configuration), and they happen very late in the pipeline. We know that the cost of fixing the bug increases with time. It’s important to identify issues as early as possible to fix them efficiently. Load tests are not suitable for that.
Fixing Issues Is Inefficient
Based on what we wrote above, we see that we don’t have good ways to prevent the issues from appearing in production. Therefore, we have very little time to fix them when they appear as they affect our end users. This increases our stress and makes us take risky actions.
Since developers are not the first team to be involved in troubleshooting the issues, we also face communication challenges. Developers don’t own their databases but they are crucial to understand what happened as they own the deployments. This leads to the creation of war rooms or other bridge calls that involve many parties and are known to be inefficient. Especially if it’s unclear who owns the code that caused the problems.
We learned that DevOps is efficient because it minimizes the cost of communication. We have teams working hand in hand together or even DevOps engineers who can handle issues on their own. We lack that in the area of database management. Read on to see how to fix that and what we need.
Enhancing Service Ownership in Databases
What we need is true ownership of databases. Developers need to own their databases the same way they own their code and deployments. Developers need to be able to self-serve issues with performance, maintenance, monitoring, and other aspects of the databases.
There are three things that developers and DevOps engineers need to own their databases:
- Database observability is built with tools that focus on databases instead of focusing on raw signals
- Processes that define well how to use the database observability tools and what to do in case of issues
- The mindset of the owners empowers developers to lead the way
Let’s now examine each of these in detail.
Owning Databases With Database Observability
Developers need to be able to debug their databases. Just like they can debug their source code, they need to have insights into database performance. However, they can’t just see the raw metrics like CPU or memory used. They need to have database-oriented metrics showing the usage of indexes, buffers, transactions, locks, and other constructs of the databases.
Additionally, these tools need to provide an understanding and coherent story. They need to show that the CPU spikes because some queries stopped using an index that was used before. The tools need to track changes coming to the database, like deployments, different data distributions, or periodic background tasks.
Having these tools, developers will be able to own their databases and won’t need to ask other teams for help.
Owning Databases With Processes
Developers need to have well-defined processes to monitor and troubleshoot their databases. Just like they are paged when there are failing endpoints in their applications, they need to have standard operating procedures to assess the performance and fix issues when they appear.
This includes reviewing database-focused metrics, tracking the usage of indexes, or understanding maintenance tasks like vacuuming or index rebuilding. This also includes getting alerts and notifications when the performance decreases. Just like developers are notified when their CI/CD pipeline is blocked, they should get an automated alert when an index is not being used anymore.
Platform Engineers must define these processes. However, developers ultimately need to own them and adjust to their needs. Over time, developers need to experiment with more tools and more processes so they can find what works for them.
Owning Databases With Mindset
Last but not least, developers need to change their mindset. We learned that DevOps bridges the gap between development, deployment, and maintenance. In the same way, we need to understand that DevOps engineers can own their databases and free DBAs and Ops teams from overseeing this area.
This is a tremendous challenge in the industry. However, this is the right time to shift left ownership and help developers take ownership in a way that is convenient and comfortable for them.
What is Shift Left in DevOps? Shift Left in DevOps is moving all the checks as early in the pipeline as possible to reduce the time needed for identifying and fixing the issues. Shifting left includes using static code analysis, testing early and often, or checking performance before even committing the code to the repository.
What To Do Next
There are three aspects that we need to work on now. First, database observability must be created. Metis is a platform that builds database guardrails and helps developers own their databases. It’s built on open standards and works with databases deployed in any way. Metis can help the business with powerful observability dashboards like the one below:
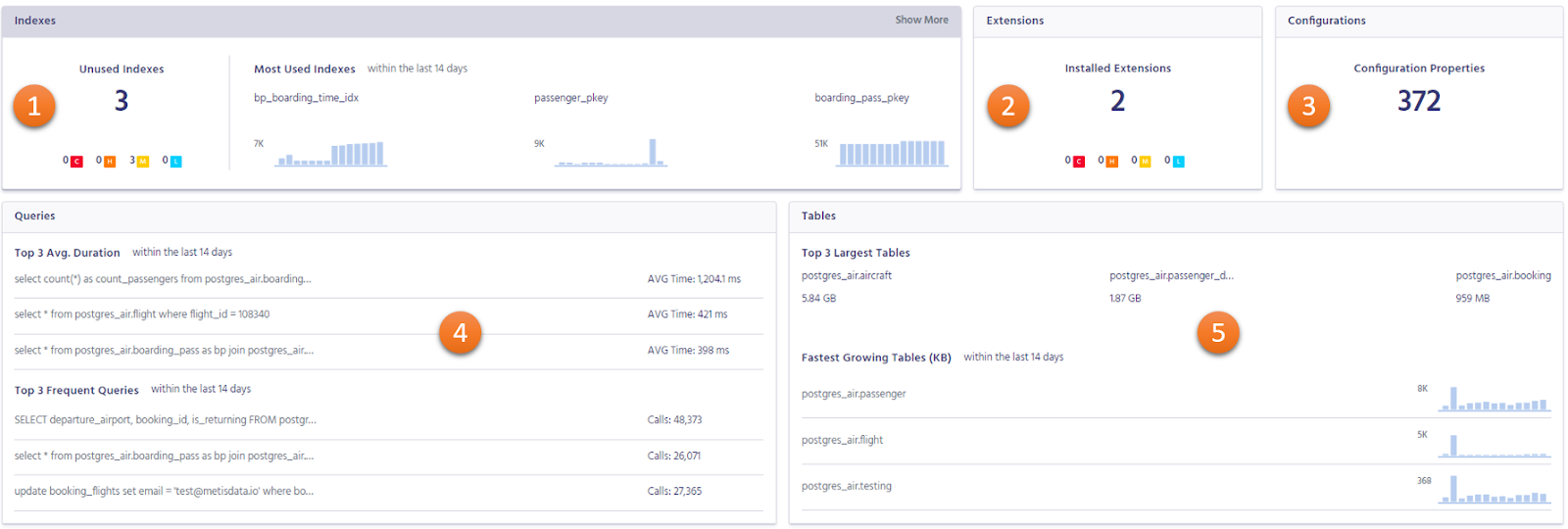
The dashboard shows insights about various parts of the database: indexes (number 1) and their usage, extensions (number 2), running configuration (number 3), query performance (number 4), and insights about tables (number 5). Instead of showing raw data, the dashboard focuses on database-related metrics and details. Similarly, Metis can show live SQL queries and their performance to immediately show where the issues are:
Second, platform engineers must use these tools to define processes. They need to transform their organizations to let developers own their solutions. This is not just a business decision. This requires a big movement in the industry, just as we reshaped our work with the DevOps movement. Metis solves this with automated flows that can indicate issues and build the proper story behind the problems. Teams can then define how they handle the alerts and fix the issues right when they are identified.
Third, DevOps engineers need to take ownership. While it may seem challenging at first, we already know that minimizing communication and owning the full scope of the system is beneficial for the business and for the engineers. We need to reform our teams, reassign responsibilities, and reorganize the departments. It will take time, but it will bring a new age to DevOps and databases. Metis brings all that developers need to change their mindset and become true owners.
Summary
It took us nearly thirty years to build proper development and deployment thanks to DevOps. Today, we need to merge more areas to bring more benefits to our business. We need to let developers own their databases by building new tools like Metis and new processes that shift the ownership to the left. Enhancing service ownership is the challenge that our industry is already committed to taking.
Published at DZone with permission of Adam Furmanek. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments