Why I'll Never Go Back to GZIP After Trying ZSTD
Faster speeds. Better compression. Facebook's ZSTD is rapidly becoming the new standard for data compression in modern applications.
Join the DZone community and get the full member experience.
Join For FreeData processing speed and efficiency matter most with big datasets. GZIP and ZLIB compressed data for years. But ZSTD often works much better now.
Let us investigate a compression experiment comparing ZSTD, GZIP, and ZLIB regarding speed, compression ratio, and decompression efficiency. By the end, you’ll see why ZSTD should be your go-to choice when compressing large data.
The Experiment Setup
For this experiment, I used a dataset consisting of JSON dictionaries that are commonly used in data transmission and API interactions. The payload size was varied to represent different scales of data compression needs.
Number of Payloads and Their Structure
I used 100,000 JSON payloads, each representing a dictionary with several nested elements. Here’s an example of a single JSON dictionary:
{
"id": "12345",
"name": "Sample Entry",
"attributes": {
"category": "example",
"tags": ["test", "sample"],
"nested": {
"level1": "data",
"level2": "more_data"
}
},
"timestamp": "2024-10-05T12:34:56Z"
}The number of payloads and the size of the JSON structure can be easily modified in the code to suit your dataset requirements. Here’s a snippet from the script used to generate the dataset:
import json
import random
from datetime import datetime
# Generate 100,000 random JSON dictionaries for testing
payloads = []
for i in range(100000):
payload = {
"id": str(i),
"name": f"Sample Entry {i}",
"attributes": {
"category": random.choice(["example", "test", "sample"]),
"tags": ["tag1", "tag2"],
"nested": {
"level1": "value1",
"level2": "value2"
}
},
"timestamp": datetime.utcnow().isoformat()
}
payloads.append(json.dumps(payload))
# This payload list is later used for compression testingYou could adjust the number of payloads by modifying the loop’s range, allowing you to test compression across various data sizes.
Compression Methods
We compared the following compression methods:
- GZIP: A well-established compression algorithm that’s often used in web applications and file compression.
- ZLIB: Another commonly used compression library that powers formats like PNG.
- ZSTD (Zstandard): ZSTD is a new compression algorithm made by Facebook. It aims for smaller compressed sizes and faster speeds than other methods. We measured how long it took to compress, how much smaller the data got, and how fast it decompressed the data.
The metrics gathered include compression time, compression ratio (i.e., how much the data was reduced in size), and decompression time.
Results and Analysis
Below is a comparison of the results from each method. This will give you a clear picture of why ZSTD outperforms the other algorithms.
Compression Metrics
GZIP: Compression Time: 21.6559 s, Compression Ratio: 1.3825, Decompression Time: 5.2070 s Standard ZSTD: Compression Time: 2.8654 s, Compression Ratio: 1.3924, Decompression Time: 2.2661 s ZSTD Streaming: Compression Time: 3.8126 s, Decompression Time: 1.6418 s ZSTD Dictionary: Compression Time: 2.6642 s, Decompression Time: 1.8132 s ZLIB: Compression Time: 18.8420 s, Compression Ratio: 1.3824, Decompression Time: 3.1688 s
Why ZSTD Is the Superior Choice
From these metrics, it’s clear that ZSTD outshines both GZIP and ZLIB in nearly every aspect:
1. ZSTD compresses data much faster than GZIP. It compresses 7-8x faster. It also decompresses 2-3x faster. This saves time when storing and retrieving data.
2. ZSTD shrinks data better than other methods. It has a higher compression ratio. This helps reduce storage costs.
3. ZSTD has different modes:
- Standard
- Streaming
- Dictionary-based
You can choose the best one for your needs. It works well for both static datasets and streaming data.
Example Code: Compressing Data Using ZSTD
Here’s a snippet showing how you can use ZSTD to compress and decompress data in Python:
import zstandard as zstd
# Compressing data using ZSTD
def compress_data(data):
compressor = zstd.ZstdCompressor()
return compressor.compress(data.encode('utf-8'))
# Decompressing data using ZSTD
def decompress_data(compressed_data):
decompressor = zstd.ZstdDecompressor()
return decompressor.decompress(compressed_data).decode('utf-8')
# Sample usage
json_data = '{"id": "1", "name": "Sample Entry", "attributes": {"category": "test"}}'
compressed = compress_data(json_data)
decompressed = decompress_data(compressed)Final Graph
Below is a visual representation of the compression times, ratios, and decompression speeds, showcasing the performance of each algorithm:
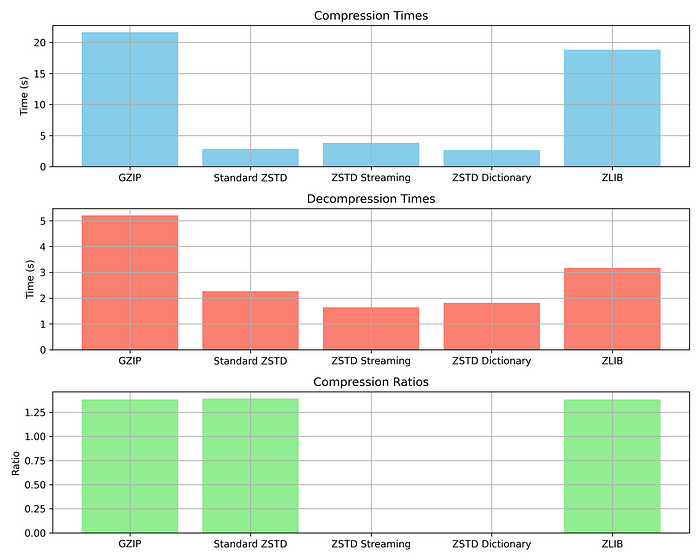
This graph highlights how ZSTD consistently outperforms both GZIP and ZLIB in all key metrics.
Conclusion
If you use GZIP or ZLIB to compress data, try ZSTD instead. ZSTD will speed up compression for large stored datasets. It also optimizes data transfer rates. ZSTD saves time, storage space, and compute resources. The performance gains are significant. Test ZSTD in your next project and see the benefits yourself!
Published at DZone with permission of Aditya Karnam Gururaj Rao. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments