Why IOPS Matters for the Database
As it turns out, if you use all your IOPS burst capacity, you end up having to get your I/O through a straw.
Join the DZone community and get the full member experience.
Join For FreeYou knew that this article had to come. After talking about memory and CPU so often, we need to talk about actual I/O.
Did I mention that the cluster was set up by a drunk monkey? That term was raised in the office today, and we had a bunch of people fighting over who the monkey was. So to clarify things, here is the monkey:

If you have any issues with this being a drunk monkey, you are likely drunk, as well. How about you set up a cluster that we can test things on?
At any rate, after setting things up and pushing the cluster, we started seeing some odd behaviors. It looked like the cluster was… acting funny.
One of the things we build into RavenDB is the ability to inspect its state easily. You can see it in the image below. In particular, you can see that we have a journal write taking 12 seconds to run.
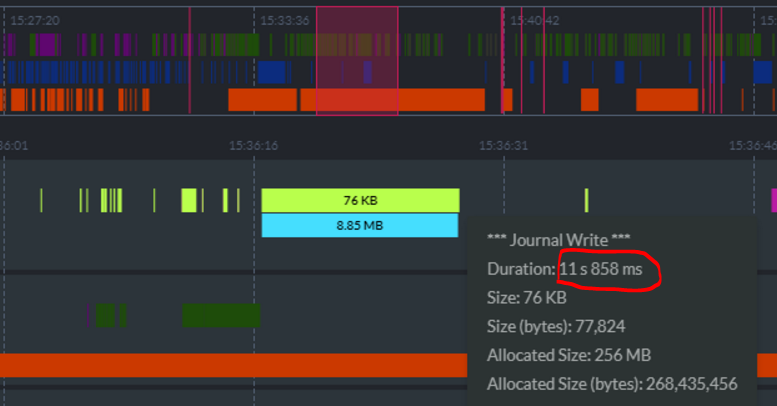
It is writing 76Kb to disk at a rate of about 6KB per second. To compare, a 1984 modem would actually be faster. What is going on? As it turns out, the IOPS on the system was left in their default state, and we had less than 200 IOPS for the disk.
Did I mention that we are throwing production traffic and some of the biggest stuff we have on this thing? As it turns out, if you use all your IOPS burst capacity, you end up having to get your I/O through a straw.
This is excellent since it exposed a convoy situation in some cases and also gave us a really valuable lesson about things we should look at when we are investigating issues (the whole point of doing this “set up by a monkey” exercise).
For the record, here is what this looks like when you do things properly:

Why does this matter, by the way?
A journal write is how RavenDB writes to the transaction journal. This is absolutely critical to ensuring that the transaction ACID properties are kept.
It also means that when we write, we must wait for the disk to OK the write before we consider it completed. And that means that there were requests somewhere that were sitting there waiting for 12 seconds for a reply because the IOPS run out.
Published at DZone with permission of Oren Eini. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments