Workarounds for Oracle Restrictions on the Size of Expression Lists
Learn five strategies to workaround ORA-01795 and ORA-00913 errors and explore a comparative analysis of their performance.
Join the DZone community and get the full member experience.
Join For FreeWhen developing an enterprise system — whether it is a completely new system or simply the addition of a new feature — it is not uncommon to need to retrieve a significant volume of records (a few hundred or even thousands) from an underlying relational database.
A usual scenario is having a list of identifiers (user IDs, for example) and needing to retrieve a set of data from each of them. Disregarding all the ease provided by Object-Relational Mappers, among which Hibernate can be underlined as a very reliable option, a straightforward way to address such a situation is to build a SQL SELECT query and bind all identifiers as a comma-delimited list of expressions in combination with a SQL IN operator. The snippet below shows the query structure.
SELECT column1, column2, ..., columnM
FROM table
WHERE identifier IN (id1, id2, id3, ..., idN)Some database management systems (DBMS), such as PostgreSQL, do not implement or define by default any restrictions on executing queries like that. Oracle, however, does not follow this policy. On the contrary, depending on the number of elements that make up the comma-delimited expression list used with the SQL IN operator or the number of records retrieved by the query, two corresponding errors may be triggered by the DBMS:
As indicated by the ORA-01795 error message, a comma-delimited list of expressions can contain no more than 1000 expressions. Then, a SQL query like described above can have up to 1,000 expressions with the IN operator.
This upper bound may vary depending on the Oracle version. For example, the limit of 1,000 expressions is present up to the Oracle 21c version. As of the 23ai version, this value has been increased to 65,535.
All tests and implementations in this article are based on the Oracle 19c version.
As mentioned in ORA-00913 documentation, this error typically occurs in two scenarios:
- When a subquery in a
WHEREorHAVINGclause returns too many columns - When a
VALUESorSELECTclause returns more columns than are listed in theINSERT
However, the ORA-00913 error also appears when SELECT queries consist of more than 65,535 hard-coded values. In the context of comma-delimited expressions, although the documentation states that "a comma-delimited list of sets of expressions can contain any number of sets, but each set can contain no more than 1000 expressions," such an upper bound is empirically verified.
Given that the ORA-01795 and the ORA-00913 errors may constitute hindrances for systems needing to fetch more records than the bounds defined by Oracle, this article presents five strategies to work around these restrictions.
As all strategies rely on hard coding SQL queries as Java Strings, two caveats about this approach are worth noting.
- Caveat 1: Chris Saxon, an Oracle Developer Advocate and active member of The Oracle Mentors (or AskTOM, for short), advised:
Do not dyamically create a statement with hard wired IN list values or OR'ed expressions. [Oracle database]'ll spend more time parsing queries than actually executing them.
- Caveat 2: According to Billy Verreynne, an Oracle APEX expert and Oracle ACE, this approach:
impacts on the amount of memory used by the Shared Pool, contributes to Shared Pool fragmentation, increases hard parsing, burns a load of CPU cycles, and degrades performance.
QSplitter
Before diving into each strategy, it is important to introduce a tool that will be used in almost all of them. It has been called QSplitter: a Java class responsible for splitting a collection into subcollections whose maximum size is also passed as a parameter. The splitCollection method returns a list in which each element is a subcollection extracted from the original collection. Its implementation is presented below.
public class QSplitter<T> {
public List<List<T>> splitCollection(Collection<T> collection, int maxCollectionSize) {
var collectionArray = collection.toArray();
var splitCollection = new ArrayList<List<T>>();
var partitions = (collection.size() / maxCollectionSize)
+ (collection.size() % maxCollectionSize == 0 ? 0 : 1);
Spliterator<T>[] spliterators = new Spliterator[partitions];
IntStream.range(0, partitions).forEach(n -> {
var fromIndex = n * maxCollectionSize;
var toIndex = fromIndex + maxCollectionSize > collection.size()
? fromIndex + collection.size() % maxCollectionSize
: fromIndex + maxCollectionSize;
spliterators[n] = Spliterators
.spliterator(collectionArray, fromIndex, toIndex, Spliterator.SIZED);
splitCollection.add(new ArrayList<>());
});
IntStream.range(0, partitions)
.forEach(n -> spliterators[n].forEachRemaining(splitCollection.get(n)::add));
return splitCollection;
}
}Another element to describe is the database used for testing. Only one table was created and the SQL code used is shown below.
CREATE TABLE employee (
ID NUMBER GENERATED ALWAYS as IDENTITY(START with 1 INCREMENT by 1),
NAME VARCHAR2(500),
EMAIL VARCHAR2(500),
STREET_NAME VARCHAR2(500),
CITY VARCHAR2(500),
COUNTRY VARCHAR2(500));
CREATE UNIQUE INDEX PK_EMPLOYEE ON EMPLOYEE ("ID");1. N Query Strategy
The first strategy is the simplest: split the collection of IDs into subcollections, considering Oracle's upper limit (L = 1,000) for the comma-delimited list of expressions. Each subcollection is then used to build a query that fetches the corresponding subset of all desired records. The next script illustrates the generic queries generated for a collection of 3,000 IDs.
- Note: This strategy implies executing at least
N = collection size / 1,000queries.
SELECT column1, column2, ..., columnM FROM table WHERE id IN (id11, id12, id13, ..., id1L);
SELECT column1, column2, ..., columnM FROM table WHERE id IN (id21, id22, id23, ..., id2L);
SELECT column1, column2, ..., columnM FROM table WHERE id IN (id31, id32, id33, ..., id3L);To implement all strategies, two classes were implemented: UserService and UserDao. The service uses QSplitter to split the original collection and then pass each generated subcollection to the DAO. It builds and executes each respective query. The implementation is presented below. To keep the focus on the strategy details, some methods were hidden: getConnection for getting an Oracle java.sql.Connection and resultSetToUsers which creates a new User instance for each record in the java.sql.ResultSet.
public class UserService {
private final QSplitter<Long> qsplitter = new QSplitter<>();
private final UserDao dao = new UserDao();
public List<User> findUsersByNQuery(List<Long> ids) throws SQLException {
var users = new ArrayList<User>();
this.qsplitter.splitCollection(ids).stream().map(this.dao::findByIds).forEach(users::addAll);
return users;
}
}
public class UserDao {
private Function<Collection<Long>, String> buildSimpleSelectIn = ids ->
new StringBuilder()
.append("SELECT id, name, email, street_name, city, country FROM employee WHERE id IN (")
.append(ids.stream().map(Object::toString).collect(Collectors.joining(",")))
.append(")").toString();
public List<User> findByIds(Collection<Long> ids) throws SQLException {
try (var rs = this.getConnection().prepareStatement(buildSimpleSelectIn.apply(ids)).executeQuery()) {
var users = new ArrayList<User>();
this.resultSetToUsers(rs, users);
return users;
}
}
}2. Disjunctions of Expression Lists Strategy
The second strategy takes advantage of the feature stated in the Oracle Expression Lists documentation: "A comma-delimited list of sets of expressions can contain any number of sets." In this case, to avoid executing the N queries proposed by the previous approach, this strategy proposes to build a query composed of lists of expressions interrelated by the OR operator. The code below describes the new query.
- Note: If the number of IDs hard coded in the query exceeds the upper limit of 65,535, a second query must be created to avoid the ORA-00913 error.
SELECT column1, column2, ..., columnM
FROM table
WHERE id IN (id11, id12, id13, ..., id1N) OR
id IN (id21, id22, id23, ..., id2N) OR
id IN (id31, id32, id33, ..., id3N);The QSplitter tool must receive a new method responsible for grouping the subcollections (split from the original collection) according to the maximum number of elements allowed by Oracle.
public class QSplitter<T> {
public static final int MAX_ORACLE_IN_CLAUSE_ELEMENTS = 1000;
public static final int MAX_ORACLE_RETRIEVE_ELEMENTS = 65535;
public List<List<List<T>>> splitAndGroupCollection(Collection<T> collection) {
var groupedCollection = new ArrayList<List<List<T>>>();
var splitCollection = this.splitCollection(collection, MAX_ORACLE_IN_CLAUSE_ELEMENTS);
if (collection.size() <= MAX_ORACLE_RETRIEVE_ELEMENTS) {
groupedCollection.add(splitCollection);
return groupedCollection;
}
groupedCollection.add(new ArrayList<>());
splitCollection.forEach(partition -> {
if (groupedCollection.getLast().size() * MAX_ORACLE_IN_CLAUSE_ELEMENTS + partition.size()
> MAX_ORACLE_RETRIEVE_ELEMENTS) {
groupedCollection.add(new ArrayList<>());
}
groupedCollection.getLast().add(partition);
});
return groupedCollection;
}
}
The next code snippet shows the UserService using the new QSplitter method to split and group the ID collection. The UserDao has a java.util.function.Function that builds the query using this second strategy.
public class UserService {
public List<User> findUsersByDisjunctionsOfExpressionLists(List<Long> ids) throws SQLException {
return this.dao.findByDisjunctionsOfExpressionLists(this.qsplitter.splitAndGroupCollection(ids));
}
}
public class UserDao {
private Function<List<List<Long>>, String> buildSelectDisjunctions = idsList ->
new StringBuilder("SELECT id, name, email, street_name, city, country FROM employee WHERE ")
.append(idsList.stream().map(ids -> new StringBuilder()
.append("id IN (").append(ids.stream().map(Object::toString)
.collect(Collectors.joining(","))).append(")"))
.collect(Collectors.joining(" OR "))).toString();
public List<User> findByDisjunctionsOfExpressionLists(List<List<List<Long>>> idsList) throws SQLException {
var users = new ArrayList<User>();
try (var conn = this.getConnection()) {
for (var ids : idsList) {
try (var rs = conn.prepareStatement(buildSelectDisjunctions.apply(ids)).executeQuery()) {
this.resultSetToUsers(rs, users);
}
}
}
return users;
}
}3. Multivalued Expression Lists Strategy
An alternative trick to get around the ORA-00913 error is to rewrite the expression list of IDs into a list of multivalued expressions. Any second value can be used as a second column to construct tuples. This simple change increases the capacity of the list of expressions from 1,000 to 65,535. Of course, if the size of the original collection exceeds the limit of 65,535, another query must be created. The structure of the query is described below.
SELECT column1, column2, ..., columnM
FROM table
WHERE (id, 0) IN ((id1, 0), (id2, 0), (id3, 0), ..., (id65535, 0))Since the Java code is very similar to the previous strategy, it will be omitted here.
4. Union All Strategy
Another option is to create a sequence of UNION ALL queries with the structure presented in the first strategy.
SELECT column1, column2, ..., columnM FROM table WHERE id IN (id1, id2, id3, ..., idL)
UNION ALL
SELECT column1, column2, ..., columnM FROM table WHERE id IN (idL+1, idL+2, idL+3, ..., id2L)
UNION ALL
SELECT column1, column2, ..., columnM FROM table WHERE id IN (id2L+1, id2L+2, id2L+3, ..., id3L)The implementation can reuse the code from the buildSimpleSelectIn function created for the first strategy. In this case, all generated SELECTs are joined by UNION ALL operators. It is worth noting that there is no restriction on the number of expression lists. So only one query is executed. The code is presented below.
public class UserService {
public List<User> findUsersByUnionAll(List<Long> ids) throws SQLException {
return this.dao.findByUnionAll(this.qsplitter.splitCollection(ids));
}
}
public class UserDao {
public List<User> findByUnionAll(List<List<Long>> idsList) throws SQLException {
var query = idsList.stream().map(buildSimpleSelectIn).collect(Collectors.joining(" UNION ALL "));
try (var rs = this.getConnection().prepareStatement(query).executeQuery()) {
var users = new ArrayList<User>();
this.resultSetToUsers(rs, users);
return users;
}
}
}5. Temp Table Strategy
The last strategy involves creating a temporary table into which all IDs should be inserted. The values inserted into the table must exist after the end of the transaction. To achieve this, the ON COMMIT PRESERVE ROWS clause must be part of the SQL statement for creating the table. The complete command is presented below.
CREATE GLOBAL TEMPORARY TABLE employee_id (emp_id NUMBER) ON COMMIT PRESERVE ROWS;The implementation doesn't use the QSplitter tool since there is no need to split the original collection of IDs. On the side of UserDao, it first inserts all IDs into the temp table (the JDBC batch API is employed). Next, a query with a JOIN clause for relating all IDs from the temp table is executed. The code is detailed below.
public class UserService {
public List<User> findUsersByTempTable(List<Long> ids) throws SQLException {
return this.dao.findByTemporaryTable(ids);
}
}
public class UserDao {
public List<User> findByTemporaryTable(List<Long> ids) throws SQLException {
var queryInsertTempTable = "INSERT INTO employee_id (emp_id) VALUES (?)";
var querySelectUsers = """
SELECT id, name, email, street_name, city, country
FROM employee JOIN employee_id ON id = emp_id ORDER BY id
""";
try (var conn = this.getConnection()) {
try (var pstmt = conn.prepareStatement(queryInsertTempTable)) {
for (var id : ids) {
pstmt.setLong(1, id);
pstmt.addBatch();
}
pstmt.executeBatch();
}
var users = new ArrayList<User>();
try (var rs = conn.prepareStatement(querySelectUsers).executeQuery()) {
this.resultSetToUsers(rs, users);
}
return users;
}
}
}Performance
The performance of the five strategies was compared considering collections of IDs ranging in size from 1,000 to 100,000. The code was implemented using Oracle JDK 21.0.4 and java.time.* API was used to count the wall time of each strategy. All tests were performed on the Windows 11 Pro for Workstations operating system installed on a machine with an Intel(R) Xeon(R) W-1290 CPU 3.20 GHz and 64 GB of RAM.
As shown in the graph below, wall time for collections up to 10,000 IDs was very similar for all strategies. However, from this threshold onwards the performance of the N Queries strategy degraded considerably compared to the others. Such a behavior can be a result of the volume of I/O operations and external delays caused by executing multiple database queries.
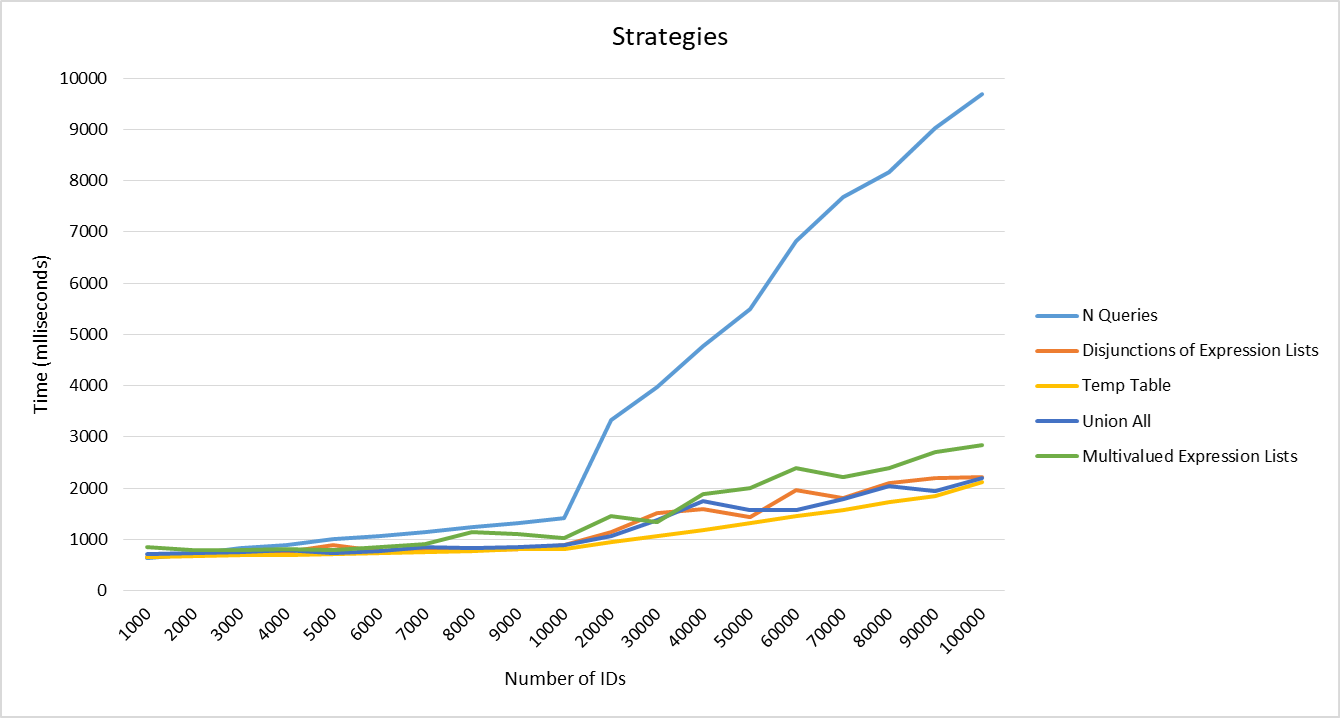
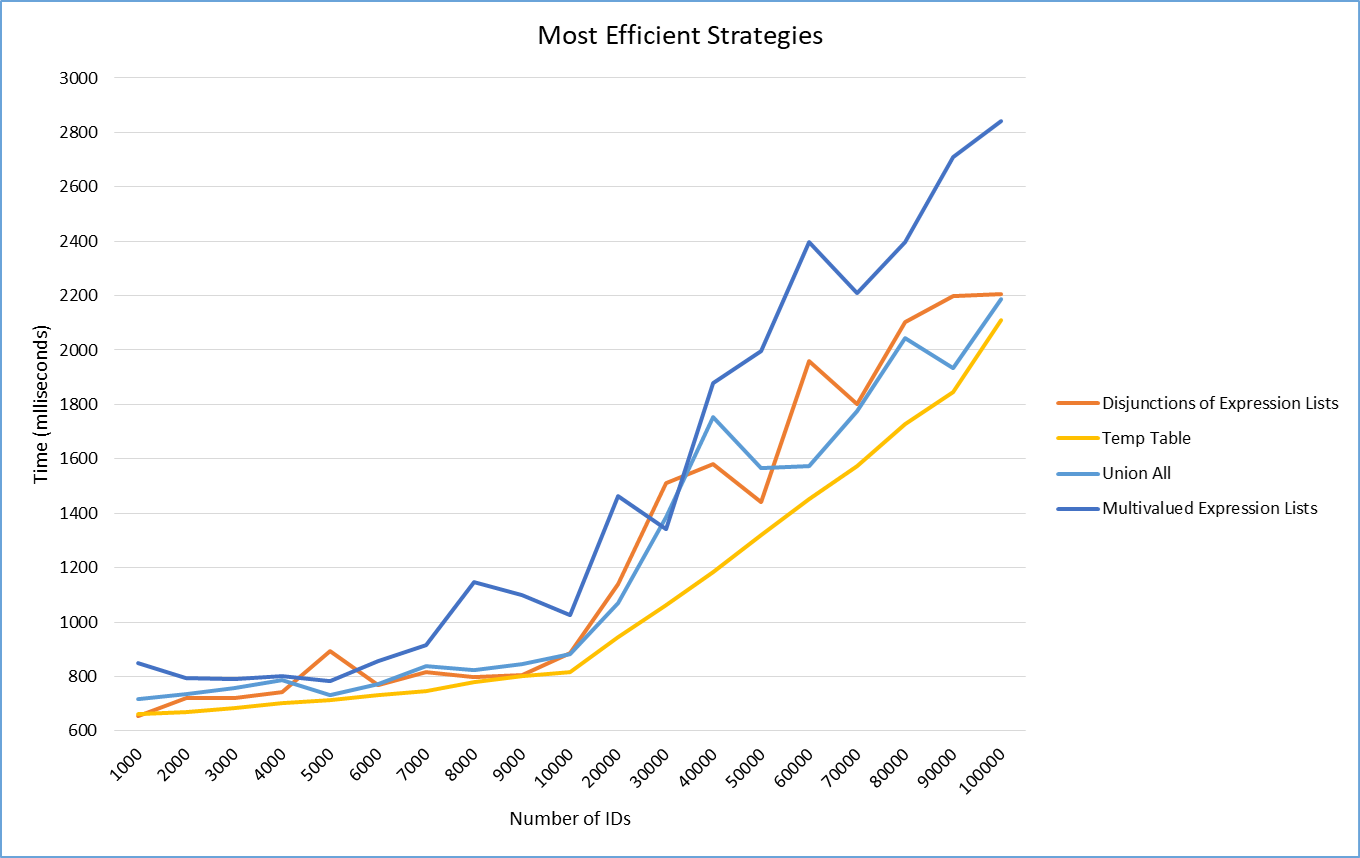
By removing the curve of the slowest strategy from the graph, the behavior of the most efficient ones can be better analyzed. Although there is not a big performance difference between them, it is visible that the Temp Table strategy dominates with lower times in all experiments. Even though it performs an additional step of inserting all IDs into the temporary table, this strategy does not need to use the QSplitter tool to generate subcollections and takes advantage of the use of the JOIN clause to avoid indicating hard-coded IDs in the SELECT. This tradeoff may have benefited the strategy's performance.
Conclusion
The need to retrieve a large volume of records from the Oracle database based on a large list of identifiers is not an uncommon task during the development of enterprise systems. This scenario can lead to Oracle errors ORA-01795 and ORA-00913. How difficult it is to work around these errors depends on various particularities of the source code and the system architecture. So, the five strategies presented constitute a toolkit for developers to avoid these errors and incorporate what best fits the system's needs. The complete source code is available on a GitHub repository.
Opinions expressed by DZone contributors are their own.
Comments