XAI for Fraud Detection Models
We will explore the importance of eXplanation in fraud detection models and learn how it can help to understand different patterns of fraud in our system.
Join the DZone community and get the full member experience.
Join For FreeOne would question, why should I worry about what is happening behind the scenes as long as my model is able to deliver high-precision results for me?
In this article, we dive deep into the aspect of reasoning and try to answer the question above. More importantly, we will understand how it can help us to build greater insights into evolving fraud patterns.
The eXplainable AI (XAI) has been around for quite a while, but it has not really created a buzz in the industry. Now, with the arrival of the DeepSeek-R1 reasoning model, there is a buzz in the industry for models that can not only make highly accurate predictions but also provide some reasoning on how these predictions were made.
The research of XAI has demonstrated that a model that can accurately identify fraudulent transactions may not necessarily be accurate in terms of reasoning. XAI provides system users with the insight and confidence that not only is the model working as expected, but also the reasoning for the decisions is accurate. In subsequent sections, we will use simple techniques of XAI and unsupervised learning to solidify our approach.
Methodology
We would use a publicly available fraud data set with anonymized feature attributes and build a simple classifier model that provides us decent accuracy to detect fraud. The model will be used further for the calculation of feature importance that drives fraud decisions.
Next, we use SHapley Additive exPlanations (SHAP) to determine the importance of features that drive our decisions of fraud vs non-fraud transactions. AWS Sagemaker Explain service also uses the same concept for explanation. Here is a cool paper for users who would like to understand more about it.
Finally, once we have the SHAP values for our features, we would use an unsupervised learning technique to categorize the different types of fraud transactions in our dataset. The idea of clustering gives us the fraud patterns in our dataset, and businesses can use it to monitor and understand these patterns easily.
Experiment and Results
We start by installing libraries like scikit-learn, shap, and pandas.
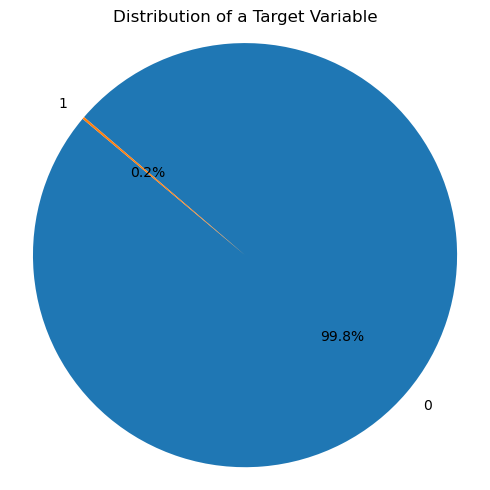
We check for any missing values in our dataset and try to understand the data distribution. The fraud dataset should be unbalanced, which means that normal transactions should far exceed fraudulent transactions. Our dataset contains 0.2% of transactions identified as fraud, and the rest are non-fraud. In this example, 0 indicates a normal transaction, and 1 indicates a fraudulent transaction.
Below, we have a simple random forest classifier that tries to predict the fraudulent transactions with 93% precision. The accuracy is reasonable for us to start our eXplanation process and determine feature weights that are primarily used for identifying the fraud.
from sklearn.ensemble import RandomForestClassifierfeatures = df.columns[:-1]X = df[features]y = df['Class']X = X.drop('Time',axis=1)features = X.columnsmodel = RandomForestClassifier(n_estimators=5)X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=287)model.fit(X_train, y_train)y_pred = model.predict(X_test)cm = confusion_matrix(y_test,y_pred)print(classification_report(y_test,y_pred))precision recall f1-score support 0 1.00 1.00 1.00 85297 1 0.93 0.75 0.83 146 accuracy 1.00 85443 macro avg 0.97 0.88 0.92 85443weighted avg 1.00 1.00 1.00 85443Next, we extract shap values for all the fraudulent transactions in the dataset. We will apply an unsupervised clustering algorithm on shap values to generalize different underlying reasons for fraud. Please note that the process to determine the SHAP values will be time-consuming.
import shapexplainer = shap.TreeExplainer(model)shap_values = explainer(X)We use dimensionality reduction techniques like T-SNE to visualize higher dimensional data. We pass on the results to clustering algorithms like k-means to identify fraud patterns in our dataset. The silhouette score and elbow technique are used to identify the optimal value of k.
X = fraud_shap_valuesfrom sklearn.cluster import KMeansfrom sklearn.manifold import TSNEtsne = TSNE(n_components=2, random_state=42)X_tsne = tsne.fit_transform(X)tsne.kl_divergence_common_params = { "n_init": "auto", "random_state": 42,}from sklearn.metrics import silhouette_scoresil = []kmax = 10# dissimilarity would not be defined for a single cluster, thus, minimum number of clusters should be 2for k in range(2, kmax+1): kmeans = KMeans(n_clusters = k, **common_params).fit(X_tsne) labels = kmeans.labels_ sil.append(silhouette_score(X_tsne, labels, metric = 'euclidean'))plt.plot(range(2, kmax+1),sil)plt.xlabel("K") plt.ylabel("Silhouette Score") plt.title("Elbow method")plt.show()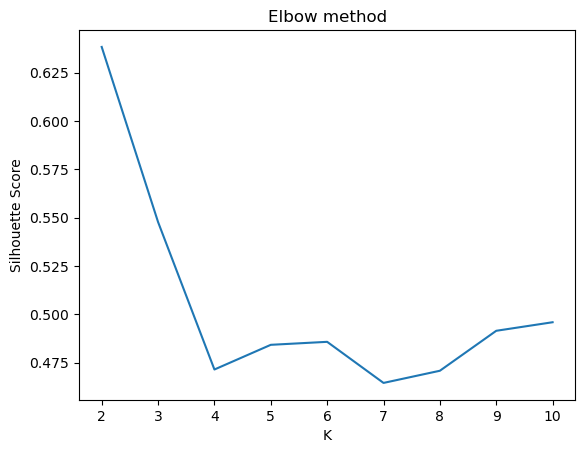
y_pred = KMeans(n_clusters=k, **common_params).fit_predict(X_tsne)plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y_pred)plt.title("Optimal Number of Clusters")plt.show()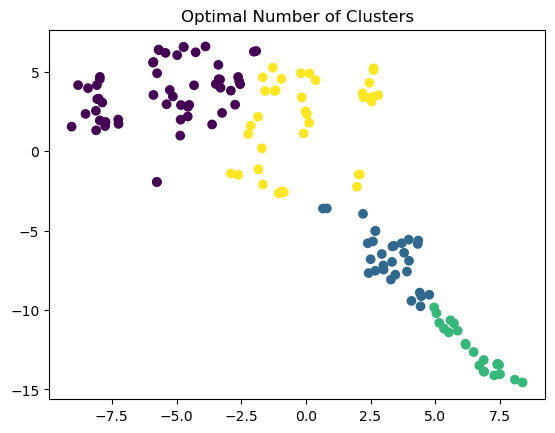
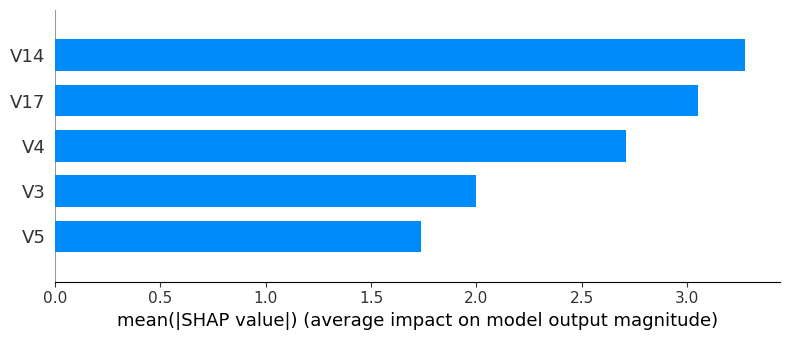
Finally, in the last step of our process, we need to identify the features that have maximum weights for the frauds in our dataset. We plot a bar graph with the top five heavyweights for each fraud category.
for i in range(k): cluster_data = explanation_df[explanation_df['Class'] == i] cluster_data = cluster_data.drop('Class',axis=1) cluster_data = cluster_data.drop('Amount',axis=1) shap.summary_plot(cluster_data.to_numpy(),cluster_data,plot_type='bar',feature_names=features, max_display=5)The SHAP summary plot highlights various attributes contributing to different types of fraud in our dataset.
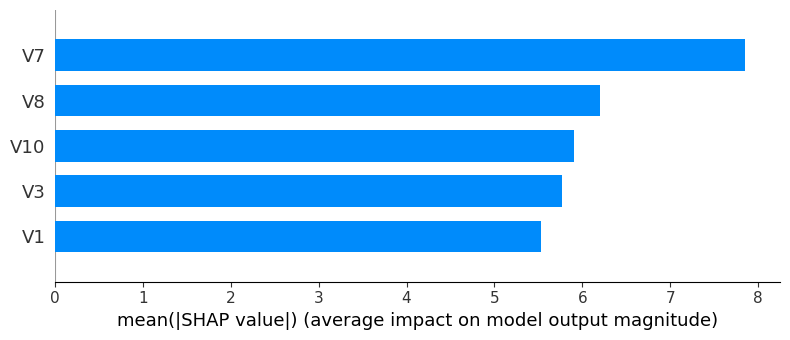
Conclusion
Above, we have shown two types of fraud transactions in our dataset. If we observe closely, most of the top five factors contributing to the two types of fraud are different. Business users can easily interpret the graphs and understand the combination of features that are causing different types of fraud.
The clustering of SHAP values helps us to identify various patterns of fraud in the system. Without reasoning capabilities, it would be difficult for end users to understand any new or evolving patterns of fraud or why a certain transaction is fraudulent.
Hope you guys liked the article and that it helped you learn something new!
Opinions expressed by DZone contributors are their own.
Comments