Yolo-FastestV2: Faster and Lighter
Based on Yolo's improved lightweight target detection algorithm, the parameter is only 250k, and the smartphone can reach 300fps.
Join the DZone community and get the full member experience.
Join For FreeYolo-Fastest focuses on single-core, real-time inference performance and low CPU usage under real-time conditions. Not only can it realize real-time performance on mobile phones, but also on RK3399, Raspberry Pi 4, and various Cortex-A53 while remaining low-cost. The power consumption device meets certain real-time performance standards. After all, these embedded devices are much weaker than mobile phones, but they are more widely used and cheaper.
Let me talk about the original intention of Yolo-Fastest. Most people used Mobilenet-SSD in early lightweight object detection. In actual tests, it is difficult to achieve real-time on commonly used ARM devices; it can only be done on some high-end mobile phones. All big cores can barely reach real-time when booting, not to mention the "powerful" RK3399 and other commonly used ARM CPUs in the industry. Real-time is basically impossible.
Comparing Yolo Network Versions
First, compare Yolo-FastestV2 with Yolo-FastestV1.1:
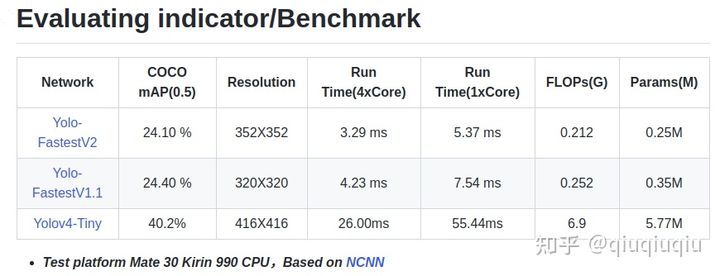
I did not optimize the accuracy this time. This time I optimized the speed. After all, what I am after is the fastest. However, the 0.3 percent loss of accuracy has been exchanged for a 30 percent increase in inference speed and a 25 percent reduction in the number of parameters. At least I think it's worth it. Do not pursue speed, but pay more attention to the cost-effectiveness of algorithm effect and reasoning efficiency.
Later, I optimized the lightweight of YOLOV3 with mobilenet. Calculated at 1.8BFlops, the performance of Kirin 990 can reach ~55fps, and the big core is fully turned on. Although good speed can be achieved on high-end mobile phones, some low-end mobile phone CPUs and the high-end chip RK3399 commonly used in the industry still cannot meet the real-time requirements.
Second, in practical applications, considering power consumption and system resource occupancy, multi-core is generally not fully utilized to reason about models. After all, some resources are reserved for other applications, so I generally use single-core, and at most dual-core. Especially on mobile phones, the power consumption problem is particularly serious. If the CPU usage is too high during model inference, it will cause overheating and frequency reduction, which is counterproductive.
Finally, the battery life will be shortened. Especially on mobile phones, the power consumption problem is particularly serious. If the CPU usage is too high during model inference, it will cause overheating and frequency reduction, which is counterproductive.
Therefore, we should not only look at the time-consuming model inference, but also pay attention to the system resources, memory, and CPU usage consumed by model inference. For example, both models can reach 30fps on the CPU, but the CPU only accounts for 20% of model A in the case of single-core real-time. Model B achieves real-time when the four cores are fully turned on. The CPU usage may be 100%, but Model B may perform better. In this case, you need to weigh the pros and cons.
Improvements to Yolo-FastestV2
First, the backbone of the model was replaced by shufflenetV2. Compared with the original backbone, the memory access is reduced and lighter. Secondly, the matching mechanism of Anchor refers to YOLOV5, which is actually the official version of YOLOV5 and Darknet. The matching mechanism of YOLOV4 in Anchor is quite different (I will not go into details. There are many analyses on the internet).
The next step is the decoupling of the detection head. This is also a reference to YoloX. It will return to the detection frame and classify the foreground and background. The classification of the detection category has the feature map of Yolo coupled into three different feature maps, where the classification of the foreground-background and the classification of the detection category share the same network branch parameters.
Finally, the loss of detection category classification is replaced by the sigmoid's softmax.
By the way, this time there are only two scale detection heads that output 11x11 and 22x22, because the accuracy of three detection heads (11x11, 22x22, 44x44) and two detection heads (11x11, 22x22) are not much different in coco. I think the reasons are as follows:
- Backbone has too few feature maps corresponding to 44x44 resolution
- The positive and negative anchors are severely unbalanced
- Small objects are difficult samples and require high model learning capabilities.
Later, you may be more concerned about the comparison with yolox and nanoDet. The accuracy is certainly not comparable, but the speed should be two or three times faster. The volume of PP-YOLO Tiny is only 1.3M ("Lighter and lighter than YOLO-Fastest. Faster?") The volume of int8 is a bit short compared with the volume of Yolo-fastest fp32. YOLO-FastestV2 int8 is only 250kb, although I have not run PP-YOLO Tiny, but it should still be faster than that. Therefore, the choice of model depends on everyone's needs.
RK3399 and Raspberry Pi 4 match ncnn bf16s, but YOLO-FastestV2 can be real-time.
The final measured effect of the model:


Opinions expressed by DZone contributors are their own.
Comments