The fields of the Query and Mutation types are the entry points into a graph. .
Fields
Each type is composed of one or more fields, which can be scalar values or complex objects that refer to other types, resulting in nesting. Each GraphQL query specifies which schema fields to return. This is referred to as the query’s selection set.
Consider the following schema excerpt:
type Query {
topRatedMovies: [Movie]
}
type Movie {
id: ID!
title: String
year: Int
plot: String
poster: String
imdbRating: Float
genres: [String]
similar(limit: Int = 3): [Movie]
rating: RATING
actors: [Actor]
avgStars: Float
}
Here is a valid query against that schema:
{
topRatedMovies {
title
year
avgStars
}
}
And here is an example result of that query:
{
"data": {
"topRatedMovies": [
{
"title": "Godfather, The",
"year": 1972,
"avgStars": 4.4875
},
{
"title": "Shawshank Redemption, The",
"year": 1994,
"avgStars": 4.487138263665597
},
{
"title": "On the Waterfront",
"year": 1954,
"avgStars": 4.448275862068966
}
]
}
}
Arguments
Schema fields can accept arguments, which can be required or optional. Each argument can optionally have a default value if one isn’t provided.
The following Query.moviesByTitle field accepts two arguments. The limit argument specifies a default value:
type Query {
moviesByTitle(title: String!, limit: Int = 3): [Movie]
}
Here is an example query that provides the required title argument:
{
moviesByTitle(title: "Matrix Reloaded") {
title
similar(limit: 1) {
title
year
}
}
}
And here is an example result:
{
"data": {
"moviesByTitle": [
{
"title": "Matrix Reloaded, The",
"similar": [
{
"title": "Matrix, The",
"year": 1999
}
]
}
]
}
}
Variables
GraphQL variables enable you to provide values for arguments without hardcoding their values directly into a query string. This helps prevent injection attacks that use string interpolation to build queries from user-supplied content. To use variables, first declare $varName as a valid variable for the query, then replace the value in the query with $varName. Finally, pass the key-value pair varName: value in a dictionary alongside the query.
Here’s an example query with two variables:
query MoviesByTitle($movieTitle: String!, $similarLimit: Int) {
moviesByTitle(title: $movieTitle) {
title
similar(limit: $similarLimit) {
title
year
}
}
}
And here’s a variables object that’s provided alongside that query:
{
"movieTitle": "Matrix Reloaded",
"similarLimit": 1
}
Result:
{
"data": {
"moviesByTitle": [
{
"title": "Matrix Reloaded, The",
"similar": [
{
"title": "Matrix, The",
"year": 1999
}
]
}
]
}
}
Mutations
While queries enable you to read back-end data, GraphQL mutations enable you to create, update, and delete that data. To enable mutations, a schema defines a Mutation type. The fields of this type are entry points that correspond to different write operations that clients can execute.
Consider a UserReview type:
type UserReview {
user: User
rating: Int
movie: Movie
}
To create a new UserReview, a schema might define this Mutation field:
type Mutation {
createReview(userId: ID!, movieId: ID!, rating: Int): UserReview
}
Note that the mutation returns a UserReview object. This means that you can access any of the fields available on Movie and User (in a nested fashion):
Mutation:
mutation {
createReview(userId: "20", movieId: "16", rating: 5) {
movie {
title
similar(limit: 2) {
title
}
}
user {
name
}
rating
}
}
Result:
{
"data": {
"createReview": {
"movie": {
"title": "Casino",
"similar": [
{
"title": "Four Brothers"
},
{
"title": "Night and the City"
}
]
},
"user": {
"name": "Nicole Ramsey"
},
"rating": 5
}
}
}
Input Types
In the previous mutation example, three individual primitive arguments were passed to the createReview field. Instead, this field could accept a single input type that includes all of those individual primitive values as fields. Input types are especially useful for mutations where the goal is to pass an update as a single object.
Input type:
input ReviewInput {
rating: Int!
movieId: ID!
userId: ID!
}
Then modify the createReview field to accept one argument of type ReviewInput:
type Mutation {
createReview(review: ReviewInput!): UserReview
}
The mutation becomes:
mutation CreateReviewForMovie($review: ReviewInput) {
createReview(review: $review) {
movie {
title
}
user {
name
}
rating
}
}
Variables:
{
"review": {
"movieId": "16",
"userId": "20",
"rating": 5
}
}
Results:
{
"data": {
"createReview": {
"movie": {
"title": "Casino"
},
"user": {
"name": "Nicole Ramsey"
},
"rating": 5
}
}
}
Fragments
A fragment is a reusable set of fields that can be defined and referenced by name in multiple GraphQL queries. This enables you to factor out common logic and reduce repetition in operations. To apply a fragment inside a query, use a fragment spread operator (...) inside the selection set:
{
moviesByTitle(title: "Matrix Reloaded") {
...movieSummaryFields
}
}
fragment movieSummaryFields on Movie {
title
year
imdbRating
}
Result:
{
"data": {
"moviesByTitle": [
{
"title": "Matrix Reloaded, The",
"year": 2003,
"imdbRating": 7.2
}
]
}
}
Inline Fragments
Inline fragments are useful for queries where a field’s return type is determined at runtime. These fragments use the syntax ...on <TYPE>. They are primarily used when a field’s return type is an abstract type (i.e., a union or interface).
Consider the following:
type Query {
personByName(name: String!): [PersonResult]
}
union PersonResult = User | Actor
PersonResult can be either a User or Actor. In this case, an inline fragment can be used to fetch the appropriate fields for each type in the union:
{
personByName(name: "Tom Cruise", limit: 3) {
... on Actor {
name
movies {
title
}
}
... on User {
name
}
}
}
Result:
{
"data": {
"personByName": [
{
"name": "Tom Cruise",
"movies": [
{
"title": "Risky Business"
},
{
"title": "Cocktail"
},
{
"title": "Top Gun"
}
]
}
]
}
}
Subscriptions
Often, clients want to receive updates from the server when certain data changes. In addition to queries and mutations, GraphQL supports a third operation type, subscription, which allows a client to subscribe to receive event updates. Subscriptions are real-time streaming chunks of data that allow bi-directional interaction over a single persistent connection (often WebSocket).
Let's say a client wants to receive updates when a user submits a movie rating for a particular movie. If the user is viewing a movie page, the UI would update when a new rating is received.
Every time the underlying MovieReviewSubscription is changed, the new value for rating will be pushed over WebSocket (or some other type of persistent connection). The nature of operations performed by subscription is slightly different than that of query — the former has real-time fetching of data while the latter fetches only once.
Subscription operation:
subscription MovieReviewSubscription($movieId: ID!) {
movieReviewSubscription(movieId: $movieId) {
movie {
title
}
rating
}
}
Directives
GraphQL directives enable static and dynamic schema modification. Here are two built-in directive examples:
|
@skip
|
@include
|
query myMovieQuery($testValue: Boolean!) {
experimentalField @skip(if: $testValue)
}
In this example, experimentalField is queried only if the variable $testValue has the value false. |
query myMovieQuery($testValue: Boolean!) {
experimentalField @include(if: $testValue)
}
In this example, experimentalField is queried if the variable $testValue has the value true. |
Learn more about directives here.
Securing Your GraphQL APIs
Failing to secure APIs properly can have serious consequences, especially with GraphQL. Because clients can craft complex queries, servers must be ready to handle such queries. Certain queries might be abusive or malicious, or they might simply be very large. In all of these cases, the query can potentially bring down your GraphQL server. GraphQL recommends a few guidelines and strategies.
Timeout
Setting a timeout informs a server and any intermediaries of the maximum amount of time they can spend to execute any query. If a query exceeds this maximum, the server ceases execution.
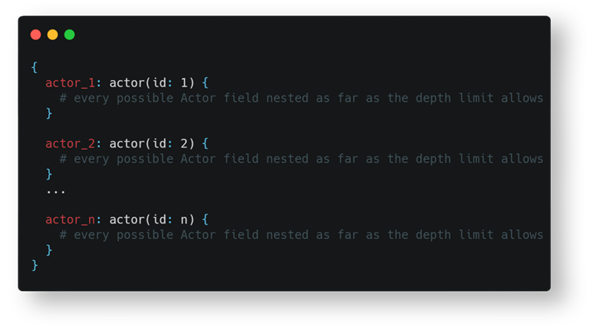
Limiting Maximum Query Depth
GraphQL schemas are often cyclic graphs, meaning a malicious GraphQL query can exploit nested relationships. For example, let’s say there’s an Entertainment API that exposes an Actor type. Each Actor can belong to a Movie, and each Movie can have an Actor in the form of an Artist. Considering this, a deeply nested query such as the following is valid:

A circular reference like this can lead to significant load on API servers.
GraphQL servers can enforce depth-limiting caps to control the amount of nesting that can be present in any given query. Before the query is processed, its depth is calculated (the above query has six nesting levels). If the nesting depth exceeds the given limit, it is rejected outright.
Query Complexity Limits
Another troublesome query relates to complexity — for example, a client can simply request many fields on the root query object.
To deal with this kind of query, GraphQL has built-in support for complexity analysis. An arbitrary number can be assigned as points to any field. When an incoming query is received, these arbitrary numbers are summed. If the total exceeds the threshold, an appropriate error message is returned.
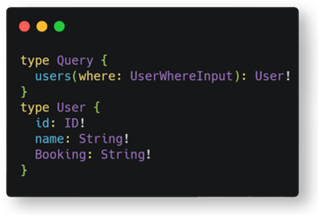
Field-Based Permissions
Given a schema with the objects Users, Bookings, and Movies, the Bookings and Users objects are private, so authentication is needed to access them. Authentication is handled by resolvers. The Movies object is public and can be accessed without being authenticated. Now, what should happen with the query below if the client is not authenticated?