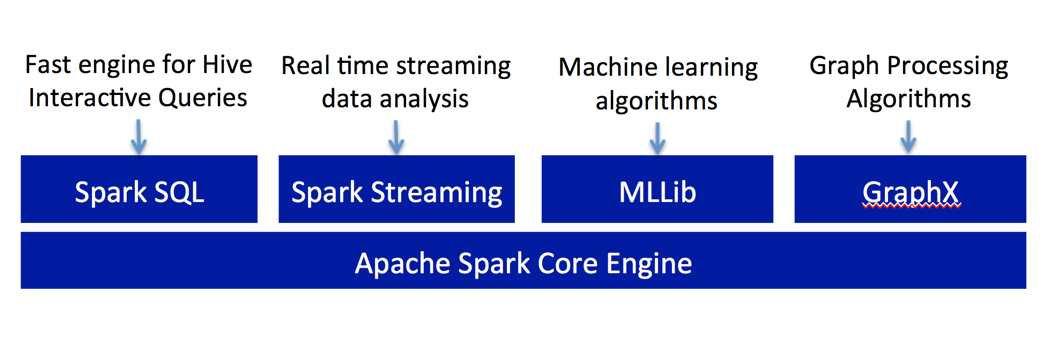
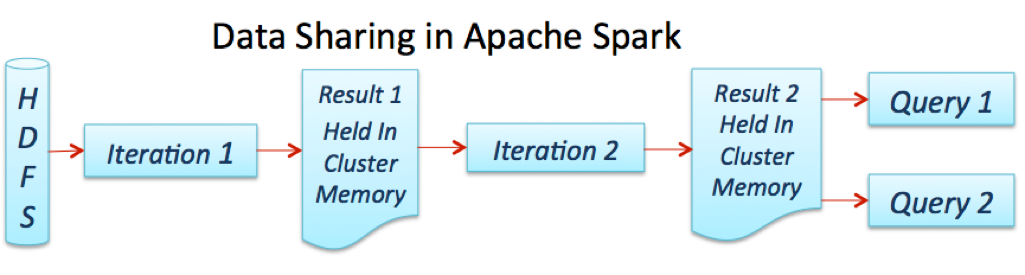
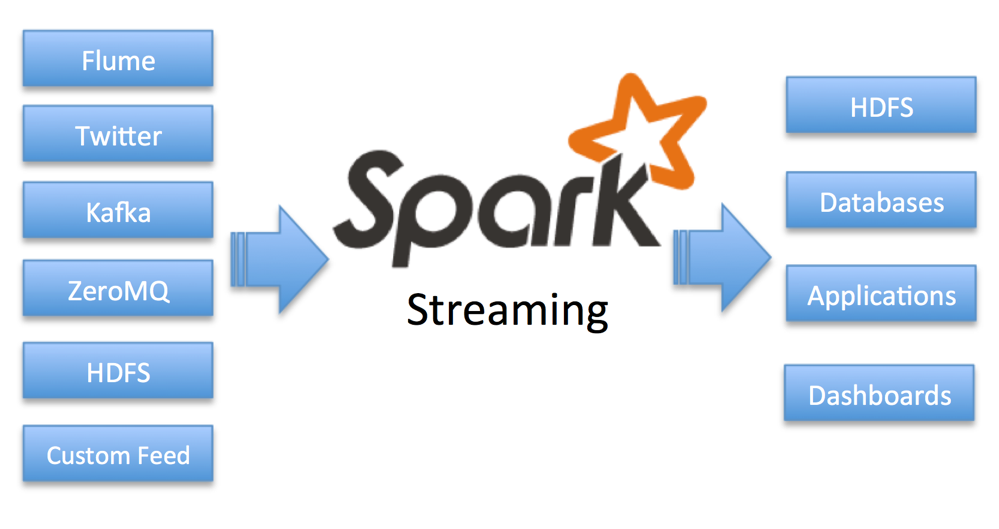
Spark Streaming provides a scalable, fault tolerant, efficient way of processing streaming data using Spark’s simple programming model. It converts streaming data into “micro” batches, which enable Spark’s batch programming model to be applied in Streaming use cases. This unified programming model makes it easy to combine batch and interactive data processing with streaming.
The core abstraction in Spark Streaming is Discretized Stream (DStream). DStream is a sequence of RDDs. Each RDD contains data received in a configurable interval of time.
Spark Streaming also provides sophisticated window operators, which help with running efficient computation on a collection of RDDs in a rolling window of time. DStream exposes an API, which contains operators (transformations and output operators) that are applied on constituent RDDs. Let’s try and understand this using a simple example:
importorg.apache.spark._
importorg.apache.spark.streaming._
val conf =newSparkConf().setAppName(“appName”).setMaster(“masterNode”)
val ssc =newStreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
The above snippet is setting up Spark Streaming Context. Spark Streaming will create an RDD in DStream containing text network streams retrieved every second.
There are many commonly used source data streams for Spark Streaming, including Apache Kafka, Apache HDFS, Twitter, Apache NiFi S2S, Amazon S3, and Amazon Kinesis.
map(func)
Purpose: Create new DStream by applying this function to tall constituent RDDS in DStream |
lines.map(x=>x.tolnt*10).print()
nc –lk 9999
12
34 |
Output:
120
340 |
|
flatMap(func)
Purpose: This is same as map but mapping function can output 0 or more items |
lines.flatMap(_.split(“ “)).print()
nc –lk 9999
Spark is fun |
Output:
Spark is fun |
|
count()
Purpose: create a DStream of RDDs containing count of number of data elements |
lines.flatMap(_.split(“ “)).print()
nc –lk 9999
say
hello
to
spark |
Output:
4 |
|
reduce(func)
Purpose: Same as count but instead of count, the value is derived by applying the function |
lines.map(x=>x.toInt).reduce(_+_).print()
nc –lk 9999
1
3
5
7 |
Output:
16 |
|
countByValue()
Purpose: This is same as map but mapping function can output 0 or more items |
lines.map(x=>x.toInt).reduce(_+_).print()
nc –lk 9999
spark
spark
is
fun
fun |
Output:
(is,1)
(spark,2)
(fun,2) |
|
| reduceByKey(func,[numTasks]) |
lines.map(x=>x.toInt).reduce(_+_).print()
nc –lk 9999
spark
spark
is
fun
fun |
Output:
(is,1)
(spark,2)
(fun,2) |
|
| reduceByKey(func,[numTasks]) |
val words = lines.flatMap(_.split(“ “))
val wordCounts = words.map(x => (x, 1)).
reduceByKey(_+_)
wordCounts.print()
nc –lk 9999
spark is fun
fun
fun |
Output:
(is,1)
(spark,1)
(fun,3) |
|
| The following example shows how Apache Spark combines Spark batch with Spark Streaming. This is a powerful capability for an all-in-one technology stack. In this example, we read a file containing brand names and filter those streaming data sets that contain any of the brand names in the file. |
transform(func)
Purpose: Creates a new DStream by
applying RDD->RDD transformation to all
RDDs in DStream.
brandNames.txt
coke
nike
sprite
reebok |
val sparkConf = new SparkConf()
.setAppName(“NetworkWordCount”)
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(10))
val lines = ssc.
socketTextStream(“localhost” 9999,
StorageLevel.MEMORY_AND_DISK_SER)
val brands = sc.textFile(“/tmp/names.txt”)
lines.transform(rdd=> {
rdd.intersection(brands)
}).print()
nc –lk 9999
msft
apple
nike
sprite
ibm |
Output:
sprite
nike |
|
Common Window Operations
window(windowLength, slideInterval)
Purpose: Returns a new DStream computed from windowed batches of source DStream |
val win = lines.window(Seconds(30),Seconds(10)); win.foreachRDD(rdd => {
rdd.foreach(x=>println(x+ “ “))
})
nc –lk 9999
10 (0th second)
20 (10 seconds later)
30 (20 seconds later)
40 (30 seconds later) |
Output:
10
10 20
20 10 30
20 30 40 (drops 10) |
|
countByWindow(windowLength, slideInterval)
Purpose: Returns a new sliding window count of elements in a steam |
lines.countByWindow(Seconds(30),Seconds(10)).print()
nc –lk 9999
10 (0th second)
20 (10 seconds later)
30 (20 seconds later)
40 (30 seconds later) |
Output:
1
2
3
3 |
|
For additional transformation operators, please refer to http://spark.apache.org/docs/latest/streaming-programming-guide.html#transformations.
Spark Streaming has powerful output operators. We already saw foreachRDD() in the above example. For others, please refer to http://spark.apache.org/docs/latest/streaming-programming-guide.html#output-operations.
Structured Streaming has been added to Apache Spark and allows for continuous incremental execution of a structured query. There a few input sources supported including files, Apache Kafka, and sockets. Structured Streaming supports windowing and other advanced streaming features. It is recommended when streaming from files that you supply a schema as opposed to letting Apache Spark infer one for you. This is a similar feature of most streaming systems, like Apache NiFi and Hortonworks Streaming Analytics Manager.
val sStream = spark.readStream.json(“myJson”).load()
sStream.isStreaming
sStream.printSchema
For more details on Structured Streaming, please refer to https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html.