Standardized Team-Based Development
Before DevOps arrived on the scene, the wall between Dev and Ops was similar to the division between application developers and database developers. It is someone else's domain, a different coding language is used, and database deployments are problematic at best.
Times have changed. Many application developers are now responsible for database development, too. They switch between coding in C# or Java to writing queries in a database language like T-SQL used with Microsoft SQL Server. In many ways, this had to happen because the faster speed of releases that DevOps encourages means front-end and back-end development are now much more interconnected.
This can also be problematic, however, because developers have different coding styles. Writing in a language like T-SQL brings its own challenges, and conflicts can occur with developers working on different branches at the same time. The key is to introduce collaborative coding, bake in security earlier to prevent issues later down the line, and, as the Accelerate State of DevOps Report recommends, put changes to the database into version control.
Insist on Secure Coding
Thanks to DevOps, applications are developed faster and eliminate the need for security reviews at the end of development. Instead, security is baked into the pipeline with tools like static code analyzers and open-source code vulnerability scanners that test code as soon as changes are made.
If the speed at which databases are developed is to follow the same route, a similar approach needs to be taken. Security needs to shift left so that errors are caught earlier and the chances of them ever reaching production are minimized.
Just as C# and other languages have "code smells" that, while not necessarily breaking changes, are errors in source code that can have a negative impact on performance and quality, it is common to integrate code scanning tools (for example, SonarQube and Sonar Cloud) which identify code smells and bugs earlier in the development pipeline. Additionally, there are tools to detect application licenses, which are quite useful for enterprise organizations to ensure any dependent software is licensed properly — and that the license is in line with their organization’s requirements.
As an example, a common open-source tool for license scanning is the ScanCode toolkit. There are other tools that scan against vulnerabilities, containers, and infrastructure as code, such as the popular tool Snyk, which helps to ensure a secure software development.
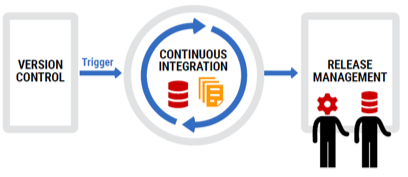
Version Control Everything
Version control is becoming standard in application development and requires developers to check their changes into a common repository during the development process, preferably at the end of each working day. As a direct result, developers have access to the latest version of the application, one source of truth is maintained, and it's always clear what was changed, when it was changed, and who changed it.
Figure 2
This is just as true for the database code, which can also be version controlled, preferably by integrating with and plugging into the same version-control system used for applications. However, there are two approaches for version controlling databases that appear to be diametrically opposed.
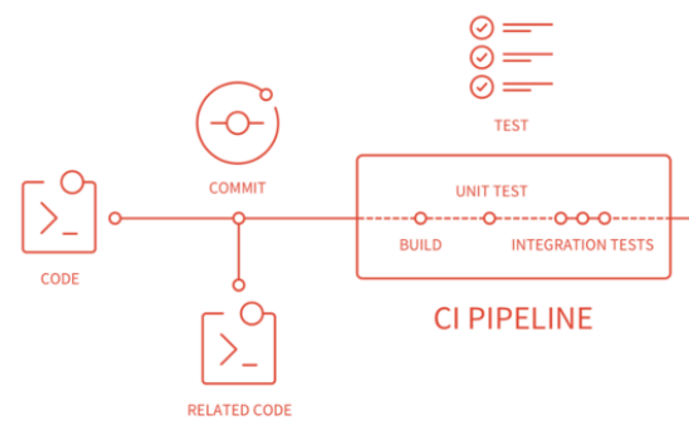
A state-based approach compares the existing database schema with a snapshot (or state) of the target database schema and generates a SQL script that modifies, creates, or deletes objects in the existing database. After running the script, the database will be up to date with respect to your latest schema.
Figure 3
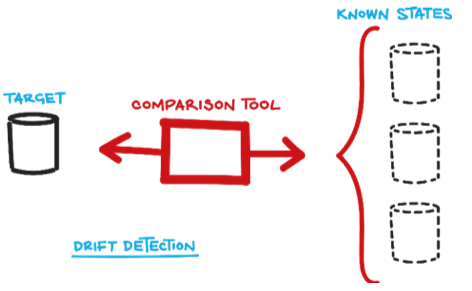
This approach doesn’t need to know that the move from version 3.1 to 3.2 dropped two columns and added one table. It’s the job of the comparison tool to discern that in its discovery phase before it generates the script.
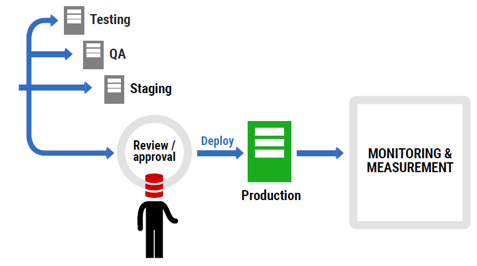
A migrations-based approach is at the opposite extreme. Consider that as you develop your application, you create a table, perhaps drop a column, and rename a stored procedure. Each of these changes occurs a step at a time as you develop new code, moving from the old database schema to the new database schema. These steps are called migrations.
Figure 4
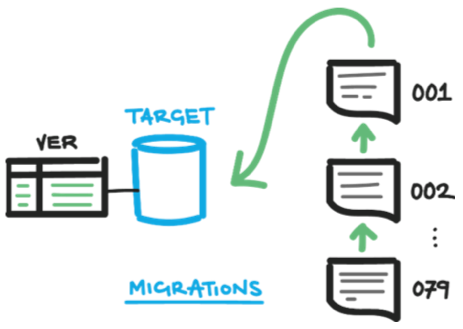
The migrations-based approach saves a script of each change and, to update the database to the latest schema, you simply run in a sequence all of the migration scripts since your last deployment.
State-based version control allows database code to be held at the component level, with each table, view, or procedure being held separately, making merge conflicts less likely and easier to resolve if they do occur. Migration-based version control gives a much more granular level of control over scripts, which can be viewed and modified as required. The approach that is chosen tends to be based on team size, database complexity, and the amount of refactoring involved.