
What Is Industry 4.0?
Advances in technology continue to drive change in industrial operations. As businesses seek to leverage these advances, it’s important to understand how different technologies impact their operations. Instrumentation, i.e., the use of sensors to measure different aspects of a process, is a key area in the evolution of the industrial internet of things (IIoT). The data generated from sensors and applications have the potential to dramatically affect industrial processes; they generate a lot of data. Businesses need to understand the characteristics and shape of that data, as well as how to effectively analyze and apply it to drive improvements.
One shared characteristic of data generated by instrumentation is that it is time-stamped. Time-series data, therefore, functions as a critical piece in industrial observability and optimization. Industrial operators need to understand this type of data and how to work with it to maximize its vast potential. In this Refcard, we’ll discuss one of the key infrastructure components that contributes to IIoT success: a time-series database.
To understand why the time-series database is so integral, we’ll take a brief look at what is being labeled as “industry 4.0” and how it relates to IIoT. Next, we’ll discuss the characteristics of time-series data and why you should replace legacy data historians in order to achieve industry 4.0 goals. Finally, we turn our attention to getting started with open-source, time-series databases, how to ingest time-series data, and important considerations for building IIoT applications based on time-series data.
The industrial world is one that values consistency and predictability. The evolution of industrialization demonstrates this: What started with basic mechanization came to embrace the assembly line, followed by the use of computers and robots. Today, we’re in the midst of the fourth wave of the industrial revolution where autonomous systems being fed raw and trained data (i.e., machine learning) enhance manufacturing processes. The goal of automation at this level is to keep industrial production running efficiently and safely while minimizing downtime
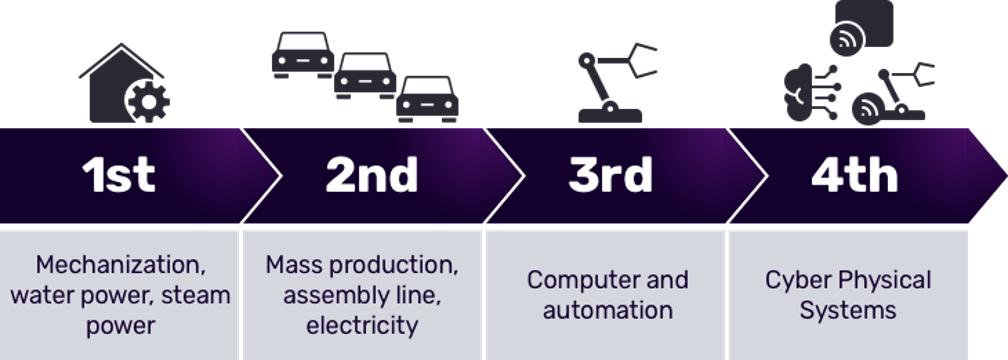
Industry 4.0 has a direct impact on IIoT because the technological tools and advances of industry 4.0 provide businesses with the data and analysis they need to make informed decisions about mission-critical processes. Instrumentation (i.e., putting sensors on things) is the heart of IIoT. These sensors generate large volumes of time-stamped data that tell businesses how their equipment, machines, and systems are functioning.
Time-series data, therefore, functions as a critical component of industry 4.0. Fortunately, the basic design principles behind industry 4.0 dovetail with the characteristics of time-series data:
- Interconnection – The ability to have devices, sensors, and people connect and communicate with each other.
- Information transparency – Interconnection allows for the collection of large amounts of data from all points of the manufacturing process. Making this data available to industrial operators provides them with an informed understanding that can aid in the identification of areas of innovation and improvement.
- Technical assistance – The ability to aggregate and visualize the data collected with a centralized dashboard allows industrial operators to make informed decisions and solve urgent issues on the fly. Furthermore, centralized data views help industrial operators avoid conducting a range of tasks that are unpleasant or unsafe for them to perform.
- Decentralized decisions – The ability for systems to perform their tasks autonomously based on data collected. These systems only require human input for exceptions.
Moving from 3.0 to 4.0
The shift to industry 4.0 is ongoing and presents many challenges. Oftentimes, it’s not possible or practical for businesses to implement wholesale upgrades to their industry 3.0 processes to make them compatible with industry 4.0 specifications. Such a piecemeal process exacerbates pre-existing issues with legacy systems.
A quick look at a typical enterprise control system stack helps to illustrate this challenge. Industrial organizations of all sizes all around the world work with any number of solutions to digitally transform their manufacturing processes. The following is a simple depiction of the enterprise control system stack as described by ISA-95.
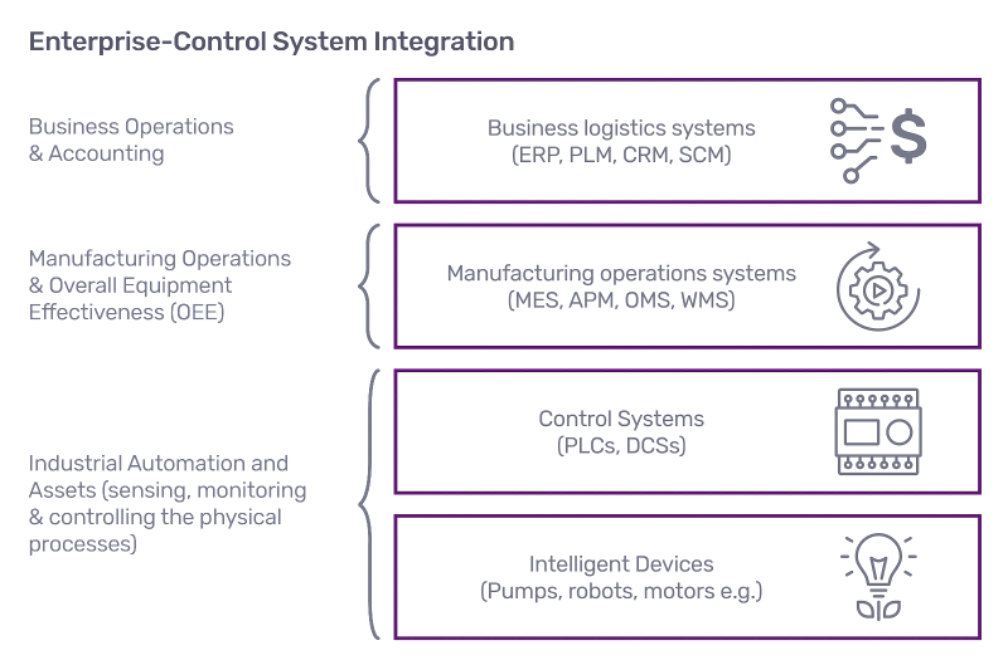
SCADA Systems
At the control systems level, a system of software and hardware components called Supervisory Control and Data Acquisition (SCADA) helps control machinery and systems in real time. These SCADA systems control processes locally by gathering and recording event data from sensors, valves, pumps, and motors. The SCADA system presents relevant data to the operator locally so that they can make decisions to keep machinery running optimally.
Many industries rely on SCADA systems — including energy producers, manufacturing, and food and beverage — to collect event data such as:
- Instrument readings (e.g., flow rate, valve position, temperature)
- Performance monitoring (e.g., units/hour, machine utilization vs. capacity, scheduled vs. unscheduled outages)
- Environmental readings (e.g., weather, atmospheric conditions, groundwater contamination)
- Production status (e.g., machine up/down, downtime reason tracking)