
What Is Event Stream Processing?
With an increasing number of connected, distributed devices, there has been a gradual shift in how data is processed and analyzed. The trend is also based on the growth of emerging technologies, such as the Internet of Things (IoT), microservices, and event-driven applications, which influence the development of real-time analytics.
This Refcard dives into how event stream processing represents this evolution by allowing continuous data analysis in the modern technology landscape.
Event stream processing (ESP) encompasses a set of tools and practices used to analyze and make decisions based on continuous data streams. Unlike traditional data analytics, ESP is modeled on an event-driven architecture that continuously gathers and processes data points (events), making it a highly efficient, scalable framework to process big data in real-time.
Similar to a microservice architecture, event stream processing utilizes services that share a common forum to perform tasks and interact with minimal shared knowledge of host services. Event stream processing implements this tell, don’t ask approach using a sink-and-source topology model. This can be explained further as:
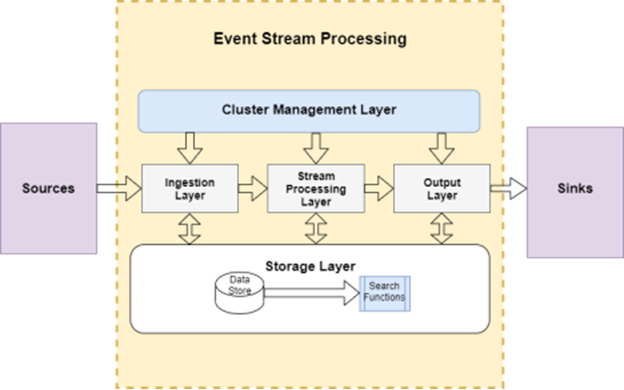
- A Source is an agent that generates and publishes an event.
- A Source Connector acts as the link between the source and the ESP processing application.
- A Sink acts as the storage platform to retain and exchange processed data.
- A Sink Connector is used by the Sink to exchange processed data with other sinks or processors.
- Sources and sinks are not directly linked; instead, the ESP processing application runs on a Stream Processing Engine (SPE).
- Sources’ data are ingested and published into the storage layer without knowledge of the intended sinks address, and vice versa, which enables decoupling in data-driven applications.
 Event stream processing using a sink-and-source topology
Event stream processing using a sink-and-source topology
Evolution and Industry Adoption
Due to increased demand for IoT, smart devices, and big data processing, cloud-based applications and emerging technologies are factors that have fueled the growth of event stream processing. As of 2018, event stream processing had a market size of $690 million, which is expected to grow at an annual rate of 21.6% to reach $1,838 million by 2023. Out of all the industries, though the trends have moderately fluctuated over the last several years, the largest adopters to date continue to be the banking, finance, and insurance sectors that leverage ESP to influence growth through real-time data analysis.
Event Stream vs. Batch Processing
Traditionally, applications employed batch processing to process data volumes in groups within a specified time interval. Such a model relied on a framework where data had to be retrieved, stored, and then processed/analyzed for future actions. Apart from this, because data was retrieved and stored in batches before analysis, batch processing systems did not allow efficient debugging of application errors. As a result, such systems were considered inefficient for the amount of time required to process data, as well as their inability to derive analytics in real-time for business functions where time is a major factor.
On the contrary, event stream processing ingests, processes, and analyzes data streams in real-time. To do so, the ESP processor uses in-memory processing, pre-stored queries, and efficient analysis algorithms that allow data to be processed immediately the moment it is received.
Apart from the basic differences above, there are other fundamental differences between how event streams and traditional batch processing operate. These include:
- A batch processing system does not immediately push incoming data into the processor, thereby making it incapable of real-time processing. Event stream processing, on the other hand, relies on passive queries to instantly analyze incoming data to enable continuous, real-time data analytics.
- At its elemental level, batch processing systems operate on disk storage data such as a filesystem or relational database. When processing data, I/O functions from disk storage prove to be an inefficient, time-constraining model, particularly known for the significant time lag. On the contrary, ESP leverages efficient in-memory processing by utilizing system RAM, flash memory, or in-memory databases that allow high IOPS for faster data processing.
When to Use
Batch processing involves the collection of data sets over time, which are then pushed to the analytics system in batches. This makes it particularly useful for large volumes of static data that are generated and collected over a longer period of time. Batch processing is considered best where the results of processing analytics are not needed in real-time, and the requirement is to use a simple, efficient system that automates analytics to improve data quality.
Some popular use cases of batch processing include:
- Billing information generators
- Payroll processing systems
- Data processing systems that frequently work offline
Event stream processing analyzes streaming data instantaneously, making it useful for high-velocity applications that generate events frequently or a business model that relies on real-time data analysis. This makes ESP perfect for agile, time-critical applications such as:
- Stock market operations
- Air traffic control
- Automated teller machines
- RFID-based identification
- Vehicle sensor systems
Benefits of Event Stream Processing
ESP solutions act as critical enablers for organizations that rely on large amounts of continuous data to derive business decisions. As technology continues to evolve, applications are designed to churn out a wide variety of data per second, including server logs, application clickstreams, real-time user behavior, and social media feeds. While processing distinct data efficiently is one of the key features of ESP, the following are some of the benefits organizations achieve while embracing an ESP framework:
Analysis and Processing of Big Data
ESP enables data to be captured and fed into analytics for instant processing and results. This is achieved by utilizing in-memory processing and continuous computation to process and analyze data constantly flowing through the system without limiting output time. Additionally, by leveraging in-memory processing, organizations can process enormous amounts of data instantaneously without the need to provision large data storage systems.
Real-Time Decision-Making
Events denote data points, while a stream denotes the continuous delivery of those events. By creating attributable data points, ESP makes it possible to visualize and present the incoming streams of data in real-time. This data can then be displayed on interactive dashboards or passed down to other processors for real-time decision-making. As a result, ESP applications are considered suitable for traffic monitoring, fraud detection, incident reports, and other functionalities that rely on instantaneous decision-making.
Continuous Event Monitoring
The ESP framework is built to analyze large volumes of data flowing through multiple data sources continuously. Every time a system’s state changes, the ESP records an event. The stream processing engine applies algorithms to aggregate event-based data, revealing key trends so that administrators can detect patterns and identify errors.
Ultra-Low Latency
One of the primary goals of stream processing is to allow real-time data analytics and processing for highly distributed, high-velocity applications. Besides this, as the architecture is built to adjust to changes in data patterns without affecting latency, ESP is considered ideal for applications requiring sub-second latency for workstreams, such as surveillance, robotics, and vehicle automation.
Streaming SQL
By using Streaming SQL, an ESP architecture enables a continuous query model for real-time analytics on a continuous stream of events. This allows organizations to utilize the declarative nature of SQL to filter, transform, aggregate, and enrich streams of rapidly changing data.
Complements Edge Computing
ESP emphasizes real-time data collection through an adapter at the source processor. With the tell, don’t ask approach, ESP eliminates the need for a central, shared database. This reduces a round-trip to a server/database/cloud, enabling faster and advanced analytics for edge devices.