
Introduction
Today's business and user requirements demand applications that connect more and more of the world's data, yet still expect high levels of performance and data reliability.
Many applications of the future will be built using graph databases like Neo4j. This Refcard was written to help you—a developer with relational database experience—through every step of the learning process. We will use the widely adopted property graph model and the open Cypher query language in our explanations, both of which are supported by Neo4j.
When Relational Databases Don't Fit Into Today’s Application Development
For several decades, developers have tried to manage connected, semi-structured datasets within relational databases. But, because those databases were initially designed to codify paper forms and tabular structures—the "relation" in relational databases refers to the definition of a table as a relation of tuples—they struggle to manage rich, real-world relationships.
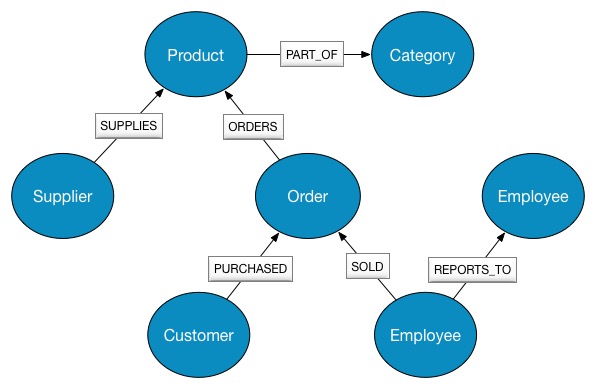
For example, take a look at the following relational model:
The Northwind application exerts a significant influence over the design of this schema, making some queries very easy and others more difficult. While the strength of relational databases lies in their abstraction— simple mathematical models work for all use cases with enough JOIN— in practice, maintaining foreign key constraints and computing more than a handful of JOINs becomes prohibitively expensive.
Although relational databases perform admirably when asked questions such as "What products has this customer bought?," they fail to answer recursive questions such as "Which customers bought this product who also bought that product?"
Graph Databases: Advantages of a Modern Alternative
Relationships Should Be First-class Citizens
Graph databases are unlike other databases that require you to guess at connections between entities using artificial properties such as foreign keys or out-of-band processing like MapReduce. In the graph model, however, relationships are first-class citizens.
Creating connected structures from simple nodes and their relationships, graph databases enable you to build models that map closely to your problem domain. The resulting models are both simpler and more expressive than those produced using relational databases.
JOINs Are Expensive
JOIN-intensive query performance in relational databases deteriorates as the dataset gets bigger. In contrast, with a graph database, performance tends to remain relatively constant, even as the dataset grows. This is because queries are localized to a portion of the graph. As a result, the execution time for each query is proportional only to the size of the part of the graph covered to satisfy that query, rather than the size of the overall data.
Graph Model Components
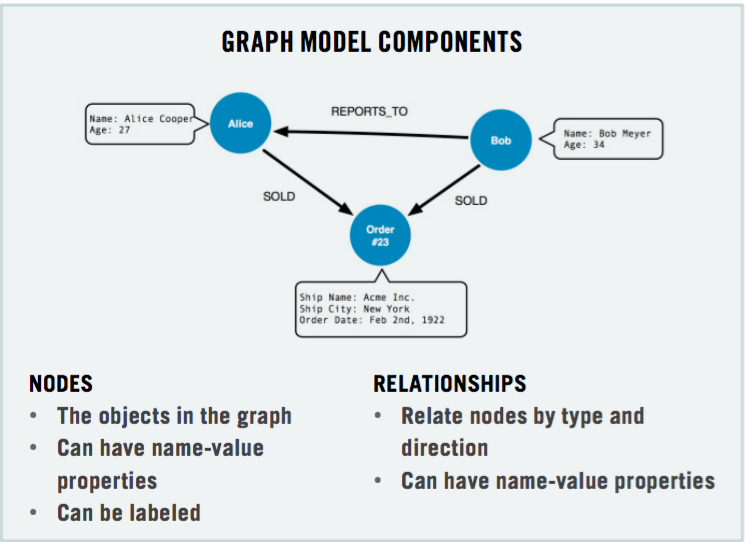
Data Modeling: Relational and Graph Models
If you're experienced in modeling with relational databases, think of the ease and beauty of a well-done, normalized entity-relationship diagram: a simple, easy-to-understand model you can quickly whiteboard with your colleagues and domain experts. A graph is exactly that: a clear model of the domain, focused on the use cases you want to efficiently support.
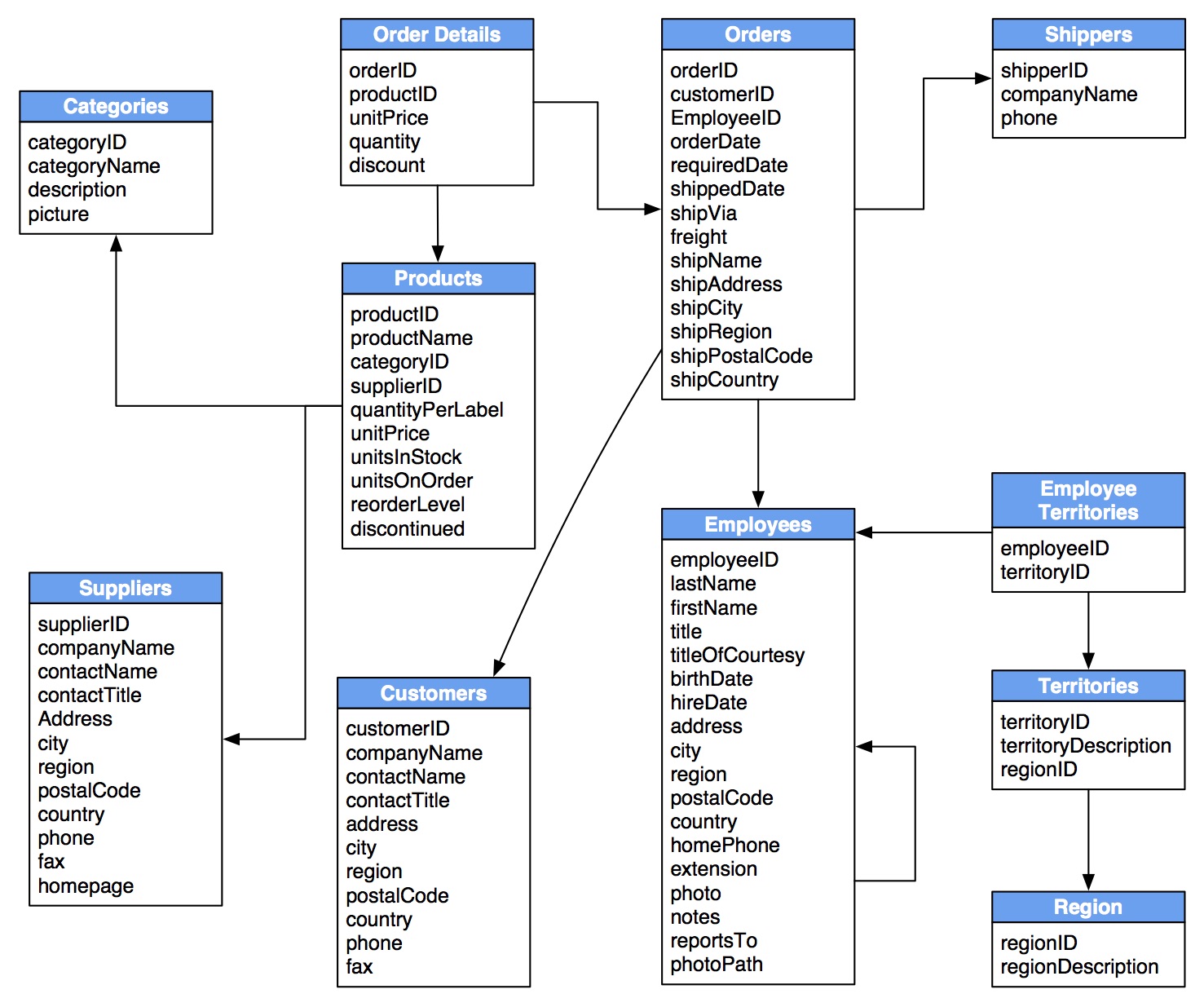
The Northwind Dataset
This guide will be using the Northwind dataset, commonly used in SQL examples, to explore modeling in a graph database:
Developing the Graph Model
The following guidelines describe how to adapt this relational database model into a graph database model:
Locate Foreign Keys
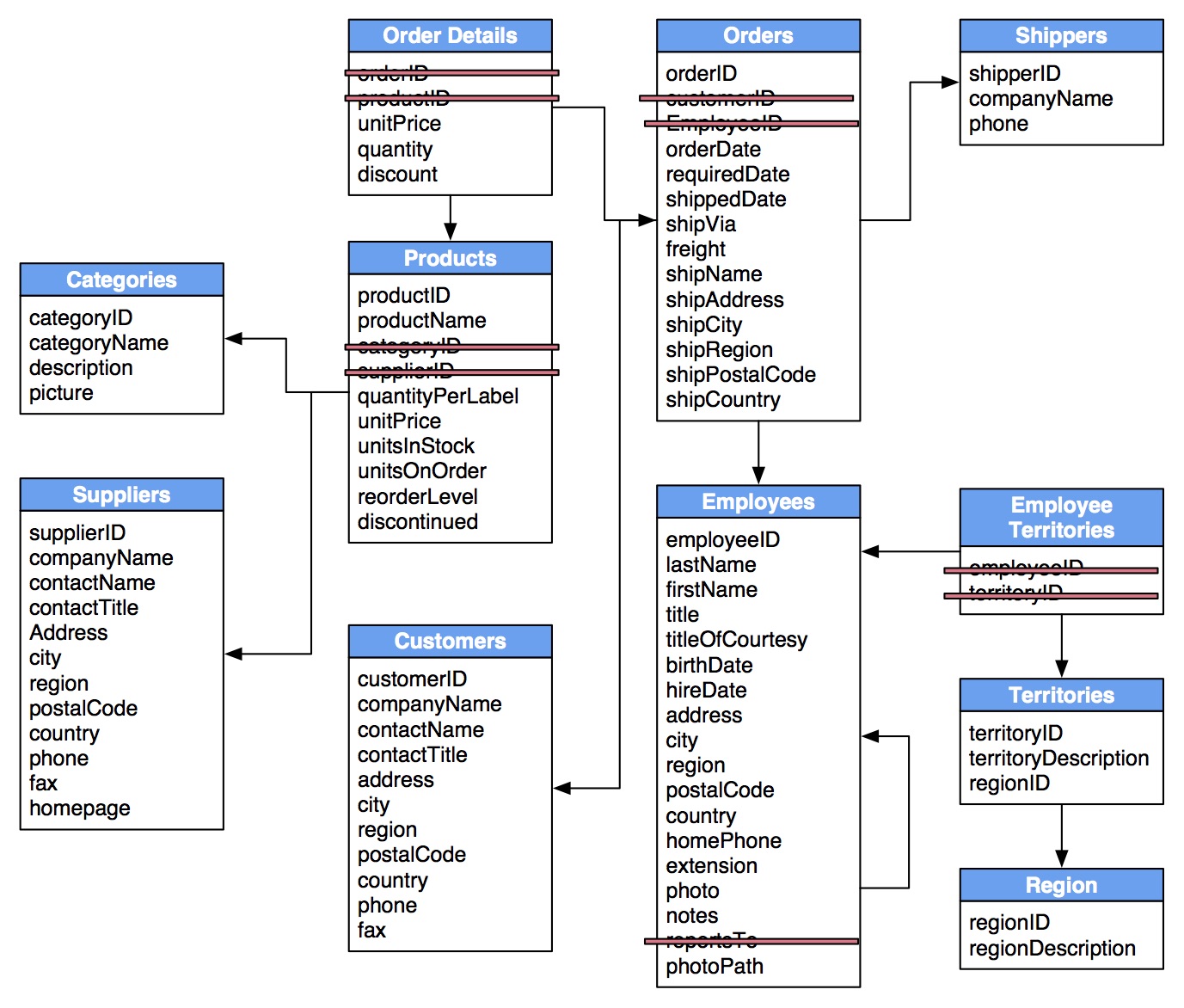
Foreign Keys Become Relationships
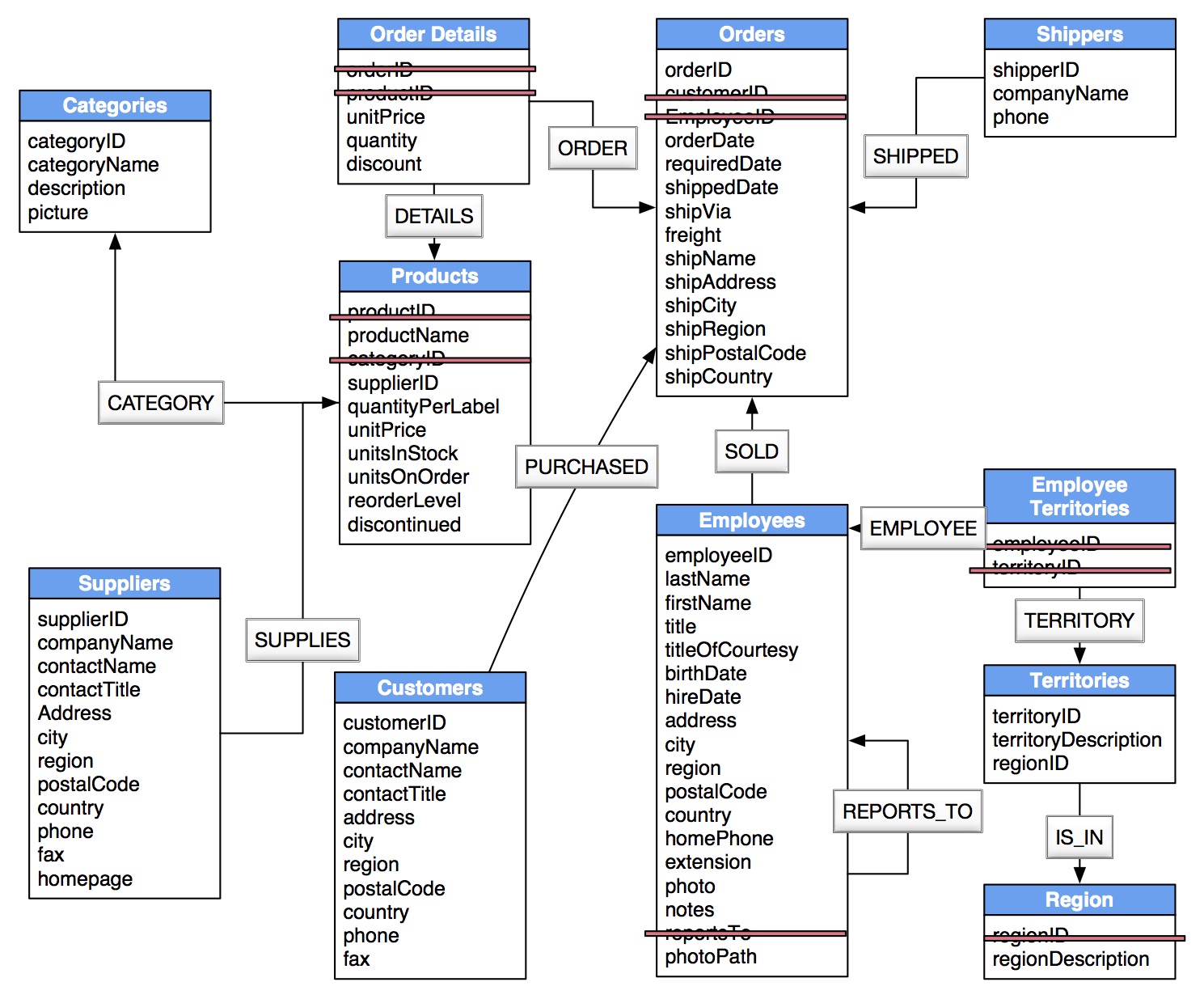
Simple JOIN Tables Become Relationships
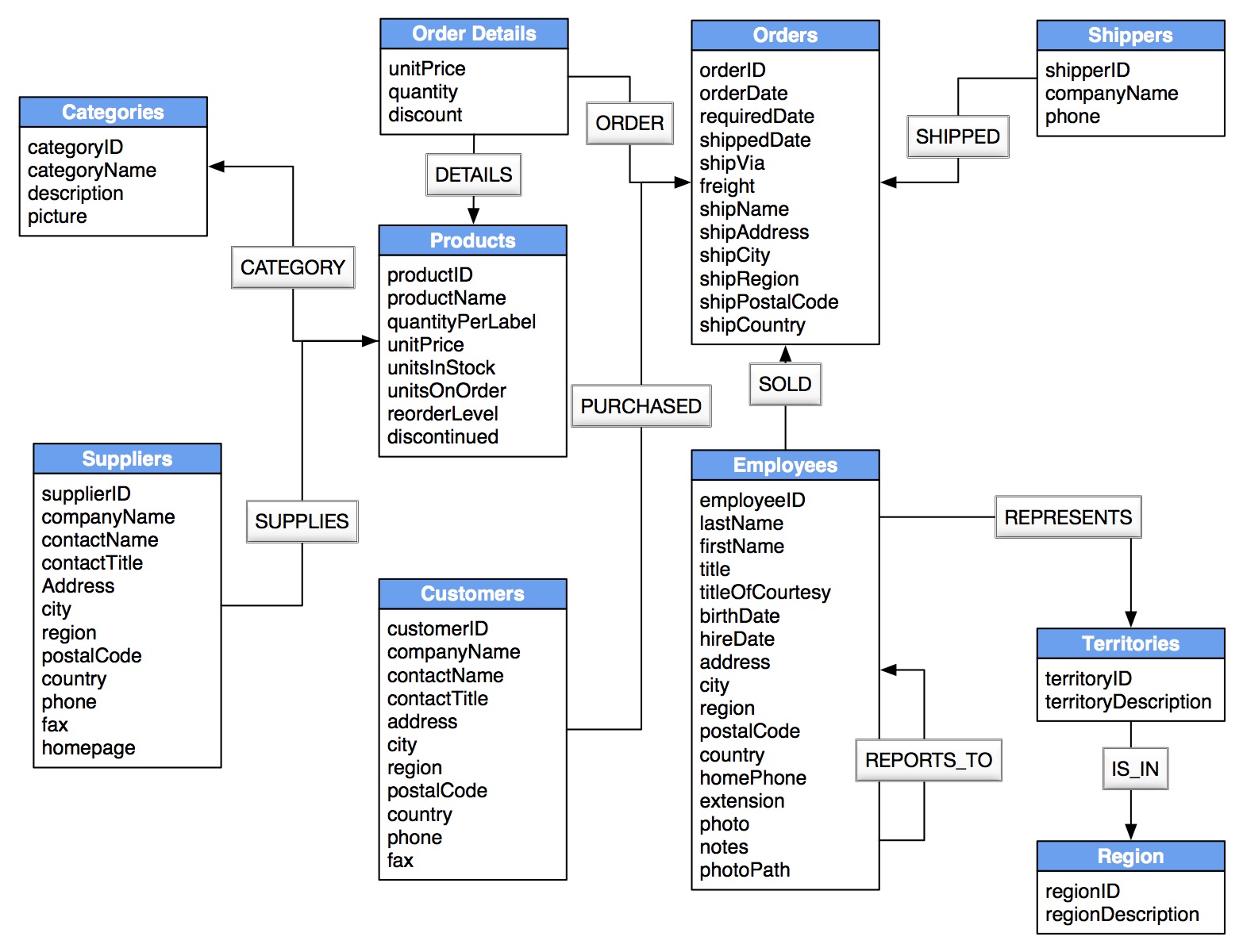
Attributed JOIN Tables Become Relationships with Properties
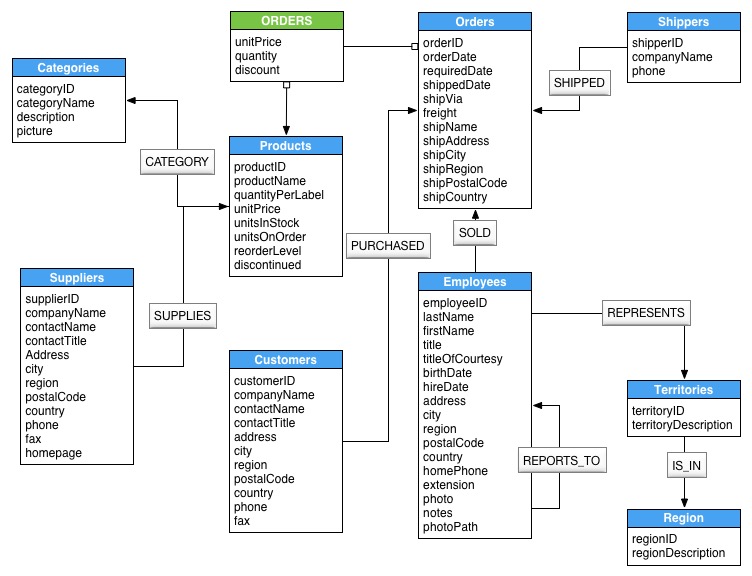
The Northwind Graph Data Model
How does the Northwind Graph Model Differ from the Relational Model?
- No
nulls: non-existing value entries (properties) are just not present - The graph model has no JOIN tables or artificial primary or foreign keys
- Relationships are more detailed. For example, it shows an employee SOLD an order without the need of an intermediary table.
Exporting the Relational Data to CSV
With the model defined and the use case in mind, data can now be extracted from its original database and imported into a Neo4j graph database. The easiest way to start is to export the appropriate tables in CSV format. The PostgreSQL copy command lets us execute a SQL query and write the result to a CSV file, e.g., with
psql -d northwind < export_csv.sql: export_csv.sql

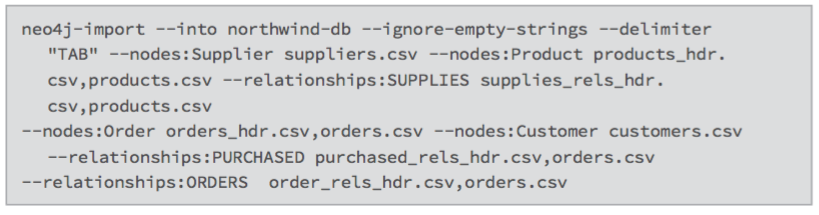
Bulk-Importing CSV Data Using the neo4j-import Tool
Neo4j provides a bulk import tool that can import billions of nodes and relationships. It utilizes all CPU and disk resources, adding at least one million records per second into the database. It consumes large, also compressed CSV files with a specific header configuration to indicate mapping instructions.
|
Import Tool Facts
|
Nodes
Groups
The import tool assumes that node identifiers are unique across node files. If this isn't the case then you can define groups, defined as part of the ID field of node files.
For example, to specify the Person group you would use the field header ID(Person) in your persons node file. You also need to reference that exact group in your relationships file, i.e., START_ID(Person) or END_ID(Person).
In this Northwind example, the suppliers.csv header would be modified to include a group for Supplier nodes:
Original Header:

Modified Header:

Property Types
Property types for nodes and relationships are set in the header file (e.g., :int, :string, :IGNORE, etc.). In this example, supplier.csv would be modified like this:

Labeling Nodes
Use the LABEL header to provide the labels of each node created by a row. In the Northwind example, one could add a column with header LABEL and content Supplier, Product, or whatever the node labels are. As the supplier.csv file represents only nodes for one label (Supplier), the node label can be declared on the command line.

Relationships
Relationship data sources have three mandatory fields:
TYPE: The relationship type to use for the relationshipSTART_ID: The id of the start node of the relationship to createEND_ID: The id of the end node of the relationship to create
In the case of this dataset, the products.csv export from the relational database can be repurposed to build the (:Supplier)-[:SUPPLIES]->(:Product) relationships in the graph database.
Original products.csv header:

Products.csv header modified to create the supplies_rels_hdr.csv header:

As every row in the input file is of the same relationship type, the TYPE is set on the command line.
Applying the same treatment to the customers.csv and orders.csv and creating purchased.csv and orders_rels.csv allows for the creation of a usable subset of the data model. Use the following command to import the data: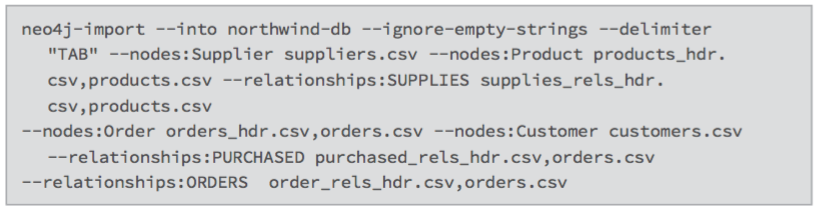
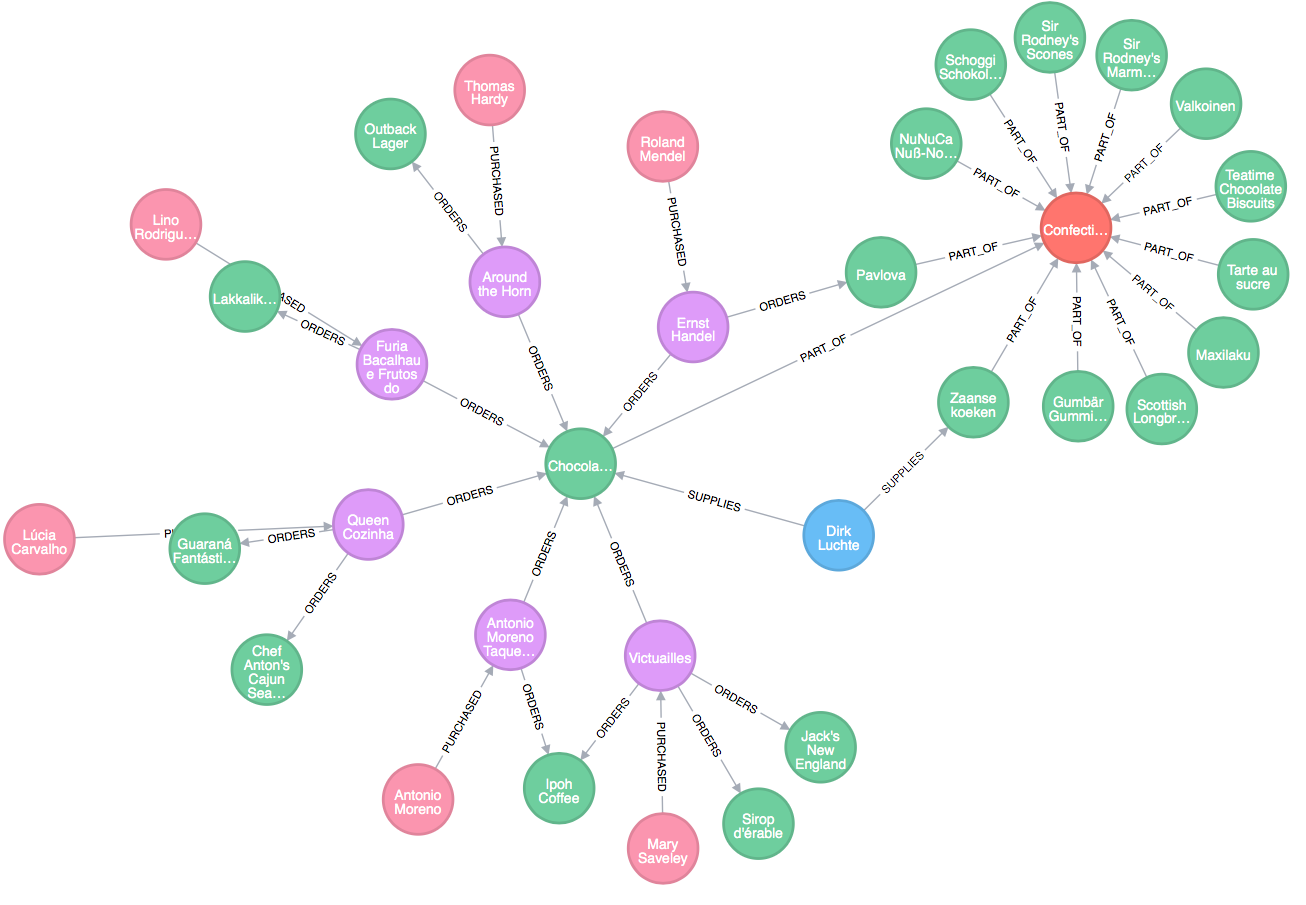
Updating the Graph
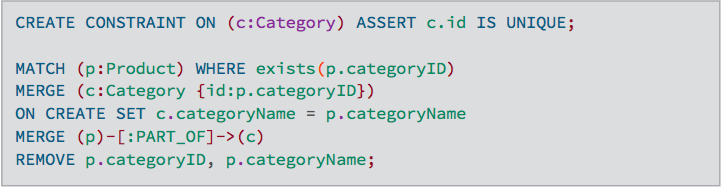
Now that the graph has data, it can be updated using Cypher, Neo4j's open graph query language, to generate categories based on the categoryID and categoryName properties in the product nodes. The query below creates new category nodes and removes the category properties from the product nodes.
Query Languages: SQL vs. Cypher
Language Matters
Cypher is about patterns of relationships between entities. Just as the graph model is more natural to work with, so is Cypher. Borrowing from the pictorial representation of circles connected with arrows, Cypher allows any user, whether technical or non-technical, to understand and write statements expressing aspects of the domain.
Graph database models not only communicate how your data is related, but they also help you clearly communicate the kinds of questions you want to ask of your data model.
Graph models and graph queries are two sides of the same coin.
SQL vs. Cypher Query Examples
Find All Products
Select and Return Records

In SQL, just SELECT everything from the products table. In Cypher, MATCH a simple pattern: all nodes with the label :Product, and RETURN them.
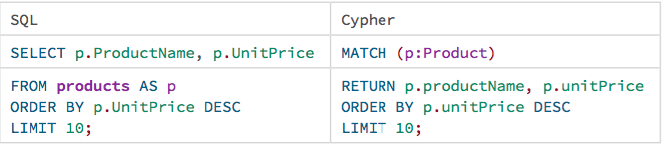
Field Access, Ordering, and Paging
It is more efficient to return only a subset of attributes, like ProductName and UnitPrice. You can also order by price and only return the 10 most expensive items.

Find Single Product by Name
Filter by Equality
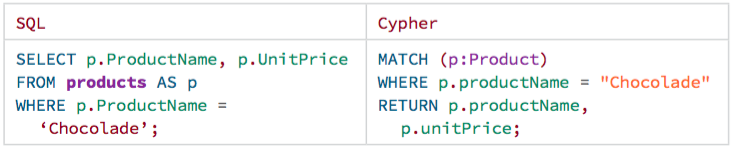
To look at only a single Product, for instance, Chocolade, filter the table in SQL with a WHERE clause. Similarly, in Cypher the WHERE belongs to the MATCH statement. Alternatively, you can use the following shortcut:

You can also use any other kind of predicates: text, math, geospatial, and pattern comparisons. Read more on the Cypher Refcard.
Joining Products With Customers
JOIN Records, DISTINCT Results
In order to see who bought Chocolade, JOIN the four necessary tables (customers, orders, order_details, and products) together:

The graph query is much simpler:

New Customers Without Orders
Outer JOINs and Aggregation
To ask the relational Northwind database What have I bought and paid in total? use a similar query to the one above with changes to the filter expression. However, if the database has customers without any orders and you want them included in the results, use OUTER JOINs to ensure results are returned even if there were no matching rows in other tables.
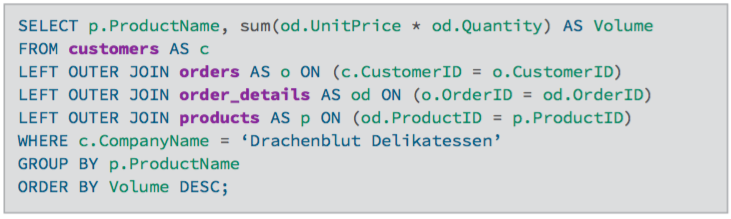
In the Cypher query, the MATCH between customer and order becomes an OPTIONAL MATCH, which is the equivalent of an OUTER JOIN. The parts of this pattern that are not found will be NULL.

As you can see, there is no need to specify grouping columns. Those are inferred automatically from your RETURN clause structure.
|
When it comes to application performance and development time, your database query language matters. SQL is well-optimized for relational database models, but once it has to handle complex, connected queries, its performance quickly degrades. In these instances, the root problem lies with the relational model, not the query language. For domains with highly connected data, the graph model and their associated query languages are helpful. If your development team comes from an SQL background, then Cypher will be easy to learn and even easier to execute. |
Importing Data Using Cypher's LOAD CSV
The easiest (though not the fastest) way to import data from a relational database is to create a CSV dump of individual entity-tables and JOIN-tables. After exporting data from PostgreSQL, and using the import tool to load the bulk of the data, the following example will use Cypher's LOAD CSV to move the model's remaining data into the graph. LOAD CSV works both with single-table CSV files as well as with files that contain a fully denormalized table or a JOIN of several tables. The example below uses the LOAD CSV command to:
- Add Employee nodes
- Create Employee-Employee relationships
- Create Employee-Order relationships
Create Constraints
Unique constraints serve two purposes. First, they guarantee uniqueness per label and property value combination of one entity. Second, they can be used for determining nodes of a matched pattern by property comparisons.
Create constraints on the previously imported nodes (Product, Customer, Order) and also for the Employee label that is to be imported:

Note that a constraint implies an index on the same label and property. These indices will ensure speedy lookups when creating relationships between nodes.
Create Indices
To quickly find a node by property, Neo4j uses indexes on labels and properties. These indexes are also used for range queries and text search.

Create Employee Nodes and Relationships
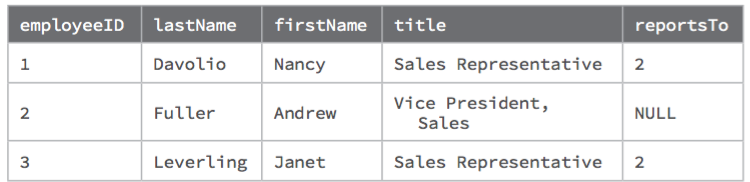



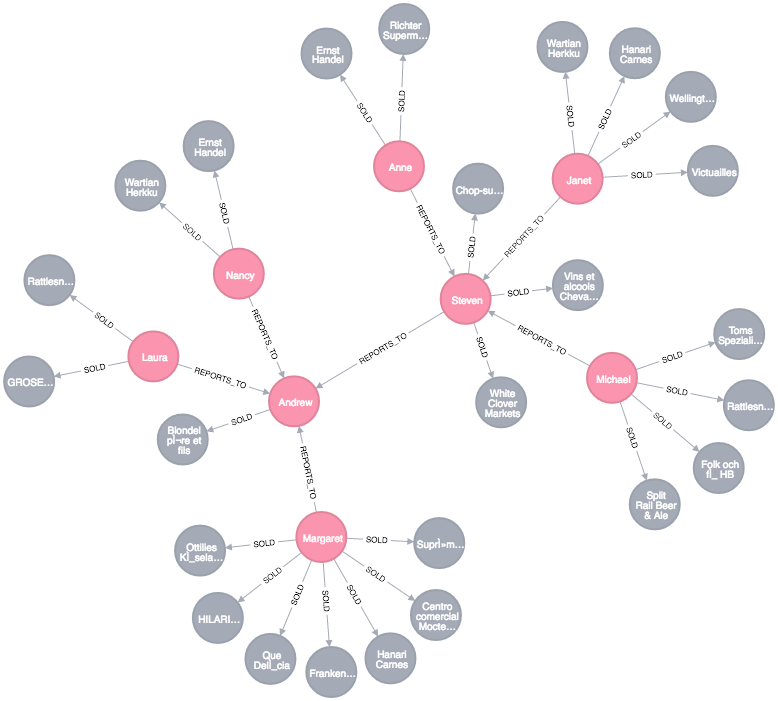

Updating the Graph
To update the graph data, find the relevant information first, then update or extend the graph structures.
Janet is now reporting to Steven
Find Steven, Janet, and Janet's REPORTS_TO relationship. Remove Janet’s existing relationship and create a REPORTS_TO relationship from Janet to Steven.
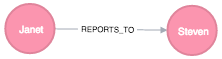
This single relationship change is all you need to update a part of the organizational hierarchy. All subsequent queries will immediately use the new structure.
LOAD CSV Considerations
- Provide enough memory (heap and page-cache)
- Test with small batch first to verify the data is clean
- Create indexes and constraints upfront
- Use Labels for matching
- Use
DISTINCT,SKIP, and/orLIMITon row data, to control input data volume - Use
PERIODIC COMMITfor larger volumes (> 20k)
Drivers and Neo4j: Connecting to Neo4j With Language Drivers
Introduction
If you've installed and started Neo4j as a server on your system, you can interact with the database via the console or the built-in Neo4j Browser application. Neo4j's Browser is the modern answer to old-fashioned relational workbenches, a web application running in your web browser to allow you to query and visualize your graph data.
Naturally, you'll still want your application to connect to Neo4j through other means—most often through a driver for your programming language of choice. The Neo4j Driver API is the preferred means of programmatic interaction with a Neo4j database server. It implements the Bolt binary protocol and is available in four officially supported drivers for C#/.NET, Java, JavaScript, and Python. Community drivers exist for PHP, C, Go, Ruby, Haskell, R, and others.
Bolt is a connection-oriented protocol that uses a compact binary encoding over TCP or web sockets for higher throughput and lower latency. The API is defined independently of any programming language. This allows for a high degree of uniformity across languages, which means that the same features are included in all the drivers. The uniformity also influences the design of the API in each language. This provides consistency across drivers, while retaining affinity with the idioms of each programming language.
Connecting to Neo4j Using the Official Drivers
Getting Started
You can download the driver source or acquire it with one of the dependency managers of your language.
| Language | Snippet |
|
C# |
Using NuGet in Visual Studio:
|
| Java |
When using Maven, add this to your pom.xml file:
For Gradle or Grails, use:
For other build systems, see information available at Maven Central. |
| JavaScript | npm install [email protected] |
| Python | pip install neo4j-driver==1.0.0 |
Using the Drivers
Each Neo4j driver uses the same concepts in its API to connect to and interact with Neo4j. To use a driver, follow this pattern:
- Ask the database object for a new driver.
- Ask the driver object for a new session.
- Use the session object to run statements. It returns a statement result representing the results and metadata.
- Process the results, optionally close the statement.
- Close the session.
Example:


A Closer Look: Using Neo4j Server With JDBC
If you’re a Java developer, you’re probably familiar with Java Database Connectivity (JDBC) as a way to work with relational databases. This is done either directly or through abstractions like Spring’s JDBCTemplate or MyBatis. Many other tools use JDBC drivers to interact with relational databases for business intelligence, data management, or ETL (Extract, Transform, Load).
Cypher—like SQL—is a textual and parameterizable query language capable of returning tabular results. Neo4j easily supports large parts of the JDBC APIs through a Neo4j-JDBC driver. The Neo4j-JDBC driver is based on the Java driver for Neo4j’s binary protocol and offers read and write operations, transaction control, and parameterized prepared statements with batching.
JDBC Driver Example
Class.forName("neo4j.jdbc.Driver");
Connection con = DriverManager.getConnection("jdbc:bolt://localhost");
String query = "MATCH (p:Product)<-[:ORDERS]-()<-[:PURCHASED]-(c) " +
"WHERE p.productName = {1} RETURN c.name,
count(*) as freq";
try (PreparedStatement stmt = con.prepareStatement(query))
{
stmt.setString(1,"Chocolade");
ResultSet rs = stmt.executeQuery();
while (rs.next()) {
System.out.println(rs.getString("c.name")+" "+rs.getInt("freq"));
}
}
con.close();Development and Deployment: Adding Graphs to Your Architecture
Make sure to develop a clean graph model for your use case first, then build a proof of concept to demonstrate the added value for relevant parties. This allows you to consolidate the import and data synchronization mechanisms. When you're ready to move ahead, you'll integrate Neo4j into your architecture both at the infrastructure and the application level.
Deploying Neo4j as a database server on the infrastructure of your choice is straightforward, either in the cloud or on premise. You can use our installers, the official Docker image, or available cloud offerings. For production applications you can run Neo4j in a clustered mode for high availability and scaling. As Neo4j is a transactional OLTP database, you can use it in any end-user facing application.
Using efficient drivers to connect from your applications to Neo4j is no different than with other databases. You can use Neo4j's powerful user interface to develop and optimize the Cypher queries for your use case and then embed the queries to power your applications.
If you augment your existing system with graph capabilities, you can choose to either mirror or migrate the connected data of your domain into the graph. Then you would run a polyglot persistence setup, which could also involve other databases, e.g., for textual search or offline analytics.
If you develop a new graph-based application or realize that the graph model is the better fit for your needs, you would use Neo4j as your primary database and manage all your data in it.
Architectural Choices
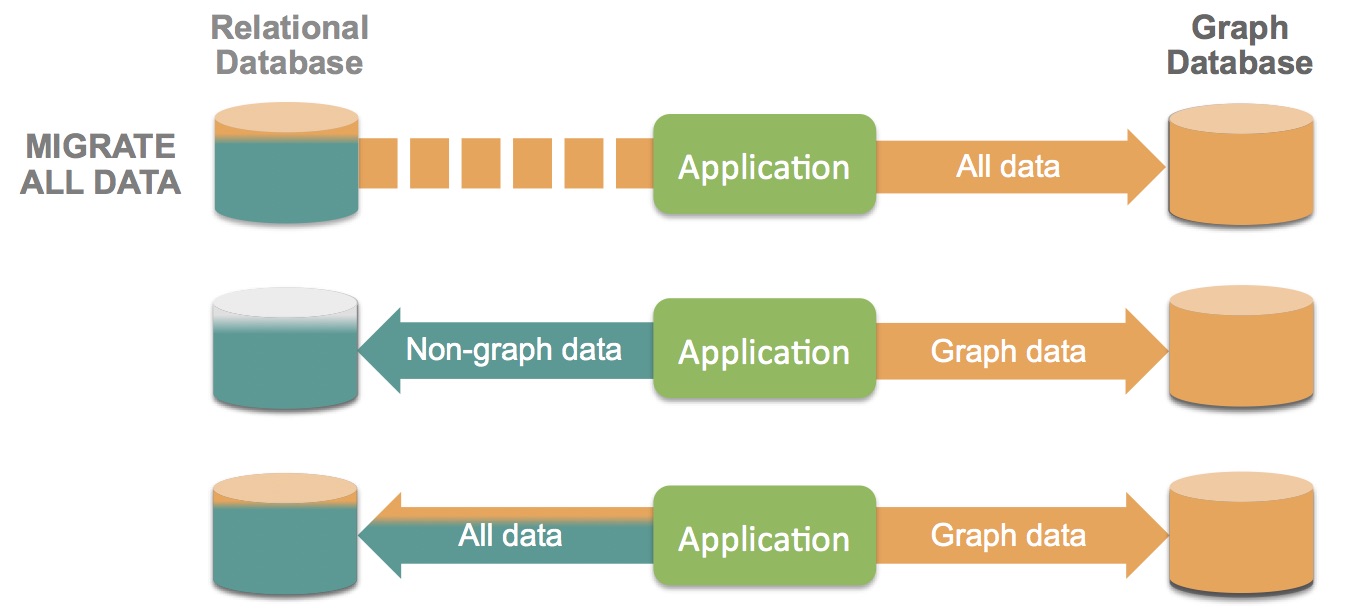
The three most common paradigms for deploying relational and graph databases
For data synchronization, you can rely on existing tools or actively push to or pull from other data sources based on indicative metadata.
Additional Resources
Relational Databases vs. Graph Databases
A relational model of data for large shared data banks (PDF)
SQL vs. Cypher
Data Import
Neo4j Bulk Import Tool Documentation
Neo4j Bolt Drivers
Introducing Bolt, Neo4j’s Upcoming Binary Protocol
Neo4j JDBC Driver 3.x: Bolt it with LARUS!
Neo4j Deployment and Development