Well-Defined Specification
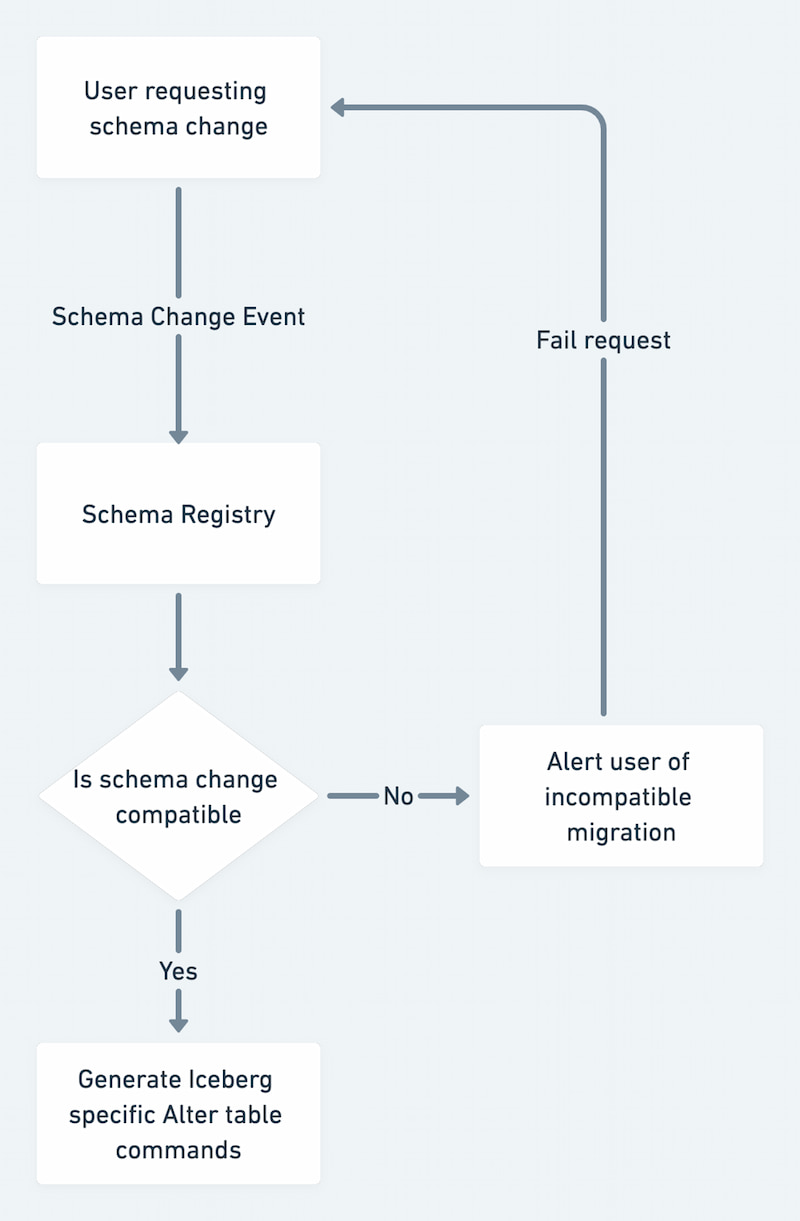
Iceberg’s community-driven specification is fundamental to the project’s success. The specification defines the expected semantics for each feature and gives clients a framework for developing specific implementation. It relies on definition rather than convention to ensure that all implementing clients have consistent behavior. Versions 1 and 2 are ratified and currently in use in the codebase, while version 3 is still in development.
Version boundaries may break forward compatibility in the following way: Older readers cannot read tables written by a newer writer. However, newer readers are able to read tables written by older writers. The expected metadata changes for each version are outlined here.
Iceberg Specification V1
The initial Iceberg specification is oriented around managing large, analytic tables using open file formats such as Parquet, ORC, and Avro. The main goals are to provide a performant, predictable, and flexible abstraction for interacting with large scale data. A key feature enabling these goals is a distributed hierarchical metadata structure. A self-contained, distributed metadata allows job planning to be pushed to clients and removes the bottlenecks of a central metastore.
The main objects in this hierarchy are as follows:
- TableMetadata – Information about schema, partitioning, properties, and current and historical snapshots
- Snapshot – Contains information about the manifests that compose a table at a given point in time
- Manifest – A list of files and associated metadata such as column statistics
- Data Files – Immutable files stored in one of the support file formats
Iceberg Specification V2
V2 focuses on providing capabilities around row-level deletion. Deletions on immutable files are accomplished by writing delete files that specify the deleted rows in one of two formats, either position-based or equality-based.
Position-based deletes provide a file path and row ordinal to determine which rows are considered for deletion. To improve file scan performance, entries in the delete file must be sorted by file path and ordinal. This allows for effective predicate pushdown in columnar formats. Optionally, the delete file may contain the deleted data row values.
Delete files using the equality-based approach contain a row for each expression that are used to match delete rows. The expression is constructed by using a list of equality_ids, where id is the column field_id, and a matching row that contains all of the equality_ids and optionally additional fields.
For example, a deletion where country_code='US' could be encoded as either of the following:
equality_ids=[3]
country_code: 3 |
---------------------
US |
Or:
equality_ids=[3]
customer_id: 1 | event_ts: 2 | country_code: 3
------------------------------------------------------------
12345 | 2022-01-01 00:00:00 | US
Self-Contained Metadata
Iceberg’s metadata is defined using the native file abstractions for the file store used in a specific implementation. The only external service needed is the catalog. The catalog implementation requires a mechanism for atomically swapping the pointer to the current table metadata location. The entire state of a table is contained in a hierarchical tree of immutable files.
Listing is expensive in both S3 and HDFS. This cost is removed in Iceberg since the set of files is enumerated as a union of manifest entries. Planning is done by making parallel O(1) RPC calls instead of an O(N) listing of directories.
Snapshots contain an immutable set of files. This means that readers will always have a consistent view of a table without holding any lock. Readers will not see any different data until a new snapshot is committed and a new read operation is initiated.
Removes issues of previous designs:
- Expensive listing operations
- Listing consistency
- Provide the ability for table data to not conform to a single path
- Commit retries
- Multiple levels of statistics available
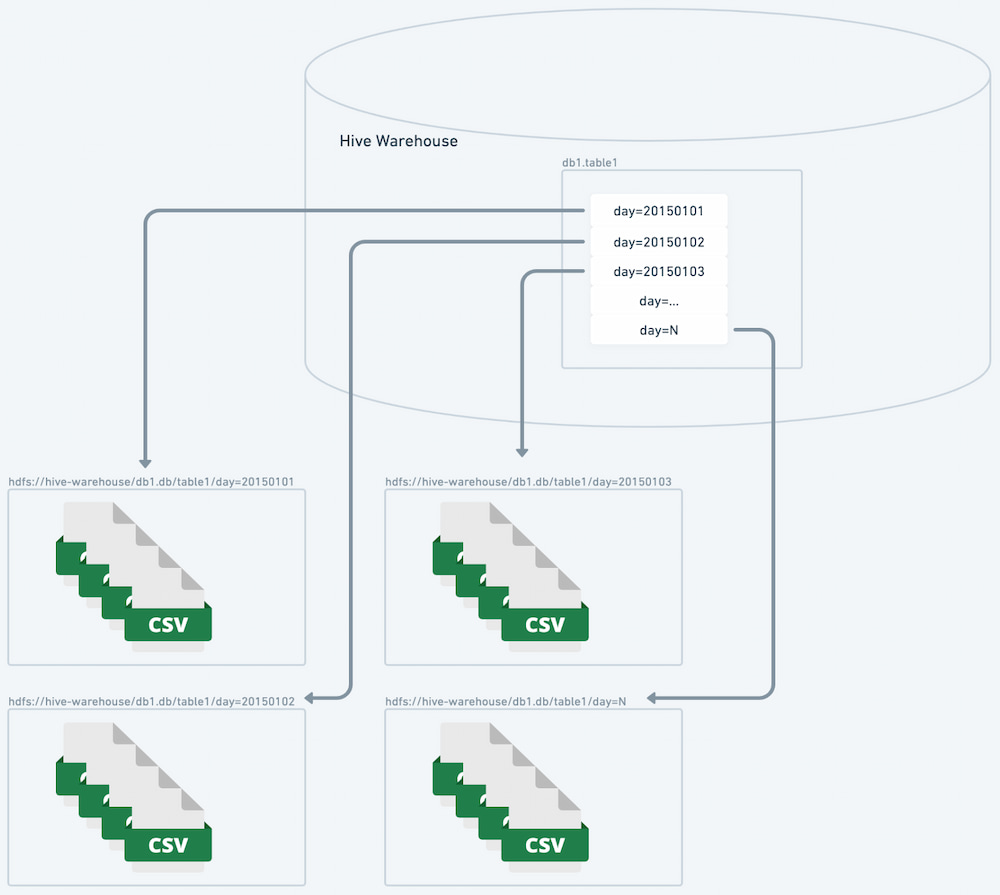
Hidden Partitioning
Hidden partitioning is a significant simplification improvement over the partitioning capabilities offered by Hive. As a concrete example, for a table with a timestamp column, the day transform can be applied to give partitions at the day grain.
Figure 2: Applying the day partition transform function
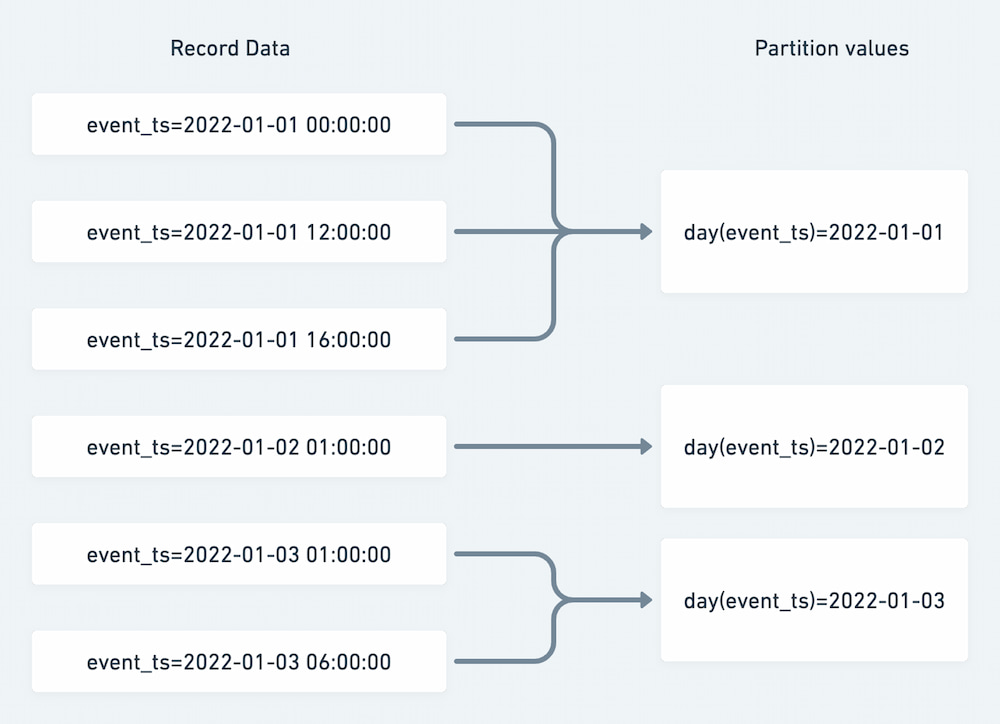
There are several benefits of this design. First, the mapping is applied directly to existing column data — no additional columns are needed to create the desired partition granularity. Producers and consumers do not need to take any additional action to ensure that partitioning is applied. Additionally, all partition resolution is an O(1) RPC call and can be planned in parallel.
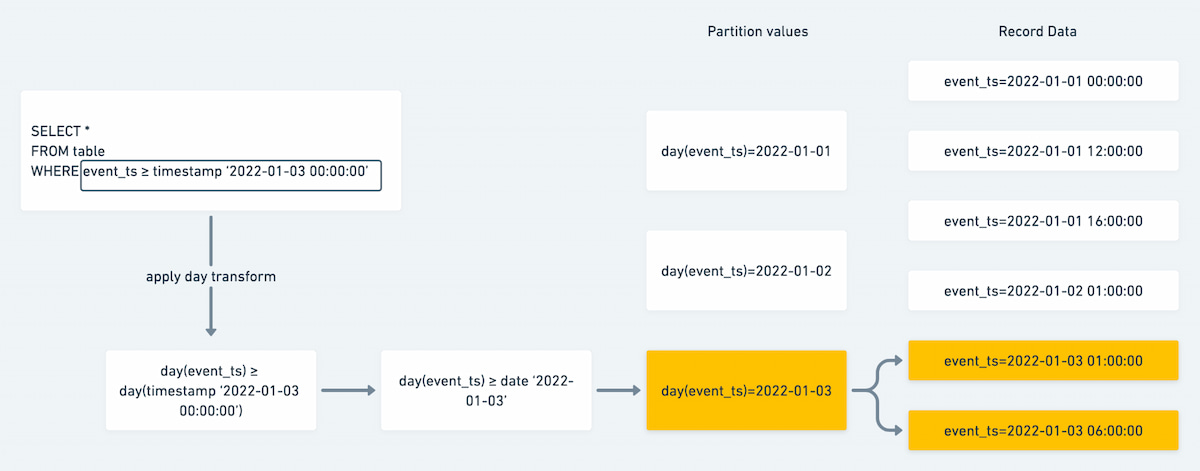
Figure 3: Partition predicate evaluation
Linear Snapshot History
A fundamental problem with the Hive table format is that there is no native concept of table history. The table is simply whatever files happen to be in the defined paths at a given point in time. An early goal of Iceberg was to provide metadata primitives for tracking table state over time and decoupling the active state from the table paths. This is accomplished through the snapshot and snapshot log. There can only be one current snapshot; however, there may be many snapshots in the log, both historical snapshots and yet-to-be-committed snapshots. This provides a linear history of the table state. The lineage of changes in a table is available by traversing backwards from child snapshot to parent snapshot until the point in time of interest.
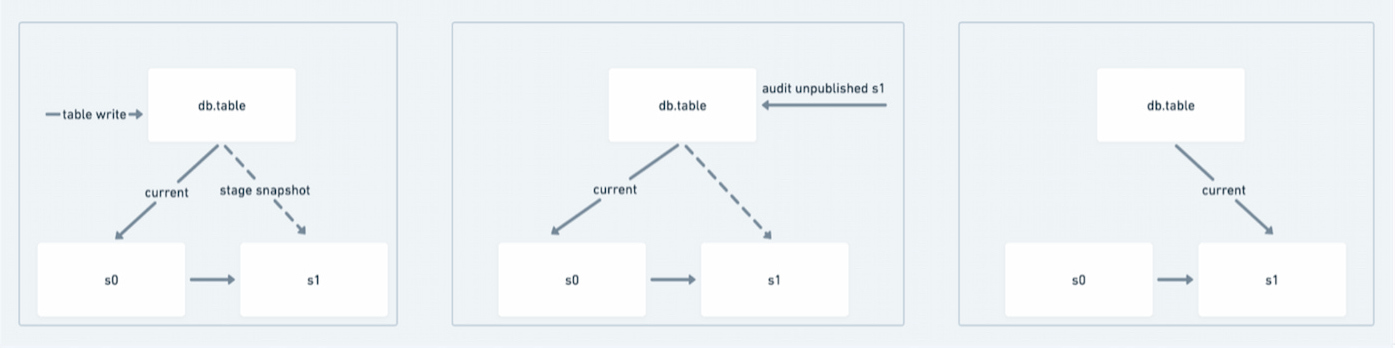
WAP
It is now possible to service write-audit-publish workflows. Write-audit-publish (WAP) is a pattern where data is written to a table but is not initially committed. Then validation logic occurs — if validation succeeds, the uncommitted snapshot is promoted to the current table version. Downstream readers will never see data that has not passed validation.
Figure 4: WAP pipeline
Time Travel
Time travel queries are supported by reading previous snapshots, which give a point-in-time view of table state. End users are able to reconcile data changes at various points in a table's history through a simple interface provided by the Iceberg client as well as within Spark. Below is an example Spark code snippet that retrieves a previous table version using epoch seconds (2022-01-01 00:00:00).
spark.read
.format("iceberg")
.option("as-of-timestamp", "1640995200000")
.load("db.table")
Rollback
Tables are easily reverted to previous states by simply making a previous snapshot the current snapshot. This is accomplished either directly through the Iceberg client or through engine specific commands. For example, Trino makes the rollback_to_snapshot procedure available and Spark has rollback_to_snapshot as well as rollback_to_timestamp.
Figure 5: Rollback mechanism
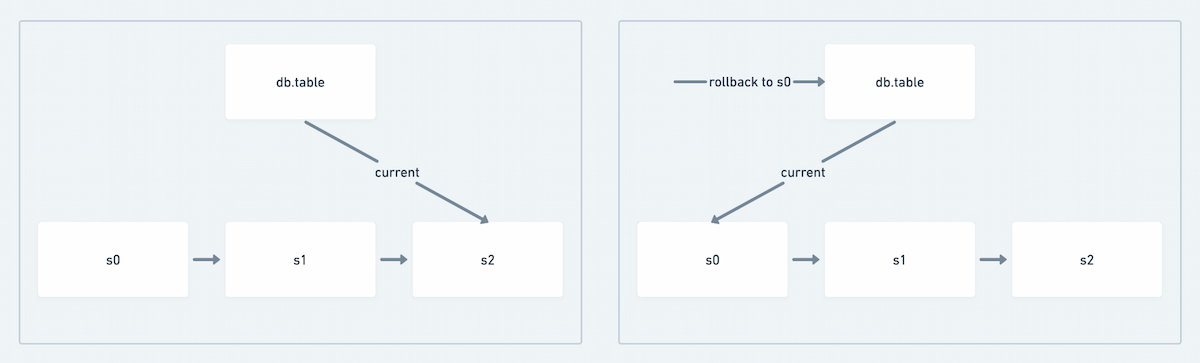
Table Maintenance
The self-contained nature of Iceberg’s metadata allows for simple interfaces for common table maintenance operations. Importantly, table owners do not need to have a deep understanding of the details of physical layout to effectively manage table data.
Expression-Based Deletion
Starting with Spark 3, DELETE FROM syntax can leverage the same expression transformation used in SELECT queries for applying data removal. As an example, given the following DDL:
CREATE TABLE db.table(
event_ts timestamp,
event_id bigint,
customer_id bigint
event_category string,
country_iso_code string
) USING iceberg
PARTITIONED BY (day(event_ts))
Issuing the below statement will be a metadata-only operation and will remove all partitions that contain records where event_ts are between '2021-01-01 00:00:00' and '2022-01-01 00:00:00':
DELETE FROM db.table where event_ts >= timestamp '2021-01-01 00:00:00' and <= date '2022-01-01 00:00:00'
For V2 tables, expressions that do not match entire partitions can be used to perform row-level deletion operations. This will drop all partitions that match fully, and otherwise produce a delete file for the partially deleted partitions.
Spark Actions
Commonly performed operations are provided by Iceberg as Spark procedure calls. These procedures demonstrate canonical implementations for removing files that no longer are in scope for a table’s current or past state. Additionally, the write patterns for a table may not be congruent with the read access patterns. For these cases, procedures are available for optimizing both metadata and data files to reconcile the incongruence between producers and consumers.
Expire Snapshots
There are trade-offs involved in maintaining older snapshots. As more and more snapshots are added, the amount of storage used by a table grows both from a table data perspective and from a metadata perspective. It is recommended to regularly expire snapshots that will no longer be needed. This is enacted by issuing the ExpireSnapshots action, which will remove the specified snapshot from the SnapshotLog.
Remove Orphaned Files
There is no longer a direct mapping between the files under a table’s path and the current table state. Due to various reasons, job failures — and in some cases, normal snapshot expiration — may result in files that are no longer referenced by any snapshots in the table’s SnapshotLog. These files are referred to as orphaned files, and Iceberg provides a DeleteOrphanFiles Spark action for performing this clean-up operation.
Rewrite Data Files
Tables that have many small files will have unnecessarily large table metadata. The RewriteDataFiles action provides a method for combining small files into larger files in parallel, thus improving scan planning and open file cost.
Rewrite Manifests
The layout of manifest metadata affects performance. To get the best performance, the manifests for a table must align with the query patterns. The RewriteManifests action allows the metadata to be reoriented so that there is alignment with processes reading data from the table. Additionally, small manifests can be combined into larger manifests.
Trino Alter Table Operations
Trino also offers several of the above functionality through the Alter table statement syntax. The following capabilities and their Spark analogue are outlined below:
|
Spark and Trino Table Maintenance |
|
Operation Description |
Spark |
Trino |
|
Snapshot Removal |
ExpireSnapshots |
Alter Table … execute expire_snapshots |
|
Data File Compaction |
RewriteDataFiles |
Alter Table … execute optimize |
|
File Garbage Collection |
DeleteOrphanedFiles |
Alter Table … execute remove_orphan_files |
More detail on these operations can be found in the Trino Iceberg connector documentation.