Hazelcast In-Memory Data Grid (IMDG) is a group of processes that join together to share responsibility for data storage and processing. Data is stored in memory, so access times can be hundreds or thousands of times faster than disk. Data is spread across the processes, so capacity can be varied by simply adding or removing processes without any outage.
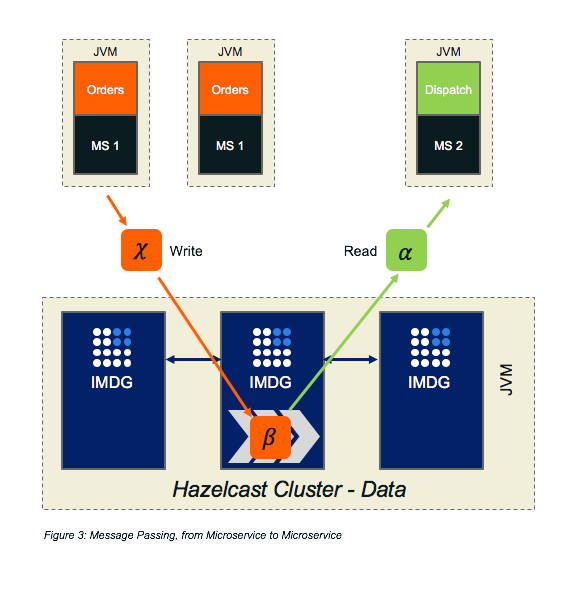
For microservices, what IMDG brings is communal storage that is fast, scalable, and resilient.
Hazelcast IMDG is simple — a single JAR with no external dependencies. One of the core values of Hazelcast from its inception was simplicity and ease of use, and that still exists today. When you move an application or system into a distributed environment, having a simple and configurable backbone makes the task a lot easier.
You can leverage Hazelcast because of its highly scalable in-memory data grid (for example, IMap and JCache). Hazelcast also supports other standard JDK collections such as lists, sets, queues, and some other constructs such as topics and ring buffers that can be easily leveraged for inter-process messaging. All of these attributes can offer functionality that is highly desirable within a microservices platform.
I live by the rule that if I can’t get any software running within 15 minutes, I move on. Hazelcast meets this standard. Simplistically, in a grid of 10 processes, each holds one-tenth of the data copies and backups. Should more be needed, two more processes could be added and the data would be automatically rebalanced, with the net effect that each now holds one-twelfth of the total data and capacity has increased by 20%. A configurable level of data mirroring within the grid protects from data loss should a process fail.
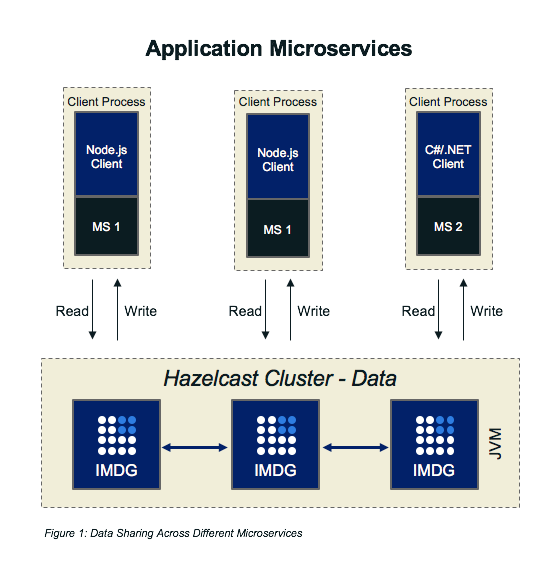
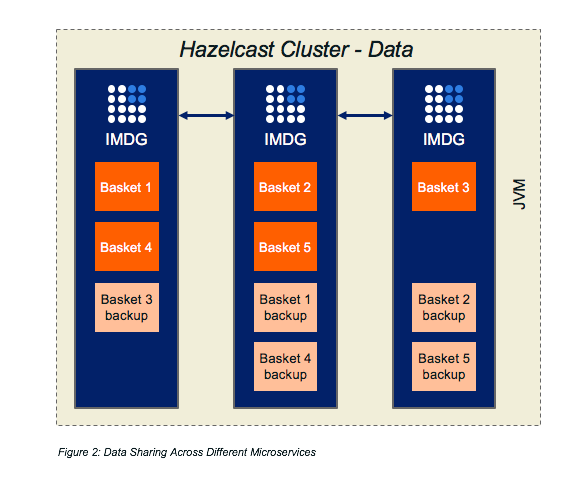
Although the grid can do processing, for a microservice architecture, it is more of a shared store. The clients that share it, the microservices, can be in a variety of languages.
Let’s look at how we can incorporate Hazelcast IMDG and Spring Boot into a microservices platform.
As a Java program, the following is enough to create a standalone “bootable” JAR file that can be run from the command line. It won’t do anything, but it will run successfully.
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
Hazelcast is usually configured from XML. To turn that “bootable” JAR into a Hazelcast server, all that needs done is to add a file hazelcast.xml to the classpath with this content:
<?xml version="1.0" encoding="UTF-8"?>
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config hazelcast-config-3.8.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
</hazelcast>
Spring Boot relies heavily on auto-configuration. If it finds a Hazelcast IMDG configuration file such as the above and has the Hazelcast classes as dependencies, it does the necessary boilerplate steps to create a Hazelcast IMDG server instance configured from that file.
So these two components are enough to create a standalone JAR file containing a full Hazelcast IMDG server that can participate in an IMDG grid.
This is a production-quality Hazelcast IMDG server run as a Spring @Bean in an executable JAR file that can be pushed out to run on any host with a JRE. It’s one file; easy to deploy.
It is the minimum set-up, but extension is equally easy.
Now that it’s clear how easy it is to set up a Hazelcast IMDG with Spring Boot, it is time to return to microservices in general to see how this is going to be useful.
There are six main problems that Spring Boot and Hazelcast IMDG help solve.
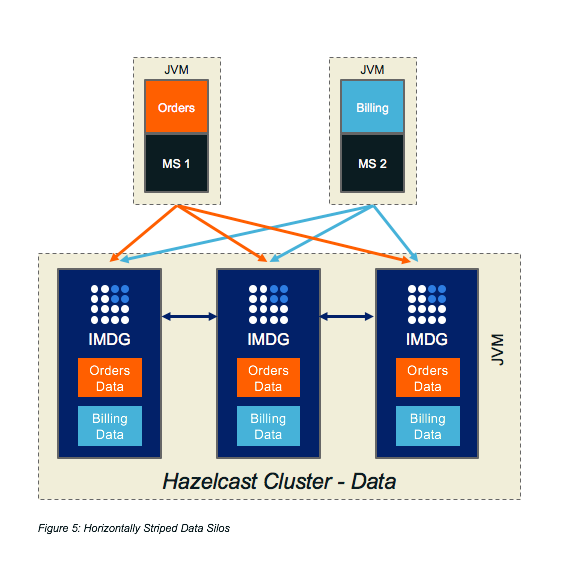
- Sharing
- Asynchronicity
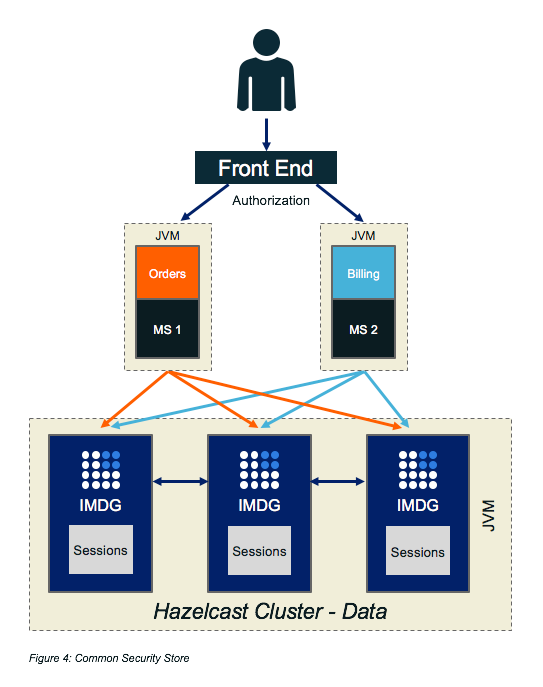
- Security
- Simplicity
- Evolution
- Health
Let’s look at each in turn, using the common scenario of online shopping, where the customer adds items to a virtual basket over time and hopefully decides to buy these.