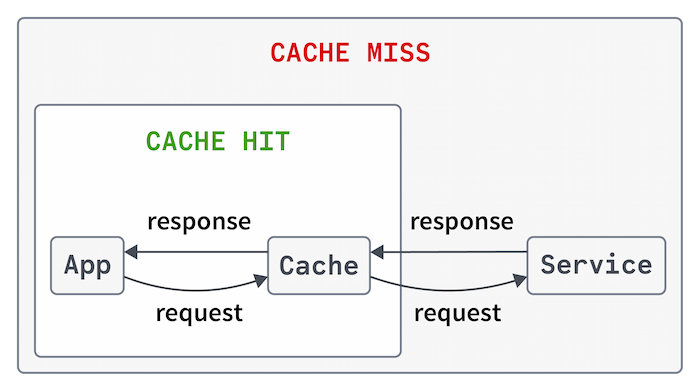
JCache was introduced in Java Specification Request (JSR) 107 and provides a set of abstractions over caching. There are two standout properties of JCache:
- JCache is a specification. JSRs are specifications designed and submitted by an expert group and eventually approved by the Java Community Process Executive Committee. Because JCache is a specification, it insulates itself from implementations whose APIs change frequently.
- JCache is provider independent. A side effect of JCache being a specification is that providers of caching solutions can integrate with JCache by implementing its exposed Service Provider Interface (SPI). This provides system designers with flexibility and avoids vendor lock-in.
The following is a simple example of JCache to give an understanding of what its use looks like. The coordinate for the javax.cache dependency can be found here.
import java.util.Map;
import javax.cache.Cache;
import javax.cache.CacheManager;
import javax.cache.Caching;
import javax.cache.configuration.MutableConfiguration;
import javax.cache.spi.CachingProvider;
public class App {
public static void main(String[] args) {
CachingProvider cachingProvider = Caching.getCachingProvider(); // (1)
CacheManager cacheManager = cachingProvider.getCacheManager(); // (2)
MutableConfiguration<String, String> cacheConfig = new MutableConfiguration<String, String>(); // (3)
Cache<String, String> cache = cacheManager.createCache("dzone-cache", cacheConfig); // (4)
cache.put("England", "London"); // (5)
cache.putAll(Map.of("France", "Paris", "Ireland", "Dublin")); // (6)
assert cache.get("England").equals("London"); // (7)
assert cache.get("Italy") == null; // (8)
}
}
A brief explanation of the above example:
(1) Obtains a handle to the underlying caching provider
(2) Manages a cache's lifecycle (e.g., creating and destroying caches)
(3) Permits enabling/disabling specific functionality of the cache (e.g., statistics, entry listeners)
(4) Creates the cache backed by the cache provider
(5) Puts a single key-value entry in the cache
(6) Puts key-value entries into the cache
(7) Asserts the presence of a cache entry
(8) Asserts that an entry is not present in the cache
The remainder of this section discusses, in more detail, the abstractions introduced in the above example in addition to other methods of the relevant classes that you will often encounter.
The javax.cache.spi.CachingProvider forms the JCache SPI that caching providers can integrate. The most common feature you will use is attaining a reference to a CacheManager. We will discuss Caching later. getCacheManager is the simplest of the getCacheManager variants. This will attain a CacheManager according to the provider defaults.Caches can be created and destroyed using javax.cache.CacheManager:
createCache creates a cache of a given name and configuration.destroyCache destroys the cache with the given name.
javax.cache.Cache is an abstraction over the provider's cache and exposes a handful of operations to query and mutate the cache's items:
put and putAll put entries into the cache. Note that these methods do not return any previously associated values with the keys being put.containsKey tests if a key exists in the cache.get and getAll return the values associated with the keys specified.remove and removeAll remove items from the cache.
JCache Packages
In this section, we give a quick overview of some important interfaces within the broader package structure of javax.cache and provide examples of functionality commonly used. We can refer to the documentation to explore an exhaustive list of their content.
Figure 2: Constituent packages of javax.cache
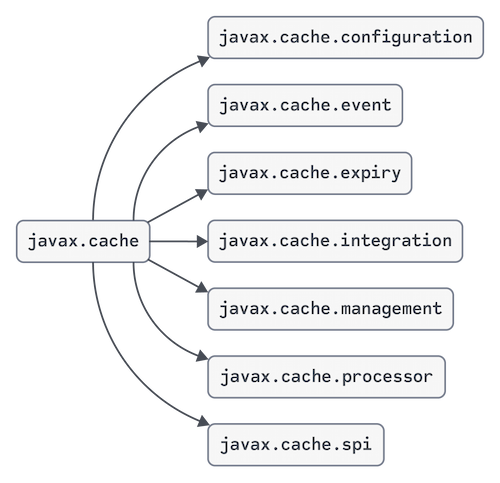
javax.cache
Facilities for general management (CacheManager) and interaction with caches (Cache) reside within the javax.cache package. Beyond initial configuration, unless you want to add additional capabilities to your cache, you can do a lot using just the types within this package. For example, the sample usage from the introduction of the "JCache Essentials" section largely uses the interfaces defined in javax.cache.
javax.cache.configuration
During the creation of a cache, you may want to add capabilities such as enabling statistics or read-through caching. This package provides a Configuration interface and an implementation MutableConfiguration that can be used for such purposes.
// ...
MutableConfiguration<String, String> cacheConfig = new MutableConfiguration<String, String>();
cacheConfig.setManagementEnabled(true).setStatisticsEnabled(true);
Cache<String, String> cache = cacheManager.createCache("dzone-cache", cacheConfig);
javax.cache.expiry
There are times when you want items residing within your cache to expire. For example, we might have a cache of home insurance quotes that are valid for 24 hours. In this case, we can use an expiry policy as follows:
// ...
MutableConfiguration<String, Double> cacheConfig = new MutableConfiguration<String, Double>();
cacheConfig.setExpiryPolicyFactory(CreatedExpiryPolicy.factoryOf(Duration.ONE_DAY));
Cache<String, Double> cache = cacheManager.createCache("insurance-home-qoutes", cacheConfig);
cache.put(quote.getId(), qoute.getValue());
The javax.cache.expiry package provides additional expiration policies that can be useful for other scenarios. For example, AccessedExpiryPolicy permits the ability to attach an expiration based on a cache entry's last access time.
javax.cache.event
A powerful feature of JCache is the ability to subscribe to cache events. For example, we may want to run some domain logic upon a cache entry being created or deleted. The javax.cache.event package provides the abstractions to do this, specifically the ability to subscribe to cache creates, updates, expiries, and removals. The following basic example runs some domain logic after a cache entry is created:
// ...
CacheEntryCreatedListener<String, String> createdListener = new CacheEntryCreatedListener<String, String>() {
@Override
public void onCreated(Iterable<CacheEntryEvent<? extends String, ? extends String>> events)
throws CacheEntryListenerException {
for (var c : events) {
performDomainLogic(c);
}
}
};
MutableConfiguration<String, String> cacheConfig = new MutableConfiguration<String, String>();
MutableCacheEntryListenerConfiguration<String, String> listenerConfig = new MutableCacheEntryListenerConfiguration<>(() -> createdListener, null, false, true); // refer to documentation
cacheConfig.addCacheEntryListenerConfiguration(listenerConfig);
Cache<String, String> cache = cacheManager.createCache("events", cacheConfig);
cache.put("key", "value"); // calls creation listener
javax.cache.processor
A powerful component of JCache is the ability to use an EntryProcessor to move compute to the data and then invoke that compute programmatically. This is particularly powerful when using a provider that hosts its cache within a distributed system (e.g., Hazelcast) as it offers a simple entry point into distributed computing with little investment. The following is a simple example of EntryProcessor that appends a UUID to a cache entry:
// ...
class AppendUuidEntryProcessor implements EntryProcessor<String, String, String> {
@Override
public String process(MutableEntry<String, String> entry, Object... arguments) throws EntryProcessorException {
if (entry.exists()) {
String newValue = entry.getValue() + "-" + UUID.randomUUID();
entry.setValue(newValue);
return newValue;
}
return null;
}
}
// ...
cache.invoke(key, new AppendUuidEntryProcessor())
javax.cache.management
The management hooks provided by JCache are very powerful and easily enabled. For example, the below small code snippet exposes Managed Beans defined by the Java Management Extensions (JMX) specification. This enables JMX clients such as jconsole and JDK Mission Control to have visibility into cache configurations and statistics (e.g., hit and miss percentages, average get and put times).
// ...
MutableConfiguration<String, String> cacheConfig = new MutableConfiguration<String, String>();
cacheConfig.setManagementEnabled(true).setStatisticsEnabled(true);
Cache<String, String> cache = cacheManager.createCache("management", cacheConfig);
// ...
javax.cache.spi
The example provided in the"JCache Essentials" section omitted how we register the cache provider, the service that hosts the caches our application interacts with using the JCache API. This is where the SPI component of JCache comes into play. There are two components for making this work:
- Adding our caching provider to the classpath
- Telling JCache to use that provider
Step one is straightforward: Simply add a dependency on any JSR 107-compliant provider.
Step two has a few general approaches you can take:
- We can tell JCache via invoking one of the
Caching#getCachingProvider(...) variants (among others).
- We can ship a
META-INF/services/javax.cache.spi.CachingProvider and have it specify the provider implementation. The provider specified is the fully qualified name of your provider's cache provider implementation.
- We can use
Caching#getCachingProvider(); however, it is best to explicitly qualify the provider to use as you may have multiple providers on your classpath, which will throw a javax.cache.CacheException.
For example, the following specifies Hazelcast as the provider using CachingProvider Caching.getCachingProvider(String):
CachingProvider cachingProvider = Caching.getCachingProvider("com.hazelcast.cache.HazelcastCachingProvider");
CacheManager cacheManager = cachingProvider.getCacheManager();
MutableConfiguration<String, String> cacheConfig = new MutableConfiguration<String, String>();
Cache<String, String> cache = cacheManager.createCache("spi-example", cacheConfig);
cache.put("k", "v");
javax.cache.annotation
JCache defines a number of annotations for integration into context and dependency injection environments. The Spring Framework has native support for JCache annotations. We can refer to the JCache documentation for more information.
javax.cache.integration
The javax.cache.integration package provides CacheLoader (requires read-through) and CacheWriter (requires write-through). The CacheLoader is used when reading data into the cache — for example, Cache#loadAll(...). The CacheWriter can be used as an integration point to propagating cache mutations (e.g., writes, deletes) to an external storage service.
Cache Deployments
JCache has no notion of cache deployment strategies; it is simply an API over caching providers. However, different providers facilitate different types of cache deployments. Consider what caching deployment makes sense for your application and work backward from there to determine an appropriate caching provider.
Figure 2: Caching deployment examples
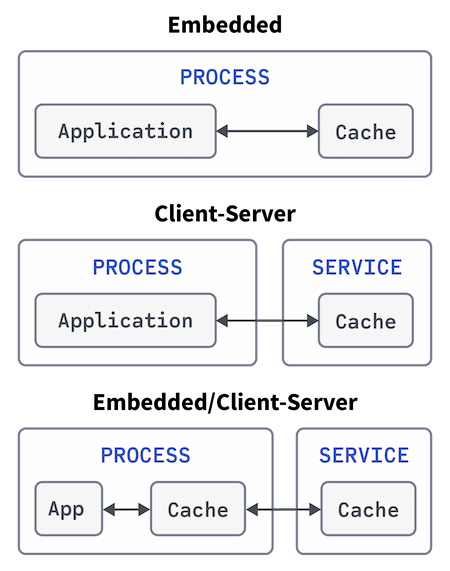
Note that some caching providers may support all three of these cache deployments, while other providers may not.
The rest of this section discusses the common caching deployments shown in Figure 2:
- Embedded – The cache is co-located in the same process as the application.
- Client-server – The cache is hosted in a separate service, and the client communicates with that service to determine cache residency.
- Embedded/client-server – This is a hybrid mode where the entire cache is hosted on a distinct service, but the client has a smaller cache co-located in the same process.
It is important to note that the above cache deployments are not mutually exclusive; they can be composed in a multitude of ways to meet application demands.
The simplest deployment of a cache is for the cache to reside in the same process as the application, which has the benefit of providing low-latency cache access. Embedded caches are not shared across applications and can have a significant cost to host (the resources they require) and rebuild upon application restart or failure.
A client-server cache deployment has the cache hosted by a service distinct to that of the client. A cache service permits catering for fault tolerance through replication across the service, greater capacity, more scalability options, and the ability to share the cache across applications. The main drawback of the client-server model is the cost of the network communication during a client cache query.
Combined embedded/client-server deployments are where we have an embedded cache, which entails a subset of cache entries from the service cache, populated as a side effect of application cache requests. Here, the client can have low-latency cache hits on frequently accessed data (or data that exhibits a particular access pattern) and forgo the network communication, entailed by communicating with the cache service. Some providers will take care of updating embedded caches with the service hosted cache should they be out of date.