Why a Multi-Cloud Data Layer?
For decades, the separation of business logic from the persistent data it manipulates has been well established in software application architectures. This is because the same data can be used in many different ways to serve many different use cases, so it cannot be embedded in any one application. With the emergence of microservices, the need has come for this data to become a service.
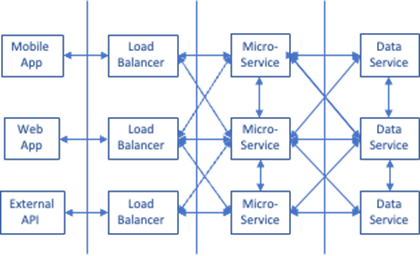
But this is not monolithic data. Many microservices using a single database results in very tight coupling. This makes it impossible to deploy new or evolving services individually if they need to make database changes that will affect other services. Breaking complex service interdependencies requires a data layer of multiple databases, each serving a single microservice or possibly a few, tightly related microservices.
Delivering Data Services for Any Use Case
Cloud computing offers microservices the perfect operating environment: resilient, scalable, and distributable. But the database lagged the embrace of the virtual world of the cloud. Traditional RDBMS, the workhorse of data services since before the turn of the millennium, is monolithic. You scale a traditional RDBMS by running it on more powerful hardware. But in the cloud, this has limitations. And resilience comes only from database replication and complex disaster recovery processes.
The response to this was a proliferation of NoSQL databases and other data management tools. But monolithic RDBMS hung on because it can deliver ACID transactional consistency, which is vital for systems of record and systems of engagement. And lately, SQL databases are fighting back with cloud-native transactional capability.
But in reality, it is not a fight, a war of competing database models. It is a co-existence. ACID, SQL databases are still the best at transactional consistency. But NoSQL, graph, document, analytic, and streaming databases and technologies excel elsewhere in the spectrum of data services’ needs. And mature technologies are available to address all these workloads.
By implementing more applications in the cloud as microservices, the data services needed to support these applications will be delivered by different technologies and databases — each optimized by the needs of the microservices it is supporting.
The result is not an attempt to shoehorn all workloads into a single winner-takes-all database. The optimal result is a multi-cloud data layer with the capability to deliver the appropriate data services for any use case.
Multi-Cloud Data Layer Core Capabilities
A multi-cloud data layer delivers three core capabilities for both existing applications to help bridge digital transformation initiatives as well as new cloud-native applications and microservices. These core capabilities include:
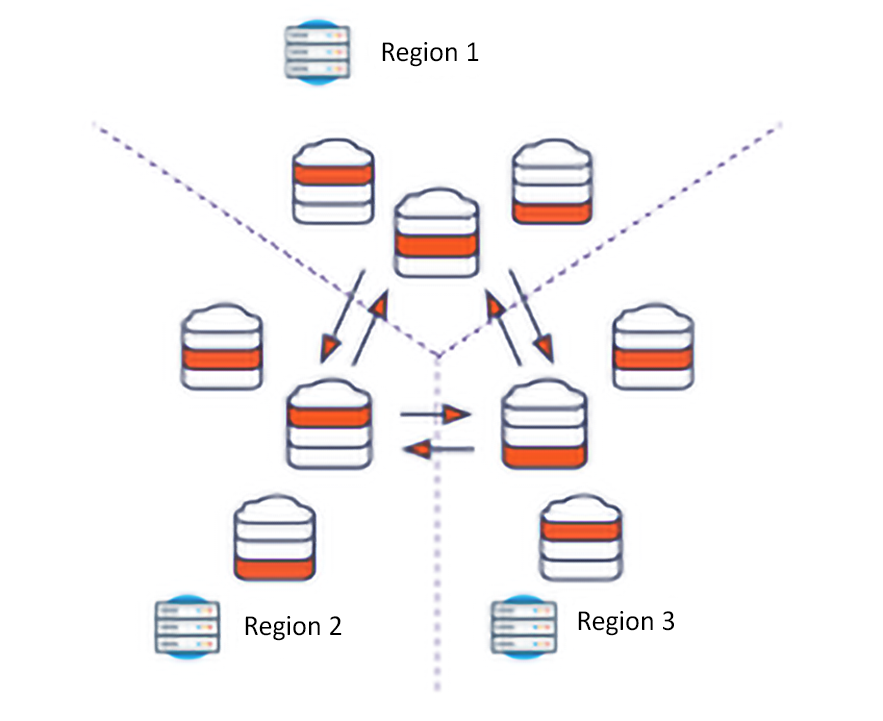
- Freedom from tradeoffs: With a multi-cloud data layer, developers can achieve low latency, ACID transactions, familiar interfaces, relational capabilities, horizontal scale, high performance, geographic distribution, and ease of deployment, all in one database system.
- Simplified operations: A multi-cloud data layer should be easy to deploy and scale to help minimize disruption going from a traditional RDBMS to a cloud-native database for cloud-native applications. It also provides the flexibility to allow organizations to start running in minutes through a fully managed offering, or be able to deploy anywhere, including containers across public, private, and hybrid cloud environments. For all deployments, organizations should be able to start small and scale horizontally without impacting performance, uptime, or data integrity (i.e., scale-out vs. scale-up).
- Built-in security and resiliency: Uncompromising security and availability are expected, with these core features designed into a multi-cloud data layer from the start to make it easy and seamless to enable.