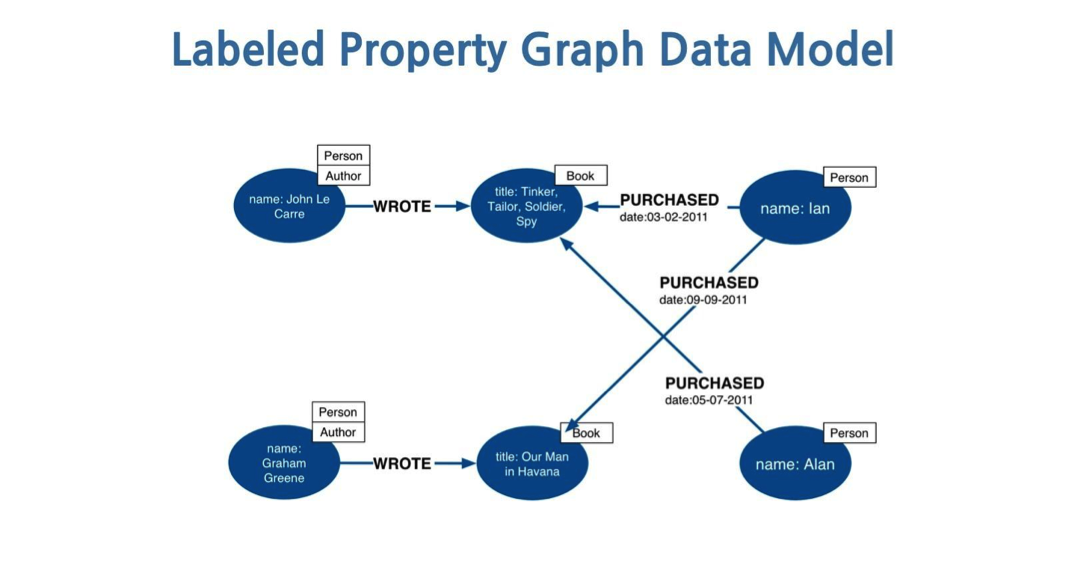
Note: {value} denotes either literals, for ad hoc Cypher queries; or parameters, for applications. Neo4j properties can be strings, numbers, or booleans, or arrays thereof.
Read Query Structure
[MATCH WHERE]
[OPTIONAL MATCH WHERE]
[WITH [ORDER BY] [SKIP] [LIMIT]]
RETURN [ORDER BY] [SKIP] [LIMIT]
MATCH
| Command |
Description |
MATCH
(n:Person)-[:KNOWS]->(m:Person)
WHERE n.name=”Alice”
|
Node patterns can contain labels and are connected by relationships. |
| MATCH (n)-->(m) |
Any pattern can be used in MATCH. |
MATCH
(n:Person {name:"Alice"})-->(m) |
Patterns with node properties. |
| MATCH p = (n)-->(m) |
Assign a path to p. |
| OPTIONAL MATCH (n)-[r]->(m) |
Optional pattern, NULLs will be used for missing parts. |
WHERE
| Command |
Description |
| WHERE node.property = {value} |
Use a predicate to filter.
Note that WHERE is always part of a MATCH, OPTIONAL MATCH, WITH or START clause.
Putting it after a different clause in a query will alter what it does. |
RETURN
| Command |
Description |
| RETURN * |
Return the value of all named identifiers. |
| RETURN n AS columnName |
Use alias for result column. |
| RETURN DISTINCT n |
Return the value of all identifiers. |
| RETURN DISTINCT n |
Return unique rows. |
| ORDER BY n.property |
Sort the result. |
| ORDER BY n.property DESC |
Sort the result in descending order. |
| SKIP {skip_number} |
Skip a number of results. |
| LIMIT {limit_number} |
Limit the number of results. |
| SKIP {skip_number} LIMIT {limit_number} |
Skip results at the top and limit the number of results. |
| RETURN count(*) |
The number of matching rows.
See Aggregation for more. |
WITH
| Command |
Description |
MATCH (user)-[:FRIEND]-(friend)
WHERE user.name = {name}
WITH user, count(friend) AS friends
WHERE friends > 10
RETURN user
|
WITH chains query parts. It allows you to specify which projection of your data is available after WITH.
You can also use ORDER BY, SKIP, LIMIT and aggregation with WITH.
You might have to alias expressions to give them a name. |
UNION
| Command |
Description |
MATCH (a)-[:KNOWS]->(b)
RETURN b.name
UNION
MATCH (a)-[:LOVES]->(b)
RETURN b.name
|
Returns the distinct union of all query results.
Result column types and names have to match. |
MATCH (a)-[:KNOWS]->(b)
RETURN b.name
UNION ALL
MATCH (a)-[:LOVES]->(b)
RETURN b.name
|
Returns the union of all query results, including duplicated rows. |
Write-Only Query Structure
(CREATE [UNIQUE] | MERGE)*
[SET|DELETE|REMOVE|FOREACH]*
[RETURN [ORDER BY] [SKIP] [LIMIT]]
Read-Write Query Structure
[MATCH WHERE]
[OPTIONAL MATCH WHERE]
[WITH [ORDER BY] [SKIP] [LIMIT]]
(CREATE [UNIQUE] | MERGE)*
[SET|DELETE|REMOVE|FOREACH]*
[RETURN [ORDER BY] [SKIP] [LIMIT]]
CREATE
| Command |
Description |
| CREATE(n:Person {name: {value}}) |
Create a node with the given properties. |
| CREATE (n:Person {map}) |
Create a node with the given properties. |
| CREATE (n:Person {collOfMaps}) |
Create nodes with the given properties. |
| CREATE (n)-[r:KNOWS]->(m) |
Create a relationship with the given type and direction; bind an identifier to it. |
| CREATE (n)-[:LOVES since:{value}}] ->(m) |
Create a relationship with the given type, direction, and properties. |
MERGE
| Command |
Description |
MERGE
(n:Person {name: {value}})
ON CREATE SET
n.created=timestamp()
ON MATCH SET
n.counter=coalesce(n.counter,0)+1,
n.accessed=timestamp() |
Use ON CREATE and ON MATCH for conditional updates. |
MATCH
(a:Person {name: {value1}}),
(b:Person {name: {value2}})
MERGE (a)-[r:LOVES]->(b) |
MERGE finds or creates a relationship between the nodes. |
MATCH
(a:Person {name: {value1}})
MERGE
(a)-[r:KNOWS]->(b:Person {name: {value2}}) |
MERGE matches or creates whole subgraphs attached to the node. |
SET
| Command |
Description |
SET
n.property1 = {value1},
n.property2 = {value2} |
Update or create a property |
SET n = {map}
|
Set all properties.
This will remove any existing properties. |
| SET n += {map} |
Add and update properties, while keeping existing ones. |
| SET n:Person |
Adds a label Person to a node. |
DELETE
| Command |
Description |
| DELETE n, r |
Delete a node and a relationship. |
REMOVE
| Command |
Description |
| REMOVE n:Person |
Remove a label from n. |
| REMOVE n.property |
Remove a property. |
INDEX
| Command |
Description |
| CREATE INDEX ON :Person(name) |
Create an index on the label Person and property name. |
MATCH (n:Person)
WHERE n.name = {value} |
An index can be automatically used for equality comparison. Note that for example lower(n.name) = {value} will not use an index. |
MATCH (n:Person)
WHERE n.name IN [{value}] |
An index can be automatically used for the IN collection checks. |
MATCH (n:Person)
USING INDEX n:Person(name)
WHERE n.name = {value} |
Index usage can be enforced with USING. E.g. when Cypher uses a suboptimal index or when more than one index should be used. |
| DROP INDEX ON :Person(name) |
Drop the index on the label Person and property name. |
CONSTRAINT
| Command |
Description |
CREATE CONSTRAINT
ON (p:Person)
ASSERT p.name IS UNIQUE |
Create a unique constraint on the label Person and property name.
If any other node with the label Person is updated or created with a value for name that already exists, the write operation will fail. This constraint will create an accompanying index. |
DROP CONSTRAINT
ON (p:Person)
ASSERT p.name IS UNIQUE |
Drop the unique constraint and index on the label Person and property name. |
Operators
| Type |
Operator |
| Mathematical |
+, -, *, /, %, ^ |
| Boolean |
AND, OR, XOR, NOT |
| String |
+ |
| Collection |
+, IN, [x], [x .. y] |
| Regular Expression |
=~ |
NULL
- NULL is used to represent missing/undefined values.
- NULL is not equal to NULL. Not knowing two values does not imply that they are the same value. So the expression NULL = NULL yields NULL and not TRUE. To check if an expression is NULL, use IS NULL.
- Arithmetic expressions, comparisons and function calls (except coalesce) will return NULL if any argument is NULL.
- Missing elements like a property that doesn’t exist or accessing elements that don’t exist in a collection yields NULL.
- In OPTIONAL MATCH clauses, NULLs will be used for missing parts of the pattern.
Patterns
| Command |
Description |
| (n)-->(m) |
A relationship from n to m exists. |
| (n:Person) |
Matches nodes with the label Person. |
| (n:Person:Swedish) |
Matches nodes that have both Person and Swedish labels. |
| (n:Person {name: {value}}) |
Matches nodes with the declared properties. |
| (n:Person)-->(m) |
Node n, labeled Person, has a relationship to node m. |
| (n)--(m) |
A relationship in any direction between n and m. |
| (m)<-[:KNOWS]-(n) |
A relationship from n to m of type KNOWS exists. |
| (n)-[:KNOWS|:LOVES]->(m) |
A relationship from n to m of type KNOWS or LOVES exists. |
| (n)-[r]->(m) |
Bind an identifier to the relationship. |
| (n)-[*1..5]->(m) |
Variable length paths can span 1 to 5 hops. |
| (n)-[*]->(m) |
Variable length path of any depth. See performance tips. |
| (n)-[:KNOWS]->(m:Label {property: {value}}) |
Match or set properties in MATCH, CREATE, CREATE UNIQUE or MERGE clauses. |
| shortestPath((n1:Person)-[*..6]-(n2:Person)) |
Find a single shortest path for previously matched nodes. |
| allShortestPaths((n1)-[*..6]-(n2)) |
Find all shortest paths. |
Labels
| Command |
Description |
| CREATE (n:Person {name:{value}}) |
Create a node with label and property. |
| MERGE (n:Person {name:{value}}) |
Matches or creates unique node(s) with label and unique property. |
| SET n:Spouse:Parent:Employee |
Add label(s) to a node. |
| MATCH (n:Person) |
Matches nodes labeled as Person. |
MATCH (n:Person)
WHERE n.name = {value} |
Matches nodes labeled Person with the given name. |
| WHERE (n:Person) |
Checks existence of label on node. |
| labels(n) |
Labels of the node. |
| REMOVE n:Person |
Remove label from node. |
Collections
| Command |
Description |
| [‘a’,’b’,’c’] AS coll |
Literal collections are declared in square brackets. |
| length({coll}) AS len, {coll}[0] AS value |
Collections can be passed in as parameters. |
| range({from},{to},{step}) AS coll |
Range creates a collection of numbers (step is optional). |
| MATCH (a)-[r:KNOWS*..5]->() RETURN r AS rels |
Relationship identifiers of a variable length path is a collection of relationships. |
RETURN
node.coll[0] AS value, length(node.coll) AS len |
Properties can be arrays/collections of strings, numbers or booleans. |
coll[{idx}] AS value,
coll[{start}..{end}] AS slice |
Collection elements can be accessed with idx subscripts in square brackets.
Invalid indexes return NULL.
Slices can be retrieved with intervals from start to end, each of which can be omitted or negative.
Out of range elements are ignored. |
UNWIND {names} AS name
MATCH (n:Person {name:name})
RETURN avg(n.age) |
With UNWIND, you can transform any collection back into individual rows.
The example matches all names from a list of names. |
Maps
| Command |
Description |
{name:"Alice", age:38,
address:{city:"London",
residential:true}} |
Literal maps are declared in curly braces much like property maps. Nested maps and collections are supported. |
MERGE
(p:Person{name:{map}.name})
ON CREATE SET p={map} |
Maps can be passed in as parameters and used as map or by accessing keys. |
| range({start},{end},{step}) AS coll |
Range creates a collection of numbers (step is optional). |
MATCH (n:Person)-[r]->(m)
RETURN n,r,m |
Nodes and relationships are returned as maps of their data. |
| map.name, map.age, map.children[0] |
Map entries can be accessed by their keys.
Invalid keys result in an error. |
Relationship Functions
| Command |
Description |
| type(rel) |
String representation of the relationship type. |
| startNode(rel) |
Start node of the relationship. |
| endNode(rel) |
End node of the relationship. |
| id(rel) |
The internal id of the relationship. |
Predicates
| Command |
Description |
| n.property <> {value} |
Comparison operators. |
| has(n.property) |
Functions. |
n.number >= 1
AND n.number <= 10 |
Boolean operators combine predicates. |
| n:Person |
Check for node labels. |
| identifier IS NULL |
Check if something is NULL. |
| NOT has(n.property) OR n.property = {value} |
Either property does not exist or predicate is TRUE. |
| n.property = {value} |
Non-existing property returns NULL, which is not equal to anything. |
| n.property =~ "Tob.*" |
Regular expression. |
| (n)-[:KNOWS]->(m) |
Make sure the pattern has at least one match. |
| NOT (n)-[:KNOWS]->(m) |
Exclude nodes with certain pattern matches from the result. |
| n.property IN [{value1}, {value2}] |
Check if an element exists in a collection. |
Collection Predicates
| Command |
Description |
| all(x IN coll WHERE has(x.property)) |
Returns TRUE if the predicate is TRUE for all elements of the collection. |
| any(x IN coll WHERE has(x.property)) |
Returns true if the predicate is TRUE for at least one element of the collection. |
| none(x IN coll WHERE has(x.property)) |
Returns TRUE if the predicate is FALSE for all elements of the collection. |
| single(x IN coll WHERE has(x.property)) |
Returns TRUE if the predicate is TRUE for exactly one element in the collection. |
Functions
| Command |
Description |
| coalesce(n.property,..., {defaultValue}) |
The first non-NULL expression. |
| timestamp() |
Milliseconds since midnight, January 1, 1970 UTC. |
| id(node_or_relationship) |
The internal id of the relationship or node. |
| toInt({expr}) |
Converts the given input in an integer if possible; otherwise it returns NULL. |
| toFloat({expr}) |
Converts the given input in a floating point number if possible; otherwise it returns NULL. |
Path Functions
| Command |
Description |
| length(path) |
The length of the path. |
| nodes(path) |
The nodes in the path as a collection. |
| relationships(path), rels(path) |
The relationships in the path as a collection. |
MATCH path=(n)-->(m)
RETURN extract(x IN nodes(path) | x.prop) |
Assign a path and process its nodes. |
MATCH path=(n1)-[*]->(n2)
FOREACH
(n IN rels(path) | SET n.marked = TRUE) |
Execute an update operation for each relationship of a path. |
Collection Functions
| Command |
Description |
| length({coll}) |
Length of the collection. |
| head({coll}), last({coll}), tail({coll}) |
Head returns the first, last the last element, and tail the remainder of the collection. All return NULL for an empty collection. |
| [x IN coll WHERE has(x.prop) | x.prop] |
Combination of filter and extract in a concise notation. |
| extract(x IN coll | x.prop) |
A collection of the value of the expression for each element in the original collection. |
| filter(x IN coll WHERE x.prop <> {value}) |
A filtered collection of the elements where the predicate is TRUE. |
| reduce(s = 0, x IN coll | s + x.prop) |
Evaluate expression for each element in the collection, accumulate the results. |
FOREACH (value IN coll |
CREATE (:Person{name:value})) |
Execute a mutating operation for each element in a collection. |
Mathematical Functions
| Command |
Description |
| abs({expr}) |
The absolute value. |
| rand() |
A random value. Returns a new value for each call. Also useful for selecting subset or random ordering. |
round({expr}),
ceil({expr}), floor({expr}) |
Round to the nearest integer. Ceil and floor find the closest integer rounded up or down. |
| sqrt({expr}) |
The square root. |
| sign({expr}) |
0 if zero, -1 if negative, 1 if positive. |
| sin({expr}) |
Trigonometric functions, also cos, tan, cot, asin, acos, atan, atan2, haversin. |
| degrees({expr}), radians({expr}), pi() |
Converts radians into degrees, use radians for the reverse. pi for π. |
| log10({expr}), log({expr}), exp({expr}), e() |
Logarithm base 10, natural logarithm, e to the power of the parameter. |
String Functions
| Command |
Description |
| toString({expression}) |
String representation of the expression. |
| replace({string}, {search}, {replacement}) |
Replace all occurrences of search with replacement.
All arguments are be expressions. |
| substring({string}, {begin}, {len}) |
Get part of a string.
The len argument is optional. |
left({string}, {len}),
right({string}, {len}) |
The first part of a string.
The last part of the string. |
trim({string})
ltrim({string})
rtrim({string}) |
Trim all whitespace, or on left or right side. |
| upper({string}), lower({string}) |
UPPERCASE and lowercase. |
| split({string}, {delim}) |
Split a string into a collection of strings. |
Aggregation
| Command |
Description |
| count(*) |
The number of matching rows. |
| count(identifier) |
The number of non-NULL values. |
| count(DISTINCT identifier) |
All aggregation functions also take the DISTINCT modifier, which removes duplicates from the values. |
| collect(n.property) |
Value collection, ignores NULL. |
| sum(n.property) |
Sum numerical values. Similar functions are avg, min, max. |
| percentileDisc(n.property, {percentile}) |
Discrete percentile. Continuous percentile is percentileCont.
The percentile argument is from 0.0 to 1.0. |
| stdev(n.property) |
Standard deviation for a sample of a population. For an entire population use stdevp. |
CASE
| Command |
Description |
CASE n.eyes
WHEN 'blue' THEN 1
WHEN 'brown' THEN 2
ELSE 3
END |
Return THEN value from the matching WHEN value.
The ELSE value is optional, and substituted for NULL if missing. |
CASE
WHEN n.eyes = 'blue' THEN 1
WHEN n.age < 40 THEN 2
ELSE 3
END |
Return THEN value from the first WHEN predicate evaluating to TRUE.
Predicates are evaluated in order. |
START
| Command |
Description |
START n =
node:indexName(key={value})
n=node:nodeIndexName(key={value})
n=node:nodeIndexName(key={value}) |
Query the index with an exact query. Use node_auto_index for the old automatic index. |
START n =
node:indexName({query}) |
Query the index by passing the query string directly, can be used with lucene or spatial syntax. E.g.: "name:Jo*" or "withinDistance:[60,15,100]" |
Upgrading
In Neo4j 2.0, several Cypher features from version 1.9 have been deprecated or removed:
- START is optional.
- MERGE takes CREATE UNIQUE’s role for the unique creation of patterns. Note that they are not the same.
- Optional relationships are handled by OPTIONAL MATCH, not question marks.
- Non-existing properties return NULL: n.prop? and n.prop! have been removed.
- The separator for collection functions changed from ":" to "|".
- Paths are no longer collections, use nodes(path) or rels(path).
- Parentheses around nodes in patterns are no longer optional.
- CREATE a={property:’value’} has been removed
- Use REMOVE to remove properties.
- Parameters for index-keys and nodes in patterns are no longer allowed.
- To use the older syntax, prepend your Cypher statement with CYPHER 1.9.
Performance Tips
- Use parameters instead of literals when possible. This allows Cypher to reuse your queries instead of having to parse and build new execution plans.
- Always set an upper limit for your variable length patterns. It’s easy to have a query touch all nodes in a graph by mistake.
- Return only the data you need. Avoid returning whole nodes and relationships — instead, return only the properties you need.
Use Case: Recommendations
Recommendations in Neo4j are both powerful and easy to implement. You can recommend anything, including friends, music, products, places, books, jobs, travel-connections ... even Refcardz.
As you’re reading one, let’s take a Refcard collection as an example for a tiny recommendation system. You can find more recommendation examples online.
In our example domain we have :Refcard nodes, which have a title and a lot of content, and connected :Author, :Topic, and :Skill nodes.
To create three entries in our database, we would execute this statement:
CREATE ((:Author {name:"Michael Hunger"})
-[:WROTE]->(neo4j:Refcard {title:"Querying Graphs Neo4j"})
-[:FOR_SKILL]->(:Skill {level:1}),
(neo4j)<-[:TAGGED]-(nosql:Topic {name:"NoSQL"}),
(neo4j)<-[:TAGGED]-(:Topic {name:"GraphDB"})
CREATE :Author {name:"Oliver Gierke"})
-[:WROTE]->(springData:Refcard {title:"Core Spring Data"})
-[:FOR_SKILL]->(:Skill {level:2}),
(springData)<-[:TAGGED]-(:Topic {name:"Framework"}),
(springData)<-[:TAGGED]-(nosql)
CREATE (:Author {name:"Alex Baranau"})
-[:WROTE]->(hbase:Refcard {title:"Apache HBase"})
-[:FOR_SKILL]->(:Skill {level:5}),
(hbase)<-[:TAGGED]-(:Topic {name:"Infrastructure"}),
(hbase)<-[:TAGGED]-(nosql)
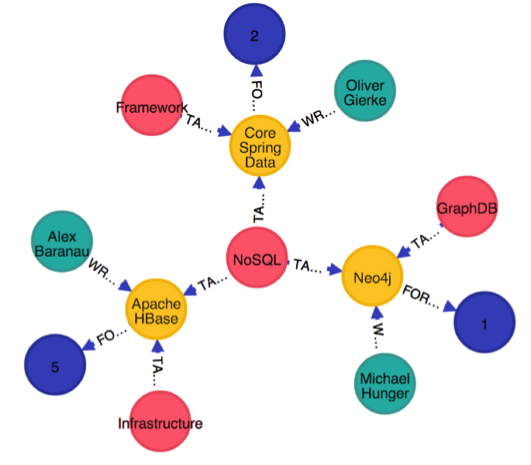
Now we can run a simple query that asks the following question: “I really liked the Core Spring Data Refcard. Matching my reading history and skills, what other Refcardz should I read?”
| Title |
Author |
Score |
Topics |
| Querying Graphs with Neo4j |
Michael Hunger |
1 |
[NoSQL] |
That’s it! Based on your previous reading habits, the database suggests you read the "Querying Graphs with Neo4j" Refcard if you haven’t done so already, because its skill level is similar to that of the Core Spring Data Refcard and it shares a topic: NoSQL.
Explore this example further in one of our live graph gist presentations.