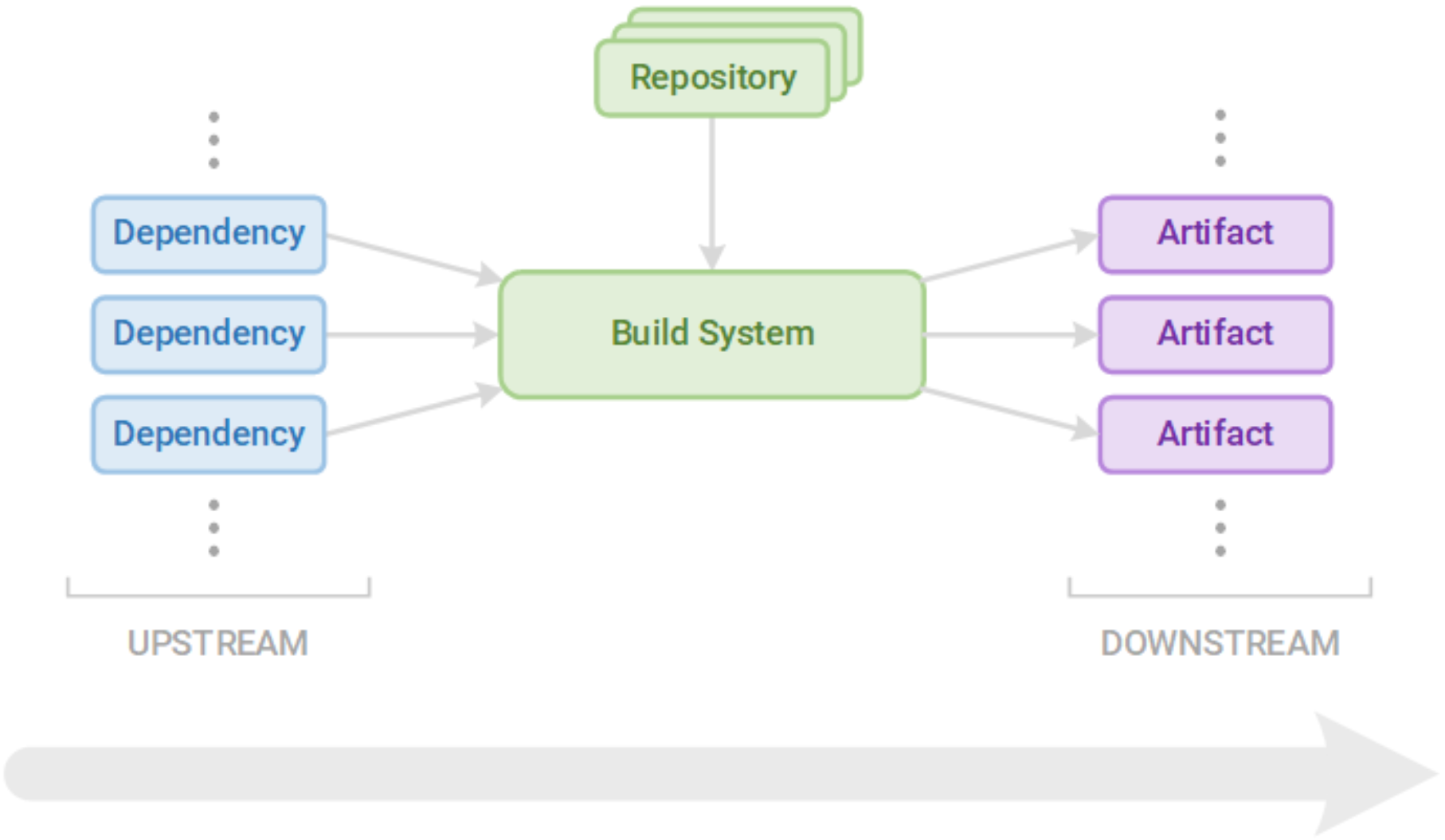
Securing our supply chain — from the dependencies we use to the artifacts we build and publish — centers around creating trust. This trust must be verifiable. In this section, we will dive into how to instill this trust by securing the upstream inputs, build systems, and downstream outputs of our supply chain.
We will use the following key terms throughout this discussion:
- Vulnerability – a software defect that an attacker can exploit to gain undesired access to systems or data and maliciously impact an application
- Remediation – a strategy (e.g., upgrading a dependency) to remove a vulnerability
- Mitigation – a measure that does not remove a vulnerability but ensures our product will never enter a state in which the vulnerability can be exploited
Note: These core practices assume that we are using an automated continuous integration and continuous delivery (CI/CD) pipeline to build and deliver our software. As we will see, automation and logical division of pipeline stages are crucial to establishing verifiable trust in our supply chain.
Upstream Security
Few of our projects are built in isolation. In most modern applications, we use dozens, or even hundreds, of dependencies, all of which can introduce different vulnerabilities and obligations. Open-source code, for example, is ubiquitous in commercial software, present in nearly 100% of code bases. Unfortunately, vulnerabilities, including high-risk vulnerabilities, are also prevalent in commercial open-source code.
Aside from package managers, open-source dependencies can flow through an application via several channels, exposing it to vulnerabilities and potential attack. Common ways that open source can enter an application include:
- Developers manually including files and projects
- Developers copying and pasting source code into their projects
- AI coding assistants
- Coding languages that don't use package managers (e.g., C/C++)
- Third-party libraries
- Container images
Note: Not all dependencies are direct dependencies. There are also transitive dependencies, or dependencies of dependencies. For example, if our application depends on A, A depends on B, and B depends on C, a vulnerability in B or C could create an attack vector, even though we have not directly included B as a dependency. This structure can be composed into a dependency graph using dependencies as nodes (vertices) and dependence as edges.
Figure 2
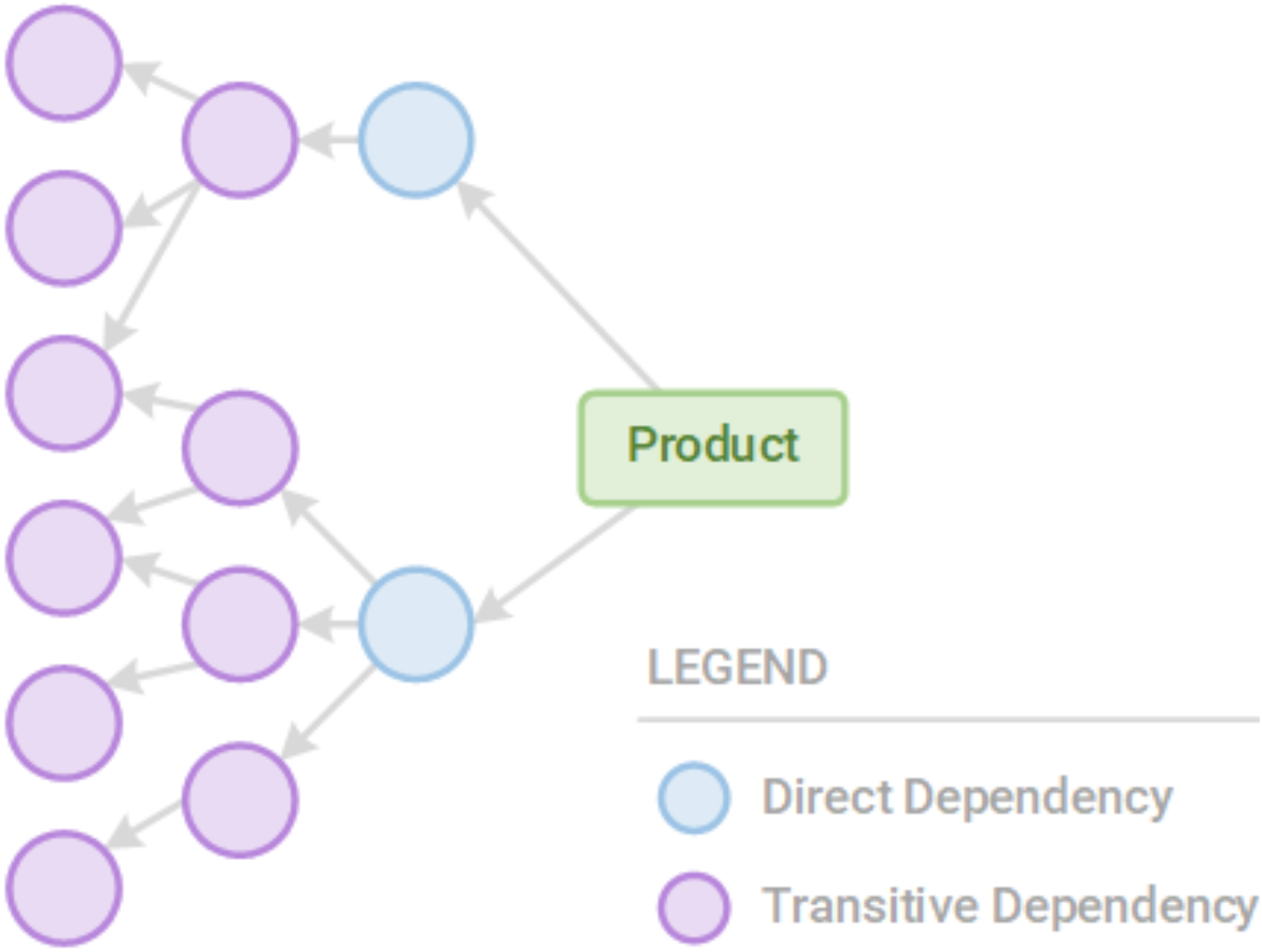
Our products have direct and transitive dependencies that we must secure
There are numerous types of dependencies, including:
- Software artifacts (e.g., Jars, NPM packages)
- Docker images
- Configuration files
- Infrastructure and IT automation configurations (e.g., Ansible configurations)
Dependencies, including transitive dependencies, can also introduce legal obligations through their licenses. We will not expand on those legal obligations in this Refcard, but it is important to understand the licenses of our dependencies and how they may incur legal obligations on our application (e.g., publishing code in a certain manner, forcing our entire product to be open source).
There are four main practices to secure our dependencies:
- Enumerating our dependencies
- Discovering their vulnerabilities
- Verifying the legitimacy of our dependencies
- Remediating their vulnerabilities in a timely manner
Software Bill of Materials
The first step in securing our application against vulnerabilities introduced through our dependencies is understanding what our application depends on. Generating a software bill of materials (SBOM) is the simplest way to enumerate our dependencies. An SBOM is a standardized document that lists all our application's dependencies. This list has the following properties:
- Includes all dependencies in the dependency graph
- Includes each dependency only once
The uniqueness of an entry is determined by its name and version. If two dependencies exist with the same name and same version, only one entry for the dependency is created in the SBOM.
Note: Generating an SBOM does not require a build tool, but utilizing one makes our job significantly easier. Most build tools require us to specify our project dependencies so that they can pull them during compilation. Therefore, most build tools, such as Maven, Gradle, NPM, or PyPi, can easily generate an SBOM from this dependency specification. But if these tools fail to account for any dependencies not introduced by the tool, their SBOMs can be inaccurate and incomplete. Software composition analysis (SCA) tools are commercial options that typically provide a more accurate and complete SBOM.
Currently, there are three main SBOM formats that we can generate:
- Software Package Data Exchange (SPDX) by the Linux Foundation
- CycloneDX by OWASP
- Syft by Anchor
Abiding by standards is important because it allows for different tools — including the vulnerability scanners we will see in the next section — to understand our SBOM and provide useful information, such as vulnerable or outdated dependencies. It also allows users of our artifacts to easily verify our dependencies.
To automatically generate an SBOM, we can add the following tools to our project:
- SPDX contains plugins for Maven and other languages and build systems.
- CycloneDX contains numerous plugins for different build systems, including Maven, Gradle, and NPM.
- Syft generates an SBOM from a Docker container image or a file system.
The correct SBOM generation tool to use will depend on our specific project and build system, but regardless of the tool we select, it is important to generate an SBOM in a standard format so that vulnerability scanners can check if our product includes any vulnerable dependencies.
Recognizing Vulnerabilities
Using our enumerated dependencies, we can now determine which dependencies have known vulnerabilities. Recognizing these vulnerabilities requires us to cross-reference our SBOM against a list of known vulnerabilities. In most cases, vulnerabilities are published as a Common Vulnerabilities and Exposures (CVE) submission — a security bulletin that contains information about a specific vulnerability and which versions of a product are affected. Vendors will often publish a CVE to the CVE system when they recognize that their artifact is vulnerable to exploitation.
Note: The CVE system is maintained by Mitre and made available to the public for free. This CVE database is also made available through the National Vulnerability Database (NVD), which is maintained by the U.S. National Institute of Standards and Technology.
More sophisticated tools can also cross-reference Vulnerability Exploitability eXchange (VEX) reports to provide information about a vulnerability's scope and possible remediations. CVEs, VEXs, and other vulnerability information can provide context and understanding about vulnerabilities that we have inherited from upstream and how we can remediate or mitigate them.
Some third parties provide their own advisories by building on CVEs, adding more in-depth, accurate, and timely vulnerability notices. These can be valuable both in identifying issues that the NVD misses and in helping us to find and fix known vulnerabilities as quickly as possible.
Currently, the most common open-source tools available to perform automatic SBOM verification are Trivy and Grype. There are many other free, open-source, and paid tools available as well. Many of these tools also include vulnerability scanning beyond simple CVE checks, such as automated tools to recognize where a vulnerability exists in our code, automated pull request (PR) generation to remediate the vulnerability, and build system integration.
Note: This process must be part of our automated build process and performed during every build. Every build we launch can contain different dependencies and, therefore, different vulnerabilities. We must check every build to know what vulnerabilities our product has at any given time.
Other tools can directly integrate into our repositories. The benefits of these tools include:
- Integrating natively with our existing repositories and CI/CD pipelines (one-stop view of our code)
- Automating PR creation for remediation
- Tracking vulnerability reduction over time (graphing the number of vulnerabilities in our code over time)
- Removing the need for a standalone SBOM
While creating an SBOM is an important step, some of these repository-native tools do not require a separate SBOM, and instead, they scan our repositories and generate a dependency graph for us. While this removes the need to generate our own SBOM to find vulnerabilities, we should still consider generating one. As we will see later, a standalone SBOM can be useful for third parties that use our artifacts and can provide a simple, human-readable document detailing what our product includes. We may also have legal or contractual obligations to generate and publish an SBOM.
The tools we choose for vulnerability scanning will depend on the specific project and our needs, but the lists above are a good starting place when considering an automated vulnerability scanner.
Note: There are occasions when we recognize a vulnerability or bug in a dependency before others, including the vendor, do. In that case, it is important to file a bug with the vendor or notify the vendor so that a CVE can be filed and a fix can be created as quickly as possible, allowing us to remediate the vulnerability in our product.
Timely Remediation
Once we recognize that a dependency is vulnerable to exploitation, we must quickly remediate the vulnerability. Remediation usually takes one of three forms:
- Upgrading – upgrading a dependency to a version that is not vulnerable
- Mitigation – changing our product to ensure it cannot enter a state where the vulnerability can be exploited
- Removal – removing the dependency entirely
Note: There are times when a dependency has reached end of life (EOL) and is no longer supported. This means that no further updates will be made to the dependency. For dependencies approaching EOL, it is important to have a contingency — or alternative solution — in place. If a vulnerability is found with an EOL dependency, we have a few paths to choose from:
- Use a new dependency that replaces the functionality of the existing one.
- Change our code to not use the dependency's functionality, allowing us to remove the dependency.
- Assume ownership of the dependency's source code, remediate the vulnerability in the source code, and build a new artifact that we can use as an updated dependency.
The speed at which we can apply one of these remediation strategies largely depends on two factors:
- How quickly we can update our source code
- How quickly we can release an updated version of our product
The first factor is usually dictated by the complexity of our code. For example:
- Do we have numerous, tightly coupled dependencies, or is it decoupled, where changes in one component will have a minimal impact on other components?
- Do we keep our code up to date?
- Is our dependency list organized, where we have a central version list that can be updated easily?
Updating our code quickly will depend on how well we write our code and follow best practices for source development. On the other hand, how quickly we can release our updated product will largely depend on how agile and lean our release cycle is. If we have achieved maximal automation and a commit results in a fully tested, automatically delivered artifact, we can easily release a fix for our product that remediates a known, upstream vulnerability. This quick remediation becomes more difficult the more complex and bloated our release process becomes.
Here are some tips that help ensure our remediated product can be released quickly:
- Streamline the release process and remove as much bloat as possible.
- Create an automated CI/CD pipeline for releases.
- Increase automated test coverage and reduce manual testing.
- Shorten official release cycles (ideally, every commit can result in a release).
Even if release cycles cannot be reduced to one release per commit, we should reduce our cycle time as much as possible — a one-month cycle is better than a one-quarter cycle, and a one-week cycle is better than a one-month cycle.
Verifying Legitimacy of Dependencies
Apart from knowing which vulnerabilities we introduce through our dependencies, we must also verify that our dependencies are legitimate. For example, how do we know that the dependencies we include are not imposters of the real dependencies, where the imposter contains malicious code? In practice, this means ensuring the authenticity of a dependency's publisher — verifying that it is not a malicious actor — and that the dependency is untampered after publication.
We do this verification through:
- Verifying the signature of our dependencies and rejecting unsigned or tampered dependencies
- Verifying the certificate for the repository from which we obtain the dependency
We will see the details of how each of these steps works when we discuss how we make our downstream artifacts trustworthy in the "Downstream Security" section, but it suffices to know that both of these steps utilize verifiable cryptographic signatures. If we successfully verify the signatures, we can trust the publisher's authenticity and ensure the artifacts it provides have not been tampered with after publication.
Build Security
Securing the inputs to our product and quickly releasing new versions of our product are core tenants in supply chain security, but if we neglect the security of our build systems, those efforts can be quickly nullified. For example, creating an effective vulnerability scanning and remediation process can be quickly quashed if an attacker gains access to our build systems and disrupts those processes.
Build system security centers around two practices:
- Securing our build pipeline
- Securing our build infrastructure
The goal of securing our build systems is to create a trusted build process. In practice, this means that if we effectively secure our build systems, artifacts produced by these systems can be trusted since they come from a trusted source.
Build Pipeline Security
The first type of build security centers around our CI/CD build pipeline. It may not be obvious at first, but our pipelines have dependencies themselves — compromising these dependencies could cause disclosure of sensitive information or allow vulnerabilities to be injected into the artifacts we build.
In many cases, our code is committed to a public or private repository that can be compromised. Suppose a bad actor gains access to this repository and creates a new branch with an in-repository build configuration that outputs sensitive keys or passwords. In that case, our build system may pick up this commit and execute the compromised build. This attack is called a poisoned pipeline execution (PPE).
Note: Repositories, and the code contained within them, are inputs to our build and should be treated as attack vectors like any other dependency or input. Even if the code is written within our company, or the repository is hosted within a demilitarized zone (DMZ) in our network, it can still be compromised. Therefore, we should treat it with the appropriate level of distrust.
In order to prevent PPE attacks, we should:
- Provide repository access to only those developers who need it.
- Revoke repository access when a developer no longer needs it.
- Require pull requests to be created when a change is made and require reviews of each PR — ideally by two or more developers — before a PR can be merged.
- Minimize the number of secrets and sensitive information exposed to a build by the build system.
- Institute constraints for builds (e.g., manual build triggering) triggered by commits to public repositories.
- Isolate builds that have a higher degree of risk, such as those deriving from public repositories or repositories with large development teams (i.e., higher exposure).
Despite our best efforts, it is possible that our build repositories may become compromised. In that case, it is important that our build system recognizes a PPE attack and halts a build immediately. This can be done by enacting build system monitoring that will recognize when a secret is exposed in an artifact. If such a compromised artifact is generated, the build should immediately fail, and administrators should be alerted to the breach.
Infrastructure Security
The second portion of our build system that must be secured is the build infrastructure. In general, threats to our build infrastructure usually take on one or more of the following forms:
- Human error and negligence
- Unhardened machines or containers
- Insufficient cryptographic security
Human error is an unavoidable part of software development, but there are measures we can take to reduce its likelihood. One of the simplest steps is to remove as much manual intervention as possible. In practice, this means:
- Scripting and automating as much as possible, including build steps, container deployment, and pipeline as code
- Enabling proper and minimal access control lists for all machines and processes that users can access
- Minimizing the number of accounts that can access the build system, including removing inactive accounts and providing access on a need-to-know basis
- Providing only the exact permissions a user needs and no more
While we cannot completely remove human interactions with the build system, each time a human accesses the system, it should be viewed as an opportunity to automate a process. For example, if an administrator logs onto a build machine to make a manual change, we should consider improving our IT automation so that this manual change does not have to be made again.
To harden our build machines, we should also apply core practices for IT security, including:
- Minimizing the attack surface by closing all unnecessary access points and ports
- Routinely penetration testing our systems
- Routinely auditing each user's access to the system
- Continuously updating packages on the build machine using IT automation
- Maintaining lightweight systems (e.g., containers) so that compromised systems can be destroyed quickly and new systems brought up easily
- Backing up data to ensure ransomware and other lock-out attacks can be remediated quickly
Note: This level of security should be applied up and down the entire stack for our build system. For example, if we deploy Docker containers to perform our build, the containers and the host machine must be secured.
Lastly, it is important that we maintain our cryptographic tools on our build systems and treat them as first-class security concerns. Using outdated private keys, invalid certificates, and outdated standards — such as outdated Transport Layer Security (TLS) versions — can result in compromises to our build system. In addition, as we will see shortly, neglecting cryptographic tools can also undermine the trust in our artifacts (through digital signatures) when they are published downstream.
Downstream Security
Apart from securing the inputs to our build and the build itself, we also have an obligation to secure the artifacts we create. We commonly use these artifacts in two non-exclusive ways:
- Deployed to a production environment
- Used as dependencies in further downstream products (inside and outside our team)
In the first case, we deploy the artifacts generated by our build and execute them in a production environment. For example, if we are developing a web service, this could mean deploying our Docker containers into a Kubernetes cluster and ensuring that our service is available to our intranet or the public in general. In this case, we must verify that the artifacts are legitimate and can be trusted before deploying them into our production environment.
In the second case, our artifacts may be used as inputs for another project. For example, we may create Docker images that are used by another project as a parent image in a new image, or we may create Jars that are used by another project as a dependency in a Maven build.
Note: We still have an obligation to secure our artifacts, even if they never leave our team. For example, if we have a build pipeline that creates a Jar, and this Jar is used as an input in another internal pipeline, the Jar may never be used externally. Nonetheless, we are still responsible for diligently providing proof of the Jar's trustworthiness. Failing to do so creates a break in the security of the second project's supply chain, just as it would if any external dependency failed to provide such proof.
In essence, we are obligated to provide the same proof of trustworthiness (called an attestation) to others — even other projects within our own purview — that we expect when using artifacts as dependencies.
In practice, providing downstream security imposes three requirements:
- Signing our artifacts
- Proving the authenticity of our artifact repositories
- Monitoring our production environments
We will also explore some additional considerations that should be addressed to ensure downstream security.
Artifact Signing
Signing our artifact means that we cryptographically certify that the artifact is built from trusted sources and built on trusted build nodes. The process of cryptographic signing is illustrated below:
Figure 3
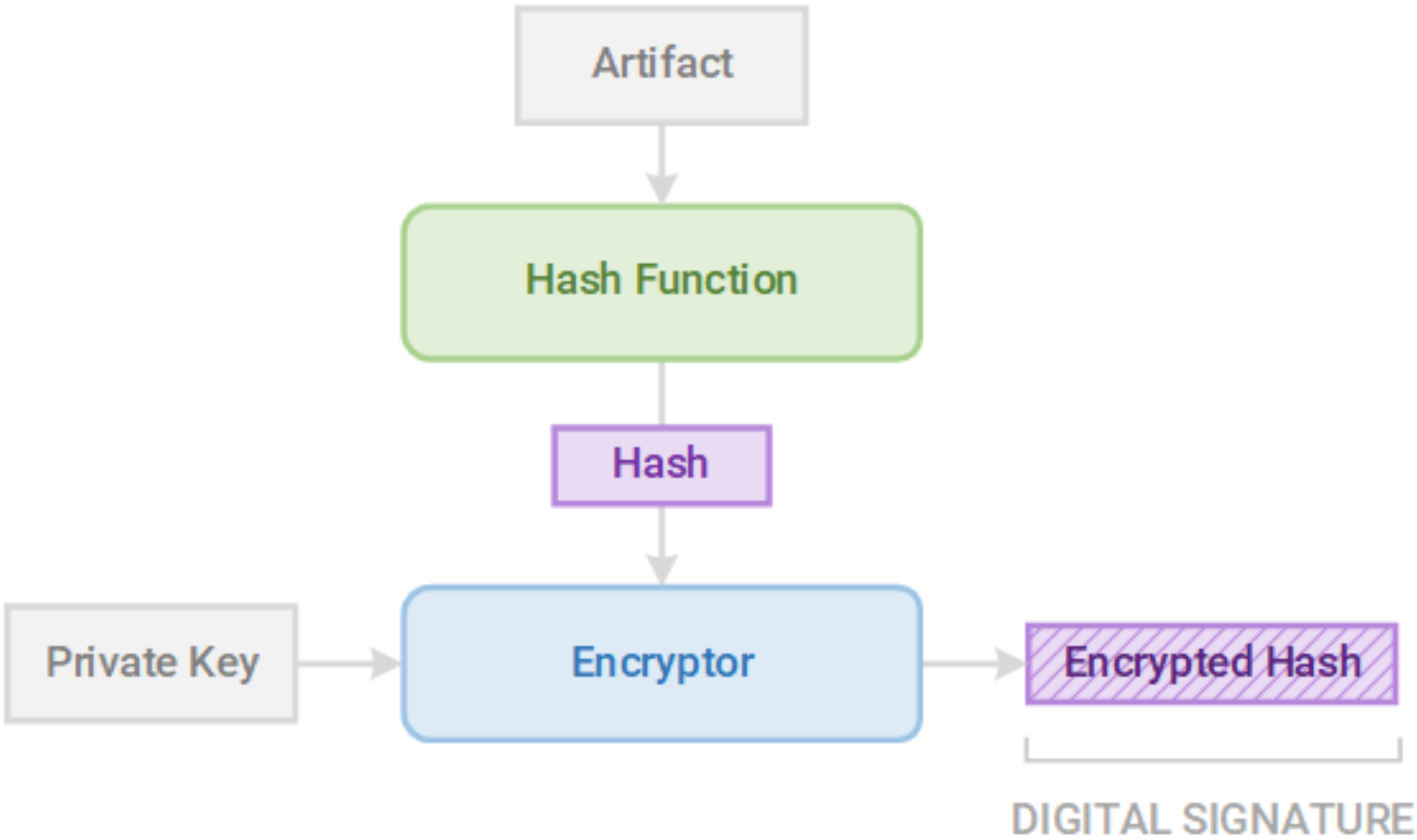
Digital signatures are cryptographic entities created using an artifact hash and a private key
The output of the signing process is a digital signature, which is created by hashing the artifact and encrypting the hash with a private key. We then publish the signature, the corresponding public key, and the artifact. A verifier can then hash the artifact and decrypt the signature using the public key. If the decrypted hash matches the verifier's hash, then the verifier knows that:
- The artifact has not been tampered with after release.
- The artifact was built on a trusted build node that has the private key.
This process ensures both the integrity and authenticity of the artifact and proves that the artifact can be trusted.
Note: This security rests upon the security of the private key. If the private key is compromised in any way, it must be immediately revoked — and a new public key published — to ensure that an attacker cannot act as an imposter. Provided that we properly secure our build nodes (see the "Build Security" section above), artifact signing provides confidence to the downstream user of our artifact, whether ourselves or a third party, that our artifact can be trusted.
Automated signing can be performed by most build systems. For more information, see the following resources:
Artifact Repository Authenticity
While cryptographic signing is crucial in trusting an artifact, we must also prove the authenticity of the repository in which our artifacts are stored. For example, what if the signature is correct for the artifact, but both the artifact and the signature come from an untrusted source? To ensure that the artifact can be trusted, we must prove that the repository in which it is stored can also be trusted.
Trusting an artifact repository and the artifacts that it stores rests upon proving its authenticity. This proof is provided through certificates and the use of protocols that verify these certificates. In practice, this means:
- Our artifact repository should always have a valid certificate.
- The certificate should be signed by a trusted Certificate Authority (CA).
- All access to our artifact repository, such as obtaining artifacts, should be performed through a secure protocol that validates the certificate via TLS (e.g., HTTPS, FTPS).
The second point above is of special importance. There are valid uses for self-signed certificates, but in this case, we should always use a certificate that has been properly signed by a trusted CA whenever possible. This not only removes any warnings when viewing our repository through a browser or other interface, but it also informs our repository users that we have done our due diligence and that our certificate can be trusted all the way back to the root CA.
Lastly, if possible, we should restrict all access to our artifact repository to sufficiently secure protocols. For example, if we allow access to our repository using an older version of TLS, or through protocols that do not include certificate verification (e.g., HTTP), we break the security chain. Even though it is up to the client to ensure that they are using a secure protocol, removing the possibility of such insecure protocols ensures that we eliminate as many points of distrust as possible.
Production Monitoring
In some cases, we deploy our artifacts as working applications. When doing so, we must not only secure the delivery and deployment of our artifacts but also monitor them at runtime. Monitoring includes:
- Frequently updating vulnerable infrastructure to remediate or mitigate vulnerabilities
- Auditing production environments to ensure alignment with our infrastructure's declarative state (e.g., Ansible or Puppet configurations)
- Auditing production infrastructure, including Docker containers, to ensure alignment with its deployment configuration (e.g., Kubernetes configurations)
- Securing the entire stack — from the kernel to the application layer
Note: Production environments should be configured using code whenever possible. Ideally, this configuration is declarative, meaning it declares the desired state of the environment rather than an arbitrary set of steps to alter the environment (e.g., with a shell script). This allows us to compare and audit if our environments match the desired state declared in our configuration files.
If any of these criteria are violated, monitoring tools must immediately alert administrators and isolate the vulnerable or exploited pieces in production. In some cases, automated measures can be taken, such as bringing down exploited containers and replacing them with secured replicas.
Other Considerations
In addition to artifact signing, artifact repository security, and production monitoring, there are other aspects of downstream security that we should consider:
- Legal responsibility – When a vulnerability is exploited, certain parties may be held responsible. Due diligence must be performed and best practices must be adhered to. Failure to do so may result in legal action against the company, its developers, or even its executives.
- Reputational damage – Releasing vulnerable software or failing to fix a known vulnerability may result in damage to a vendor's or brand's reputation, and this damage can last for months, years, or even the life of the vendor.
- Publishing SBOMs – In some cases, we may need to publish our SBOM in a specific format so that other vendors can audit our artifacts and enable traceability downstream. This is often true when publishing artifacts to sensitive markets, such as government, military, medical, or financial industries. It is important to understand our legal and contractual obligations and to ensure that our build system and downstream delivery system abide by them.
- Personal responsibility – Not only are we legally responsible for securing our supply chain, but we are also personally responsible for doing so. Becoming a master of our craft requires that we secure our supply chains because it sets a high personal standard that steers the rest of our work in the right direction.